Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: DM最近总是卡住,不报异常,就是一直卡住
【TiDB Usage Environment】Production Environment
【TiDB Version】v5.1.2
【DM Version】v5.3.0
【Encountered Problem】Collecting MySQL data to TiDB through DM. Recently, it always gets stuck without reporting any exceptions, just keeps getting stuck.
This problem has been occurring frequently in the past few days. Each time it happens, the database in TiDB is deleted and then re-collected using start-task --remove-meta.
Questions:
- How to know what statement is currently being executed?
- How to avoid this situation?
The current synchronization is basically unusable, this is a production environment, please help.
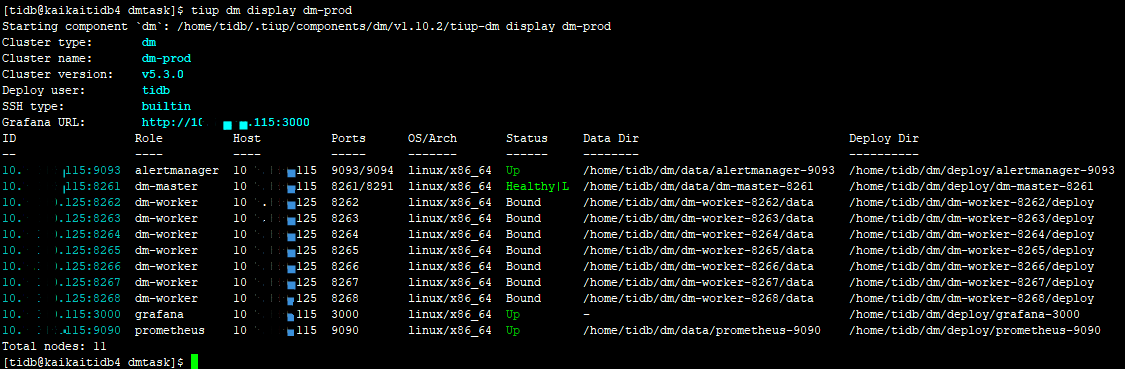
DM Logs:
dm-worker_stderr.log (1.1 MB) dm-worker_stdout.log (351.1 KB)
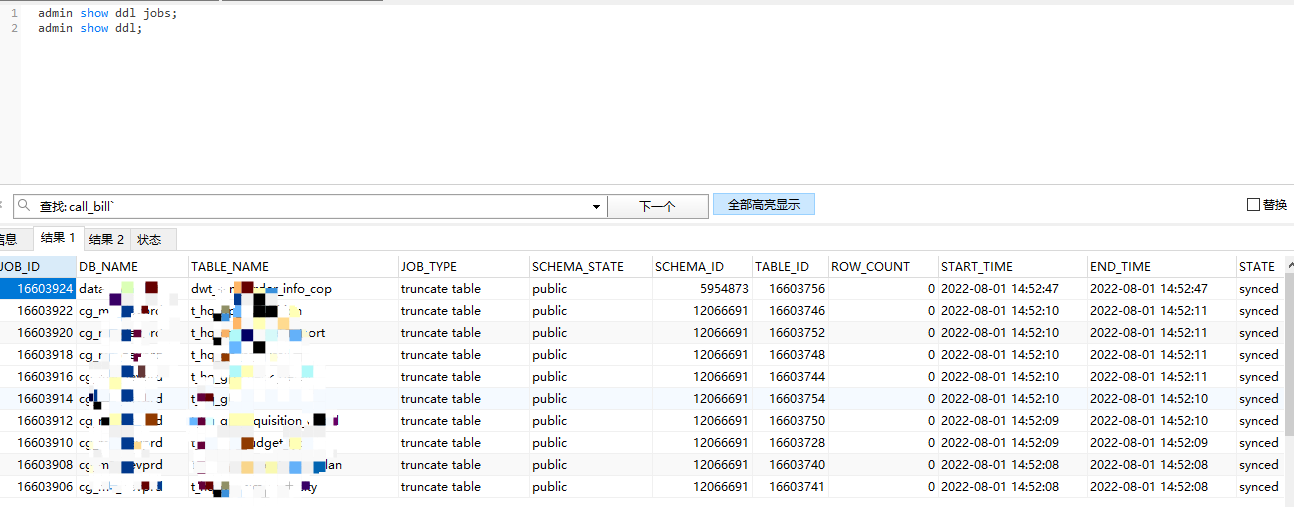
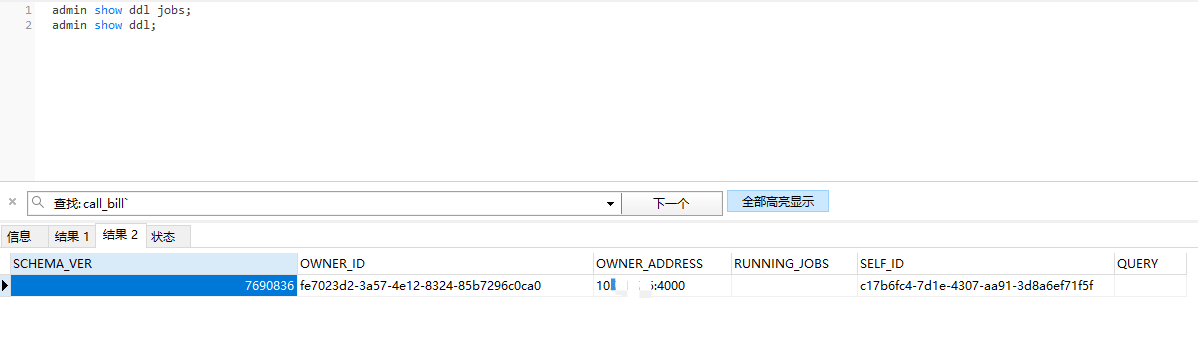
Check if there are any DDL operations being executed.
Hello, how can I determine if there is a DDL execution?
View ongoing DDL
admin show ddl jobs;
admin show ddl;
The logs show frequent disconnections. I suggest checking the network to see if there are any timeouts or other issues.
Currently, TiDB is being used very frequently. Some jobs are constantly organizing data, deleting and recreating tables, and importing data. However, this part involves other schemas, not the schema synchronized with MySQL. There are also many queries.
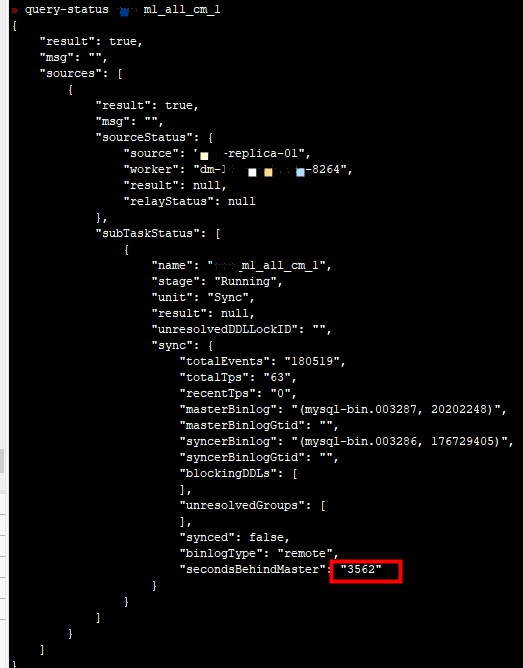
The lag time has been continuously increasing compared to the screenshot above. This time, the site has been preserved without re-collecting data.
Is there any command to know where the lag is occurring?
Isn’t there still an issue with the dm-worker.log? Take it out and have a look.
FYI: panic when executeBatchJobs meet error · Issue #4317 · pingcap/tiflow · GitHub
From the stderr, it looks quite similar to this issue (but it won’t panic after the fix). The reason is that executing the SQL takes too long, and from the log, you can see there are many timeouts. It is suspected that the heavy workload on the downstream is affecting the efficiency of the migration execution of SQL.
@Hacker007 @buchuitoudegou Thank you both for your replies!
Yesterday, I found that within the same data source, there were two tasks targeting the same MySQL source and analyzing into two databases in TiDB, which might have affected each other.
Now the adjustment is: I created a new identical data source and then migrated one of the tasks to the new data source.
Result: After observing for a day today, I haven’t noticed any stalling issues. We’ll continue to monitor this in the future.
This topic will be automatically closed 60 days after the last reply. No new replies are allowed.