Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 数据已导入成功,但是最后报了error
【TiDB Usage Environment】Production\Testing Environment\POC
【TiDB Version】
【Encountered Issue】
【Reproduction Path】
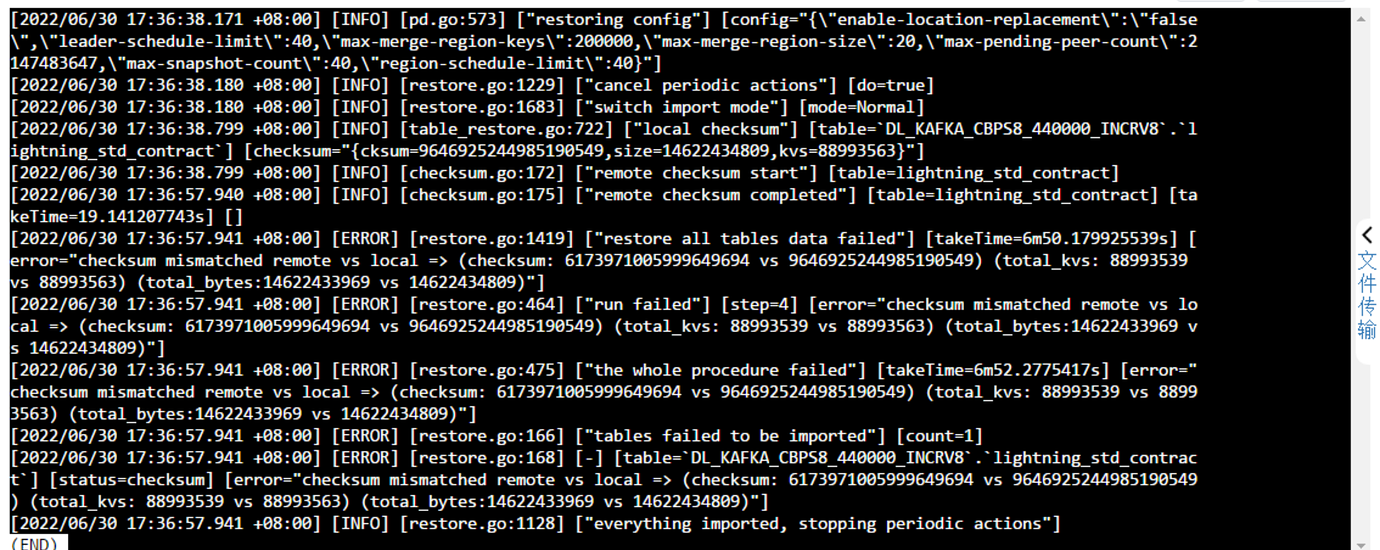
Using version 5.4 of Lightning to import CSV files into the TiDB database, an error was reported at the end, but I checked the database and the data was successfully imported.
【Issue Phenomenon and Impact】
【Attachments】
- Relevant logs, configuration files, Grafana monitoring (https://metricstool.pingcap.com/)
- TiUP Cluster Display information
- TiUP Cluster Edit config information
- TiDB-Overview monitoring
- Corresponding module Grafana monitoring (if any, such as BR, TiDB-binlog, TiCDC, etc.)
- Corresponding module logs (including logs one hour before and after the issue)
There are warnings about duplicate keys in the logs.
The import was successful. I encountered errors when using mysqldump for the import, so I used the -f option to force the import.
So what exactly is this error?
However, there is indeed a problem of missing data. The number of lines counted using “wc -l file path” on Linux differs from the number of lines imported into the TiDB cluster. The number of lines counted by wc is greater than the number of rows in the database.
What is set by on-duplicate? Is there a strict mode setting?
Can you share the configuration file of tidb-lightning?
The on-duplicate parameter was not set, so it should be the default value.
Strict mode should be set.
Then confirm the data format of the CSV file. I have encountered situations before where issues with the CSV file’s data format led to inconsistencies in the imported data.
It’s really hard to sort out tens of millions of data with only a few dozen differences. 
Hello, is the backend local?
If it is local, checksum mismatch means data inconsistency. Generally, this happens when there is data in the table before importing, or if the process fails midway and there is no breakpoint resume or the table is not cleared. In this case, the best method is to clear the table and re-import.
Currently, Lightning has pre-checks (starting from version 5.3). If the increment mode is not set, the table cannot have data; if there is data, it will report an error directly before importing. So, it is generally not due to this reason.
Additionally, a checksum mismatch indicates that some errors occurred during the import process (most likely due to duplicate data). Although there is data in the table, since this data is inconsistent with the data you want to import, it is still better to understand it as an import failure.
You can refer to this document to solve your problem: TiDB Lightning 错误处理功能 | PingCAP 文档中心
There is a way to help locate inconsistent data.
You can import the same CSV data into MySQL and check if the number of imported records is the same.
Then use sync-diff-inspector to compare the consistency of the data between the MySQL table and the TiDB table. This tool will list inconsistent data and counts, etc.
For more details, refer to: sync-diff-inspector 用户文档 | PingCAP 文档中心
It’s local, and the number of data entries is different, so the data must be different. The main issue is that the data is too large to compare entry by entry.
If the impact is minimal, just leave it. If the impact is significant, re-import it.
First, repeatedly import select distinct into the new table.
First, import using “SELECT DISTINCT INTO” a new table. This way, you can ignore duplicate data in just two steps.
This topic was automatically closed 1 minute after the last reply. No new replies are allowed.