Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: DM同步了两个月时间,突然master节点down掉了,翻看报错信息
The memory, CPU, and disk usage were not high at that time. Can any experts help take a look?
Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: DM同步了两个月时间,突然master节点down掉了,翻看报错信息
The memory, CPU, and disk usage were not high at that time. Can any experts help take a look?
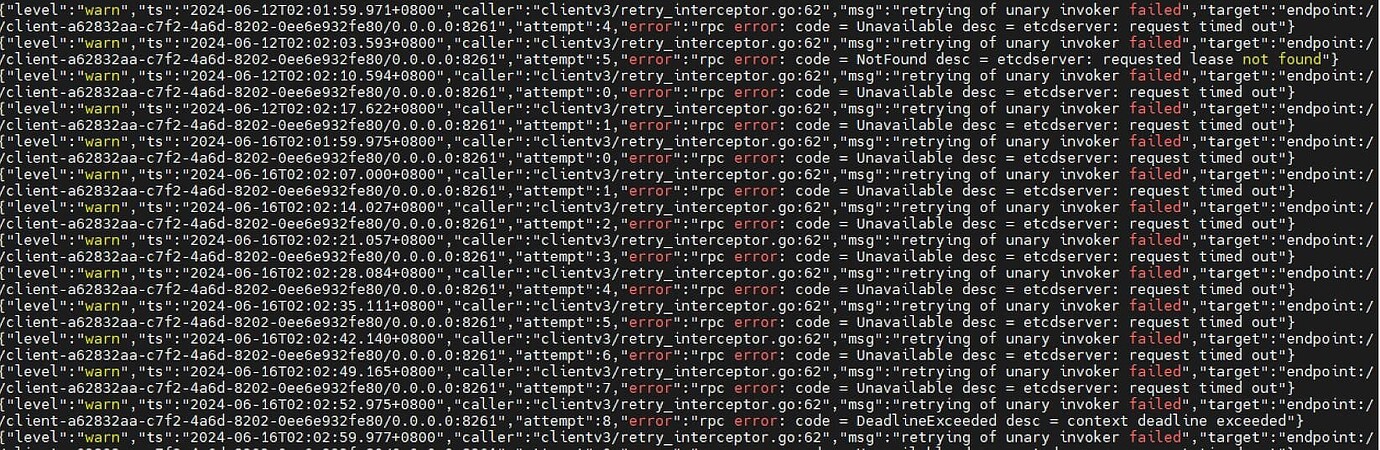
Errors started occurring at 2 AM on June 16th.
[2024/06/16 02:01:59.890 +08:00] [WARN] [server.go:1079] [“failed to revoke lease”] [component=“embed etcd”] [lease-id=08f58c96d80b963e] [error=“etcdserver: request timed out”]
[2024/06/16 02:03:00.407 +08:00] [WARN] [util.go:121] [“failed to apply request”] [component=“embed etcd”] [took=78.553µs] [request=“header:<ID:645576701095157679 > lease_revoke:id:08f58c96d80b95e6”] [response=size:28] [error=“lease not found”]
[2024/06/16 02:03:02.362 +08:00] [WARN] [util.go:163] [“apply request took too long”] [component=“embed etcd”] [took=1.293770921s] [expected-duration=100ms] [prefix=] [request=“header:<ID:645576701095157767 > lease_grant:<ttl:60-second id:08f58c96d80ba006>”] [response=size:40]
When communicating via Remote Procedure Call (RPC), the operation exceeded the set deadline. Network latency, resource bottlenecks, high system load, or too short a configured time limit can cause the operation to not complete within the expected time. Determine if there is network jitter during this period.
My subsequent operation was to restart the master node, which restored the system. Currently, I need to investigate the cause of the issue that led to the task synchronization being stalled for a day.
I asked someone to check the TiDB network fluctuations, and they said there were no fluctuations.
Could it be that operations are not allowed during the backup period of the DM host?
I haven’t used DM yet. Here are some suggestions based on other operational experiences: 1. Check if the table structure has changed. 2. Determine if there are large-scale operations causing resource shortages by observing the logs before the issue occurred. 3. Human error due to unintentional operations.