Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 课程笔记 TiDB 快速起步(下)
Course Link
Course Outline
-
History of Database, Big Data, and TiDB Development
-
01: History and Trends of Database and Big Data Development
-
02: Development of Distributed Relational Databases
-
03: Evolution of TiDB Products and Open Source Community
-
-
Overview of TiDB
-
04: What Kind of Database Do We Really Need
-
05: How to Build a Distributed Storage System
-
06: How to Build a Distributed SQL Engine
-
-
Selection of Next-Generation HTAP Database
-
07: HTAP Database Based on Distributed Architecture
-
08: Key Technological Innovations of TiDB
-
09: Typical Application Scenarios and User Cases of TiDB
-
-
First Experience with TiDB
- 10: First Experience with TiDB
Course Notes (Part 2)
-
OLTP: Pursues high concurrency and low latency
-
OLAP: Pursues throughput
-
TiDB used for data middle platform
-
Massive storage allows aggregation of multiple data sources, real-time data synchronization
-
Supports standard SQL, quick results from multi-table joins
-
Transparent multi-business modules, supports task dimension queries after table aggregation
-
TiDB’s maximum pushdown mechanism and parallel hash join operators
-
-
Introduce Spark (only provides heavyweight queries with low concurrency) to alleviate the computational power issue of the data middle platform
-
Column storage is naturally friendly to OLAP queries
-
TiFlash connects to multi-raft groups as a raft learner, using asynchronous data transmission, imposing very little burden on TiKV
-
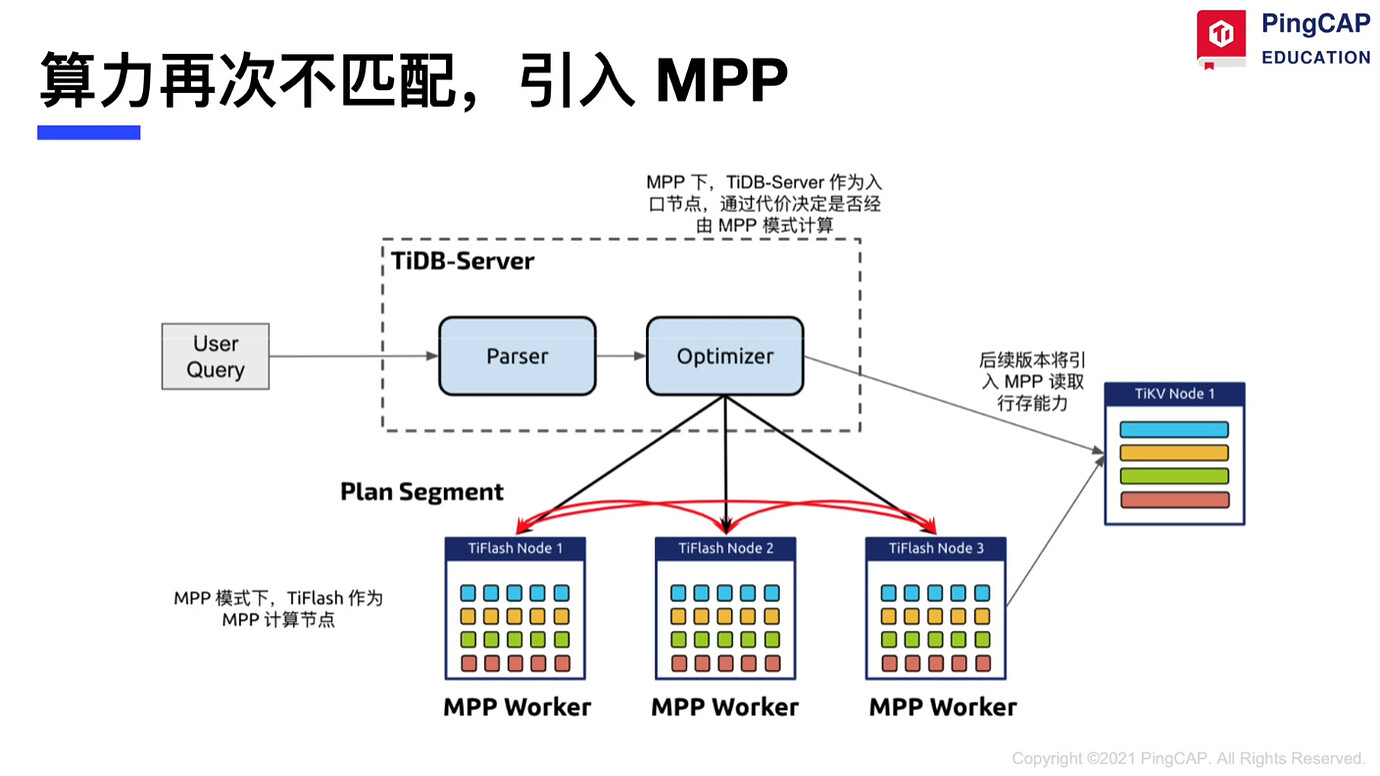
Introduce MPP to address computational power mismatch
-
Replace computing resources with network and storage costs
-
Next steps in HTAP exploration
-
Unified data services
-
Iteration of embedded product functions, completed by specific products for HTAP
-
Integration of multiple technology stacks and products, forming HTAP services through data linkage
-
-
Stages of Data Warehouse
-
Batch processing (ETL) offline data warehouse
-
Lambda architecture combining batch and stream processing
-
Kappa architecture focusing on stream processing
-
-
Distributed KV storage system
-
Distributed SQL computing system
-
Distributed HTAP architecture system
-
Automatic sharding technology as the basis for finer-grained elasticity
-
Elastic sharding builds a dynamic system
-
96MB auto-increment sharding
-
20MB merged sharding
-
-
More discrete replication groups based on multi-raft
-
Linear write scalability based on multi-raft
-
Cross-IDC multi-node writes for single tables based on multi-raft
-
Decentralized distributed transactions
-
Local read and geo-partition
-
TP and AP integration under larger data capacity
-
Unified data services: TiDB’s CBO can collect row and column cost models for configuration
-
Typical scenarios
-
OLTP Scale High scalability online (high concurrency, large data volume, high availability)
-
Real-time HTAP
-
-
Sharding, database splitting, middleware Proxy
-
Performance degradation and B-tree due to oversized tables
-
TiUP is a cluster operation and maintenance tool introduced in TiDB 4.0
-
TiUP’s playground component is used to deploy local clusters