Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: dm错误38008
[TiDB Usage Environment] Production Environment / Testing / Poc
[TiDB Version]
[Reproduction Path] What operations were performed when the issue occurred
[Encountered Issue: Problem Phenomenon and Impact]
[Resource Configuration]
[Attachment: Screenshot / Log / Monitoring]
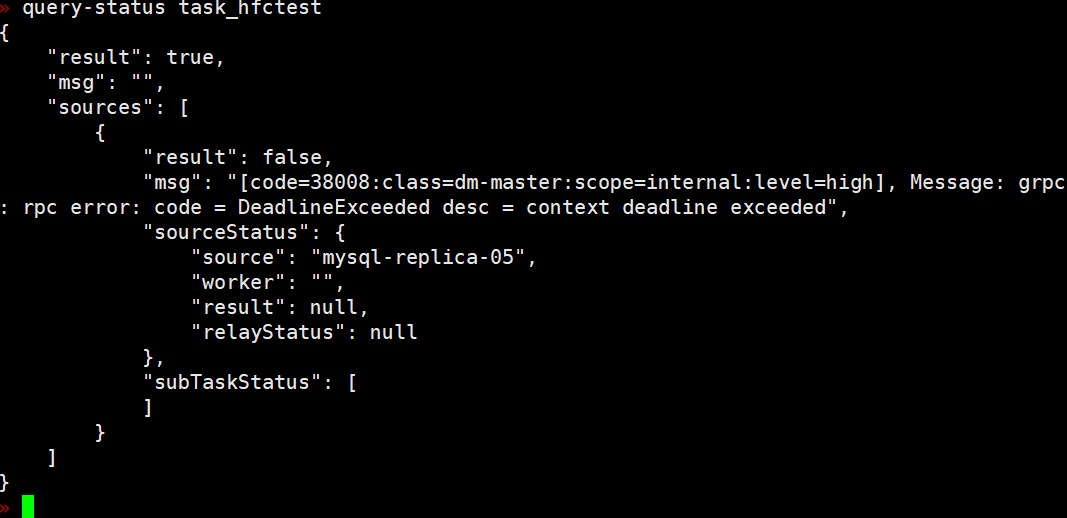
Here it comes, here it comes, a new issue has appeared again.
Error in gRPC communication between DM components, error.DM-dm-master-38008
What should I do when encountering this kind of error? The task required by the customer is on this worker.
Is there no problem with the upstream and downstream networks?
A very important point is that when this error is reported, I don’t know which machine it is. How can I determine if there is a problem? I can only check each machine one by one.
I have already resolved this issue.
However, there is still no rational solution.
The DM component cannot effectively control memory usage during synchronization, resulting in a high memory limit for a single worker, eventually leading to a semi-dead state. Manually killing the thread and restarting the worker is required.
Sure enough, it’s a node communication issue… Restarting works wonders.
But a very important issue is that besides the problem, I don’t know which node it is. Do you understand what I mean?
It’s exhausting to check each one individually…
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.