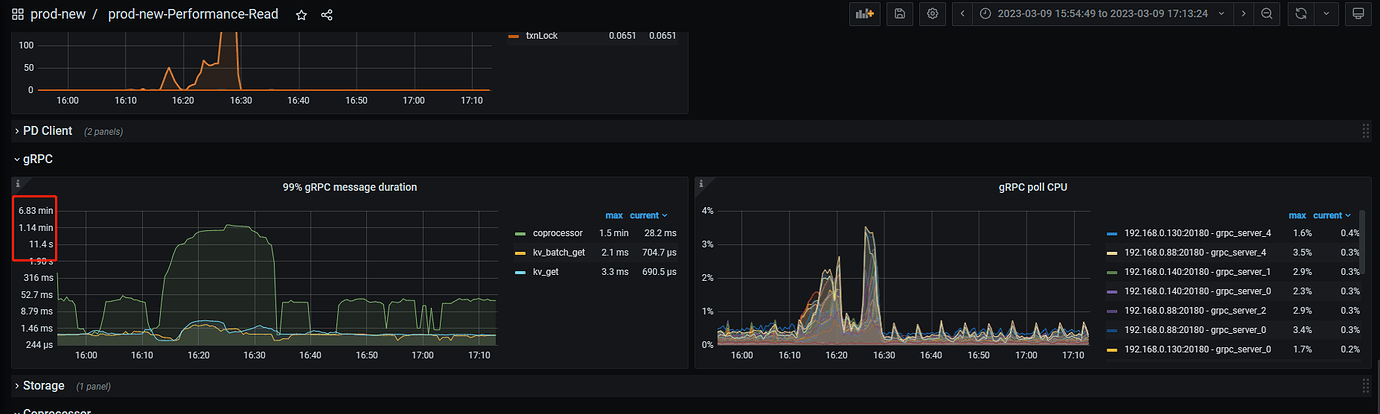
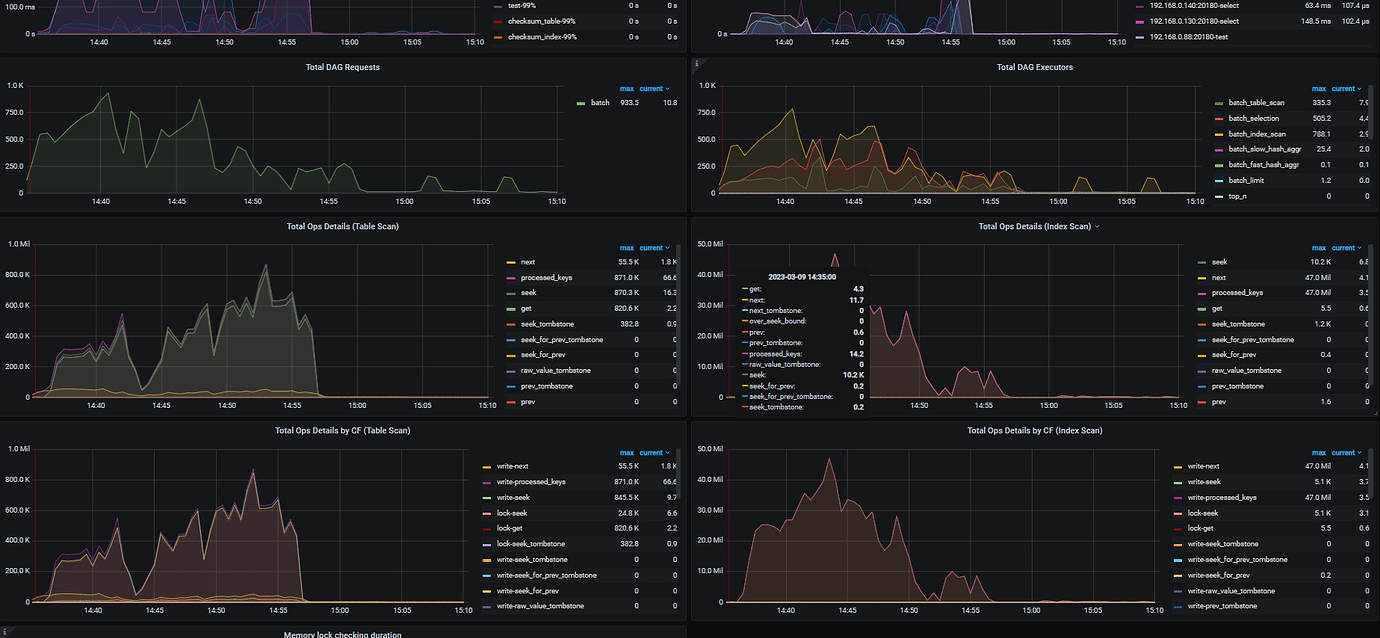
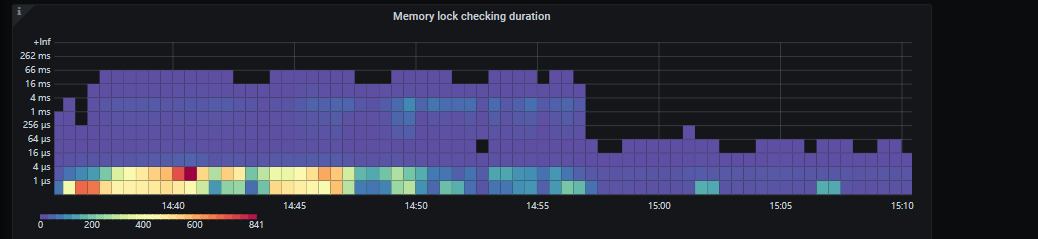
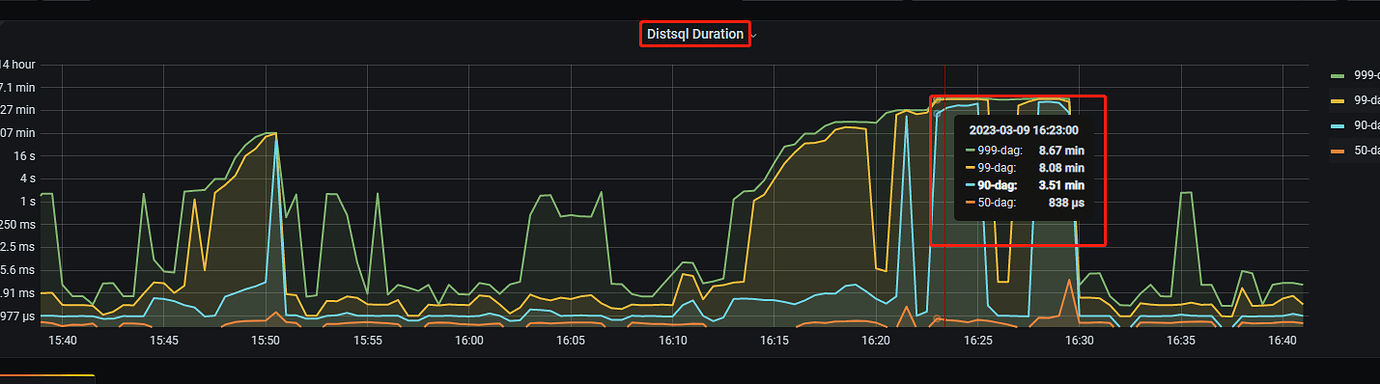
Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: Distsql Duration 执行时间很长
【TiDB Usage Environment】Production Environment
【TiDB Version】v6.5.0
【Reproduction Path】
The SQL statement is as follows:
SELECT
r.`room_id`,
t.`room_name`,
t.`priority`,
t.`creator`,
t.`queue_size`,
t.`description`,
t.`speak_limit`
FROM
`t_room_member` r
INNER JOIN `t_room_info` t ON r.`room_id` = t.`room_id`
WHERE
r.`member_id` = ?
AND r.`room_id` > ?
AND t.`delete_time` = 0
ORDER BY
r.`room_id`
LIMIT
? [arguments: ("20000001142001", "", 500)]
DROP TABLE IF EXISTS `t_room_info`;
CREATE TABLE `t_room_info` (
`id` bigint(20) NOT NULL /*T![auto_rand] AUTO_RANDOM(5) */,
`room_id` varchar(32) NOT NULL,
`room_name` varchar(32) NOT NULL,
`priority` int(11) NOT NULL,
`creator` varchar(32) NOT NULL,
`queue_size` int(11) NOT NULL,
`description` text NOT NULL,
`create_time` bigint(20) NOT NULL,
`rorg_id` varchar(32) NOT NULL,
`delete_time` bigint(20) NOT NULL,
`speak_limit` int(11) NOT NULL DEFAULT '120',
PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */,
UNIQUE KEY `idx_room_id` (`room_id`),
KEY `idx_room_creator` (`creator`),
KEY `idx_rorg_id_room_id` (`rorg_id`,`room_id`),
KEY `idx_rorg_id_create_time` (`rorg_id`,`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin /*T![auto_rand_base] AUTO_RANDOM_BASE=570001 */;
DROP TABLE IF EXISTS `t_room_member`;
CREATE TABLE `t_room_member` (
`id` bigint(20) NOT NULL /*T![auto_rand] AUTO_RANDOM(5) */,
`room_id` varchar(32) NOT NULL,
`member_id` varchar(32) NOT NULL,
`priority` int(11) NOT NULL,
`create_time` bigint(20) NOT NULL,
`speak_limit` int(11) NOT NULL,
`rorg_id` varchar(32) NOT NULL,
PRIMARY KEY (`id`) /*T![clustered_index] CLUSTERED */,
KEY `idx_member_id` (`member_id`),
UNIQUE KEY `index_roomID_userID` (`room_id`,`member_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin /*T![auto_rand_base] AUTO_RANDOM_BASE=280388601 */;
The usage statement is as follows:
【Resource Configuration】
CPU: 16 cores, Memory: 128G, Disk: 20T
All TiDB configurations are installed by default using tiup