Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 课程笔记 TiDB 快速起步(上)
Course Certificate

Course Link
Course Outline
-
A Brief History of Databases, Big Data, and TiDB
-
01: History and Trends in Database and Big Data Development
-
02: Development of Distributed Relational Databases
-
03: Evolution of TiDB Products and Open Source Community
-
-
Overview of TiDB
-
04: What Kind of Database Do We Really Need?
-
05: How to Build a Distributed Storage System
-
06: How to Build a Distributed SQL Engine
-
-
Next-Generation HTAP Database Selection
-
07: HTAP Databases Based on Distributed Architecture
-
08: Key Technological Innovations in TiDB
-
09: Typical Application Scenarios and User Cases of TiDB
-
-
First Experience with TiDB
- 10: First Experience with TiDB
Course Notes (Part 1)
-
Understanding database development trends from multiple perspectives such as time, data volume, and architectural evolution
-
Understanding that distributed relational databases are future-oriented databases
-
Intrinsic drivers of database technology development: business growth (data volume), scenario innovation (data model and interaction efficiency), hardware and cloud computing development
-
Database architecture: single node, shared state, distributed
-
RDBMS → NoSQL (Not only SQL) → NewSQL → HTAP
-
Segmentation of data technology and integration of data services
-
Trade-Off (choices and balances)
-
1965, Gordon Moore, the number of transistors on an integrated circuit doubles approximately every 18 months.
-
2006, Google’s GFS, Bigtable, MapReduce
-
Divide and conquer in distributed systems
-
Main challenges of distributed technology
-
How to maximize divide and conquer
-
How to achieve global consistency
-
How to handle fault tolerance and partial failures
-
How to deal with unreliable networks and network partitions
-
-
CAP Theorem
-
C Consistency
-
A Availability
-
P Partition Tolerance
-
-
Relational model and transactions
-
A Atomicity
-
C Consistency
-
I Isolation
-
D Durability
-
-
NewSQL (natively distributed relational database) = distributed system + SQL + transactions
-
2013, Google, Spanner paper, F1 paper
-
2014, Raft paper implementing industrial-grade distributed consistency protocol
-
TiDB, open-source, natively distributed relational database, HTAP
-
Open source: a best path to success for foundational software (tends to be general and standardized)
-
Open source: open source code, open attitude, open source ecosystem governance
-
Designing a distributed relational database
-
Scalability (elastic, write-oriented)
-
Strong consistency, high availability (RPO=0, RTO small enough)
-
Standard SQL supporting ACID transactions
-
Cloud-native
-
HTAP (integration of OLAP and OLTP under massive data, hybrid row-column)
-
Compatibility with mainstream ecosystems and protocols
-
-
Common foundational factors in the data technology stack
-
Data model
-
Data storage and retrieval structure
-
Data format
-
Storage engine
-
Replication protocol
-
Distributed transaction model
-
Data architecture
-
Optimizer algorithm
-
Execution engine
-
Computing engine
-
-
Development of hardware, especially networks, has driven the separation of computing and storage architecture
-
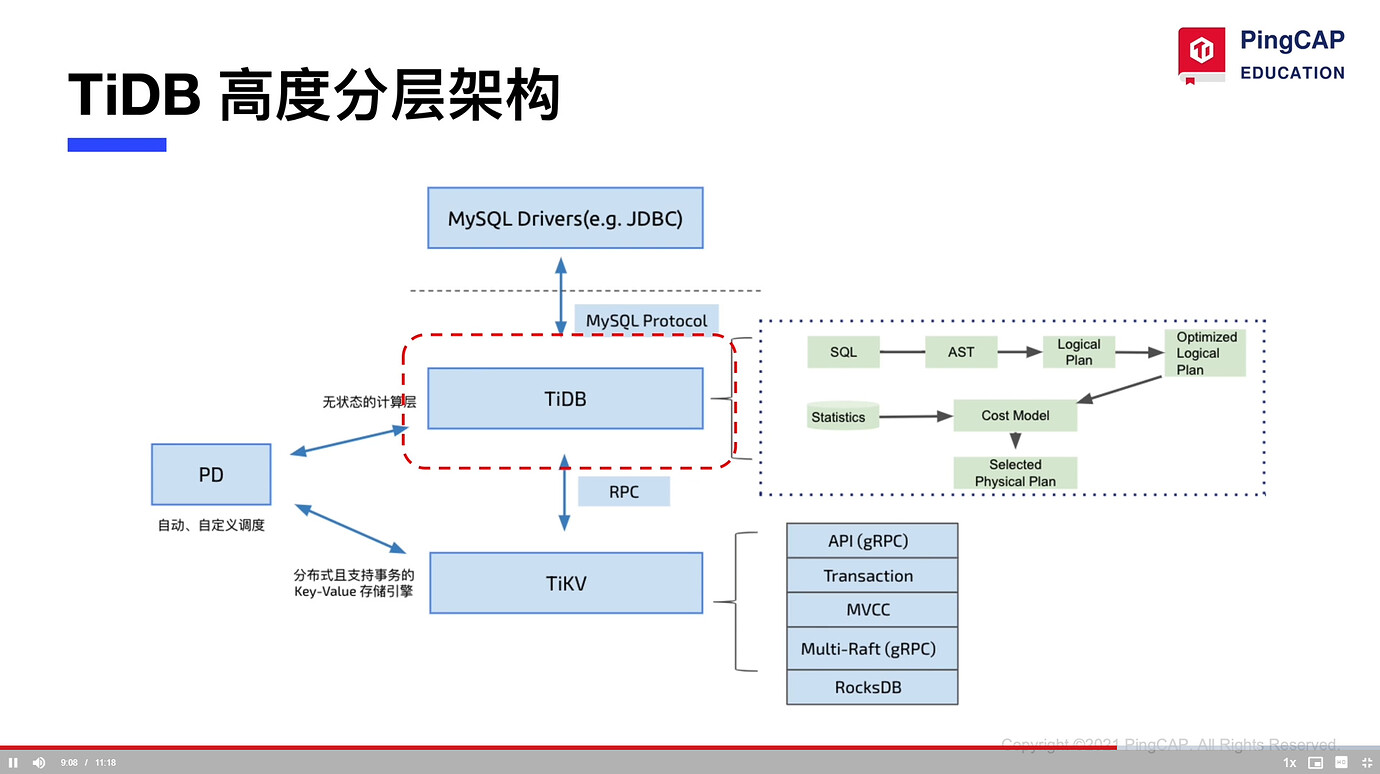
Highly layered architecture of TiDB