Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 严重问题~~~tidb集群升级到6.5.3出现写入缓慢,leader反复平衡问题
[TiDB Usage Environment] Production Environment
[TiDB Version] Upgraded from 6.1.5 to 6.5.3
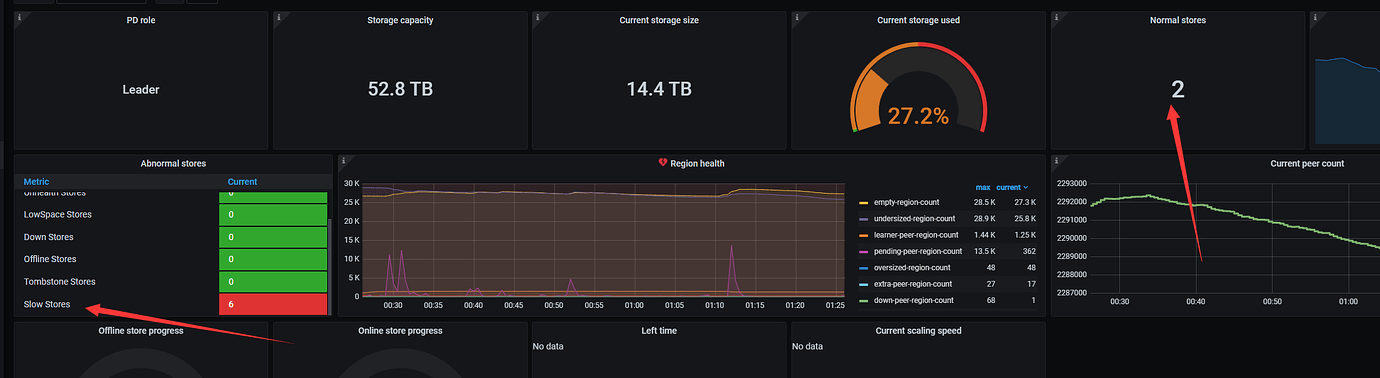
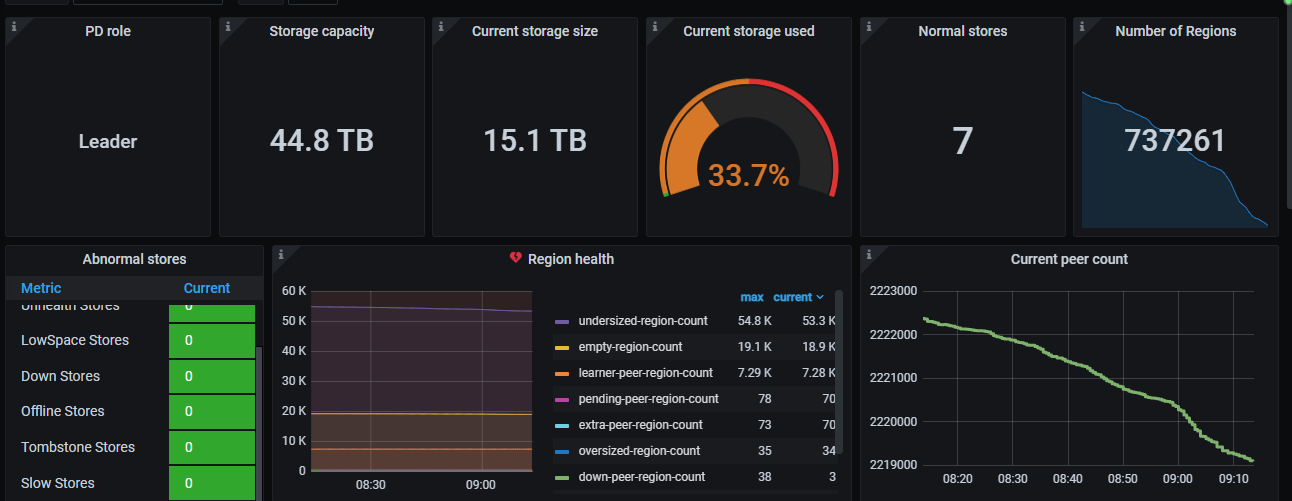
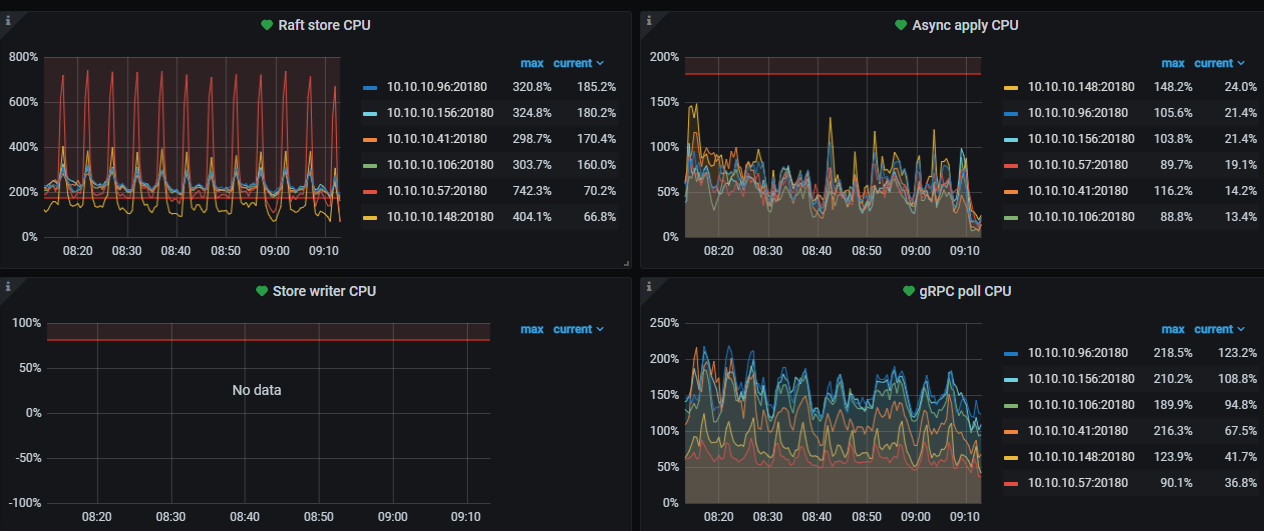
After the upgrade, the kv nodes have a score of 100, and all are slow stores.
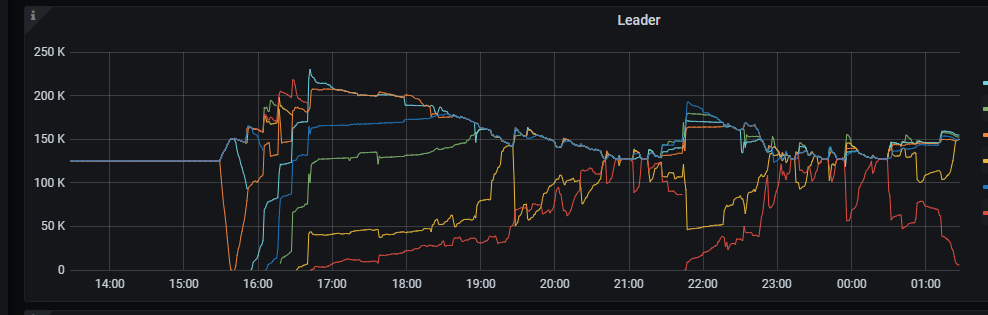
Leaders appear
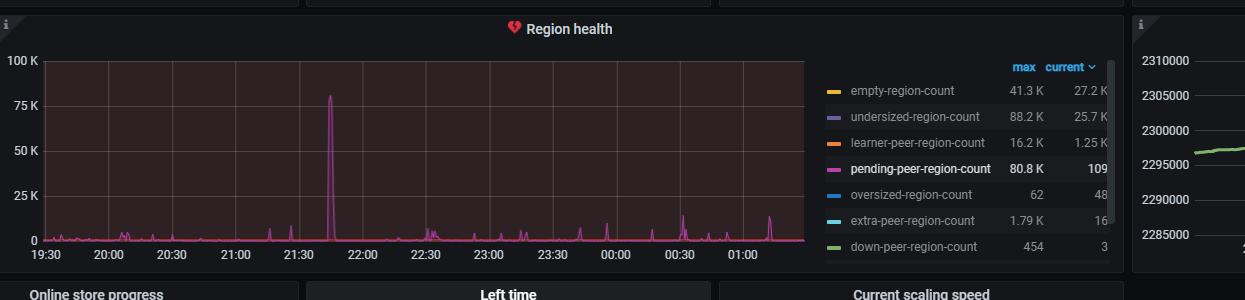
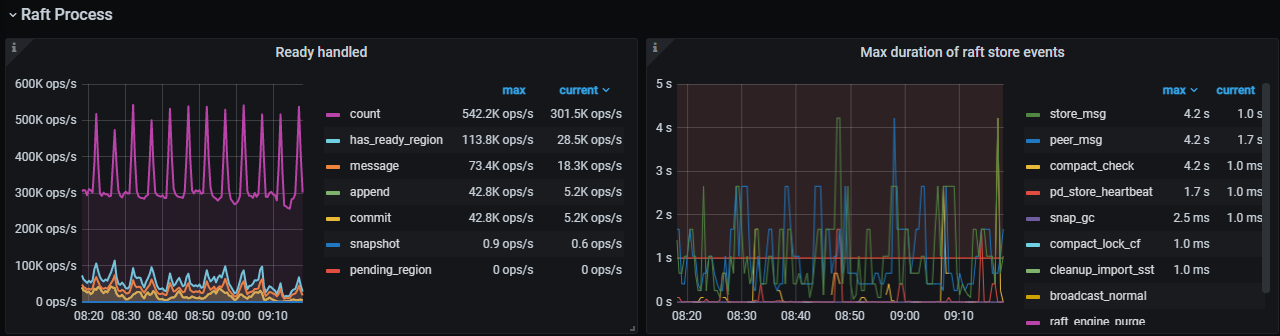
PD monitoring periodically shows pending-peer-region-count, followed by a decrease in the number of leaders.
Do you have any troubleshooting directions? It’s a production environment, and it’s quite urgent…~
Check the logs to see if there are any anomalies.
Generally, it is caused by a failure in a certain region leading to load imbalance or data inconsistency. The approach is to check if the PD cluster is functioning normally and ensure there are no errors in the PD logs. Check the TiKV instance logs to see if there is any information about delays and errors. Then use pd-ctl operator to check.
Currently, the following operations have been performed:
- Set the weight leader of two stores to 0.
- Adjust the
raftstore.store-pool-size parameter to 8.
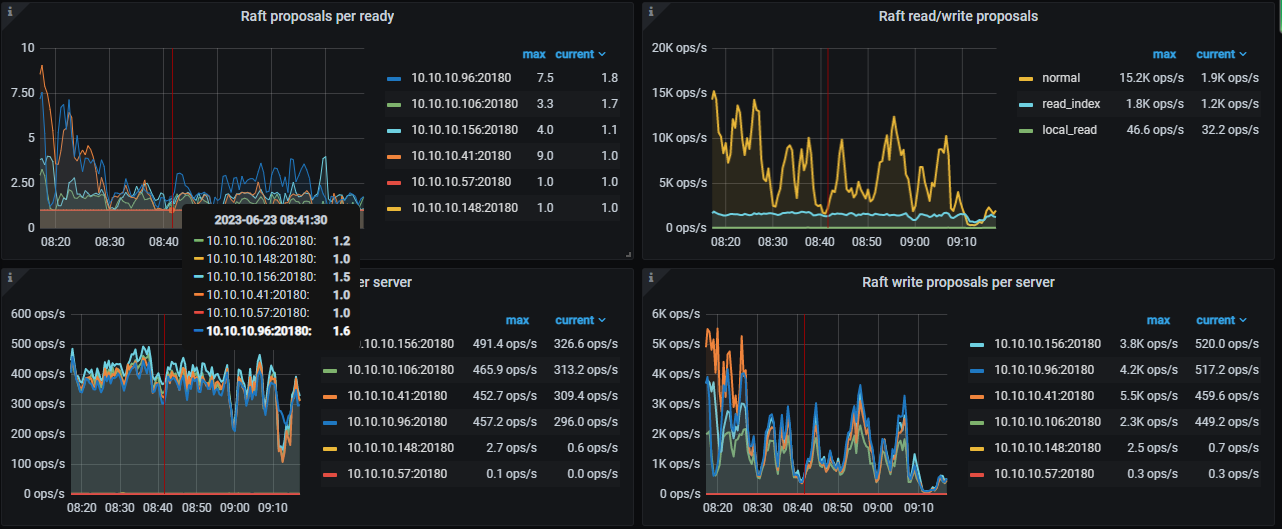
The slow store issue has disappeared, but the raftstore CPU fluctuates significantly, and the cluster’s write speed has noticeably decreased. How should I troubleshoot this issue?
Try increasing the raftstore.inspect-interval parameter. It’s the detection frequency for slow stores, default is 500ms. Adjust it to 10 minutes and see. The monitoring shows a large number of empty regions, which might affect performance during the merging process.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.