Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 11亿表的数据删除数据越删越慢
[TiDB Usage Environment] Production Environment
When deleting around 600 million out of 1.1 billion records in a table using the following SQL, the deletion statement becomes very slow, taking more than 3 seconds to execute, whereas initially it took only 0.5 seconds. I searched the forum and found no solutions, nor have I modified the GC time. I personally feel that the previously deleted data has not been GC’d, causing the current deletions to scan a lot of data.
Executing SQL:
EXPLAIN analyze DELETE from h_equip_bin_box_status_history where gmt_create < '2023-07-01 00:00:00' limit 10000
Execution Plan:
Delete_5 N/A 0 root time:3.44s, loops:1 N/A 172.7 KB N/A
└─Limit_9 10000.00 10000 root time:3.34s, loops:11 offset:0, count:10000 N/A N/A
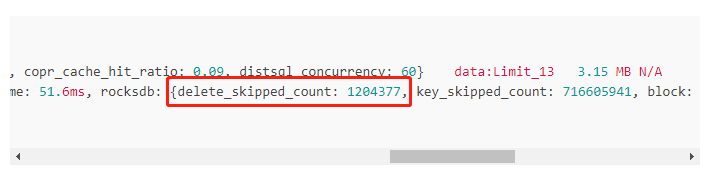
└─TableReader_14 10000.00 10000 root time:3.34s, loops:10, cop_task: {num: 645, max: 654.6ms, min: 440.1µs, avg: 300.1ms, p95: 505.5ms, max_proc_keys: 992, p95_proc_keys: 224, tot_proc: 3m12.2s, tot_wait: 621ms, rpc_num: 645, rpc_time: 3m13.6s, copr_cache_hit_ratio: 0.09, distsql_concurrency: 60} data:Limit_13 3.15 MB N/A
└─Limit_13 10000.00 10208 cop[tikv] tikv_task:{proc max:767ms, min:1ms, avg: 327ms, p80:392ms, p95:504ms, iters:720, tasks:645}, scan_detail: {total_process_keys: 10208, total_process_keys_size: 1321747, total_keys: 715402150, get_snapshot_time: 51.6ms, rocksdb: {delete_skipped_count: 1204377, key_skipped_count: 716605941, block: {cache_hit_count: 1022827, read_count: 924, read_byte: 55.0 MB, read_time: 36.8ms}}} offset:0, count:10000 N/A N/A
└─Selection_12 10000.00 10208 cop[tikv] tikv_task:{proc max:767ms, min:1ms, avg: 327ms, p80:392ms, p95:504ms, iters:720, tasks:645} lt(lyzhhw4.h_equip_bin_box_status_history.gmt_create, 2023-07-01 00:00:00.000000) N/A N/A
└─TableFullScan_11 12383.59 10208 cop[tikv] table:h_equip_bin_box_status_history tikv_task:{proc max:767ms, min:0s, avg: 327ms, p80:392ms, p95:504ms, iters:720, tasks:645} keep order:false N/A N/A