Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: k8s tidb运行期间CrashLoopBackOff
K8s deployment mode
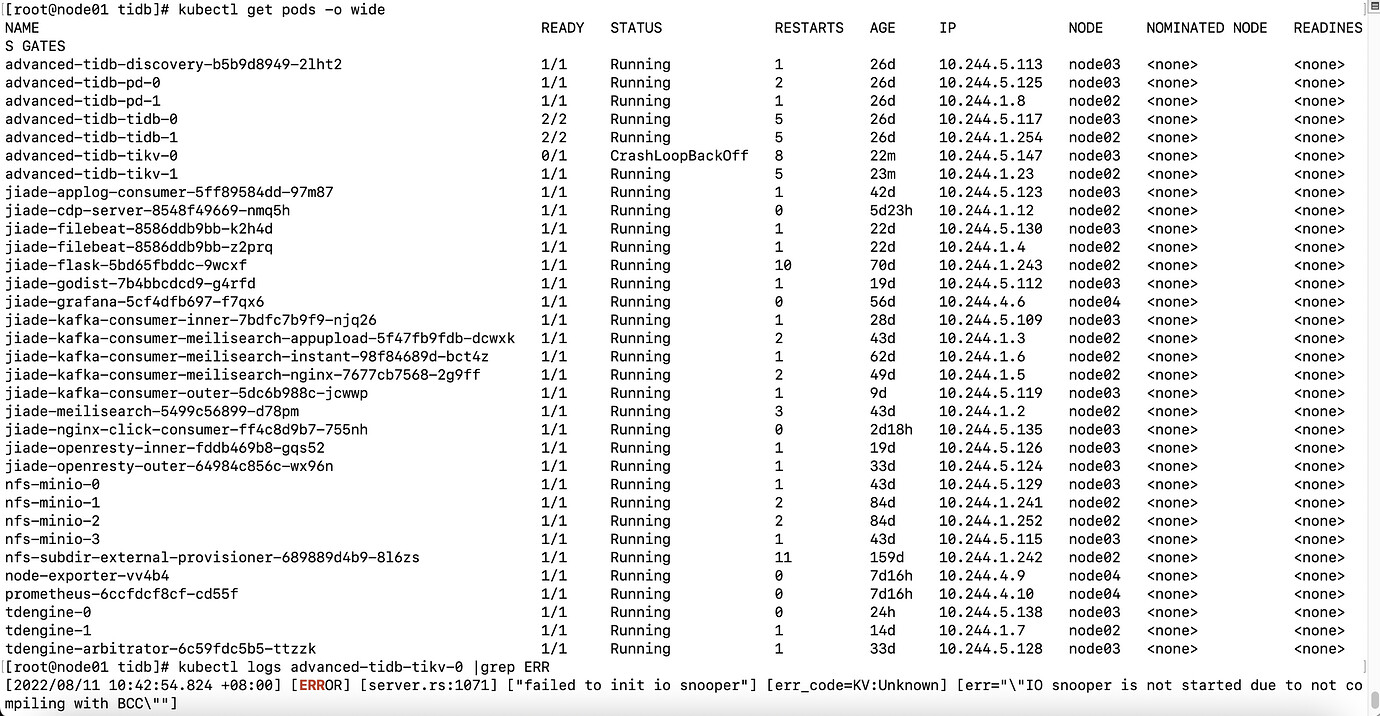
TiKV will enter CrashLoopBackOff after running for a period of time. Check the logs as shown in the picture:
There are only 2 TiKV? Don’t grep for errors, just post all the logs directly.
Check if there is an issue with the PV.
I have uploaded all the logs. Please help me take a look.
tikv0.log (35.8 MB)
It should be fine if they are all bound, right?
Looking at some of your logs, there doesn’t seem to be any issue. You can check the disk space or expand to 3 KV.
How many replicas are you using?
I forgot, once it restarts, you can’t see the logs anymore. So the logs you sent are only from the last startup, not why the previous one ended.
kubectl describe pod xxx -n xxx
Can you see anything this way?
It seems to be OOMKilled. Is the memory I allocated to TiKV too small? It is currently 2G.
Disk space is ample; it seems to be a memory limitation issue.
Adjust a request and try again.
Modify the TiKV settings in the configuration file to ensure sufficient memory for Kubernetes.
Oh, I see. Let me adjust it.
The memory limit of a POD is controlled by limits, not requests. (requests are the minimum resource requirements for a POD to be scheduled onto a node)
2GB is too small, allocating more won’t hurt. 2GB can easily run out of memory. Go for 16GB or 32GB.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.