Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: Deadlock found when trying to get lock
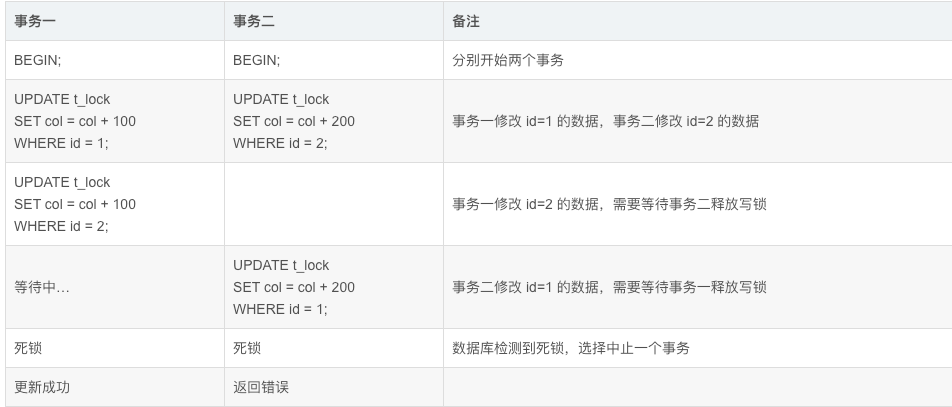
TiDB version 5.1, there is a table A with fields such as user id (int), date (date), game version id (int), batch number (varchar2), amount (decimal), etc. The table has two normal composite indexes (no unique indexes, user id + date and date + game version id). Table A will be queried, added, and updated (no delete operations). In the Flink stream job, user id has been grouped to ensure that the same user id will only go to one slot (user id + date + game version id + batch number, table record is unique), and transaction_isolation is set to ‘READ-COMMITTED’ (default is REPEATABLE READ), but deadlock errors (Deadlock found when trying to get lock) often occur. I don’t understand the cause and how to solve it.
PS: Deadlock detection and retry are performed on the business side, which does not affect the business, but I want to understand the root cause and how to handle it.
PS: In a transaction, there will be 2 statements for one record, one for inserting if not exists, and one for updating. Every 100 records (200 statements) commit a transaction.
insert into A select xx from dual where not exists (select 1 from A where user id=xx and date=xx and game version=xx and batch number=xx);
update A set amount=amount+xx where user id=xx and date=xx and game version=xx and batch number=xx;