Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: DM 同步 mysql到 tidb 延迟 波动
[MySQL Version] 5.7
[TiDB Version] 5.4.1
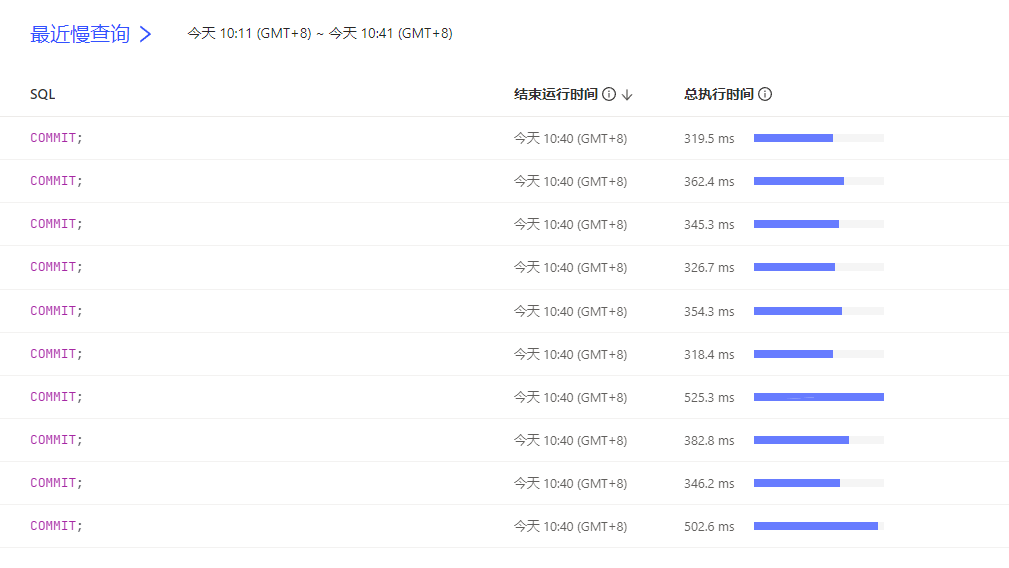
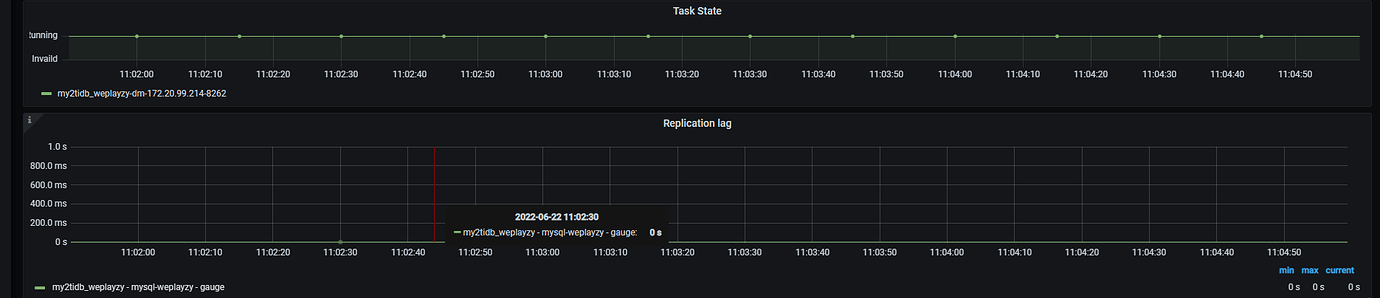
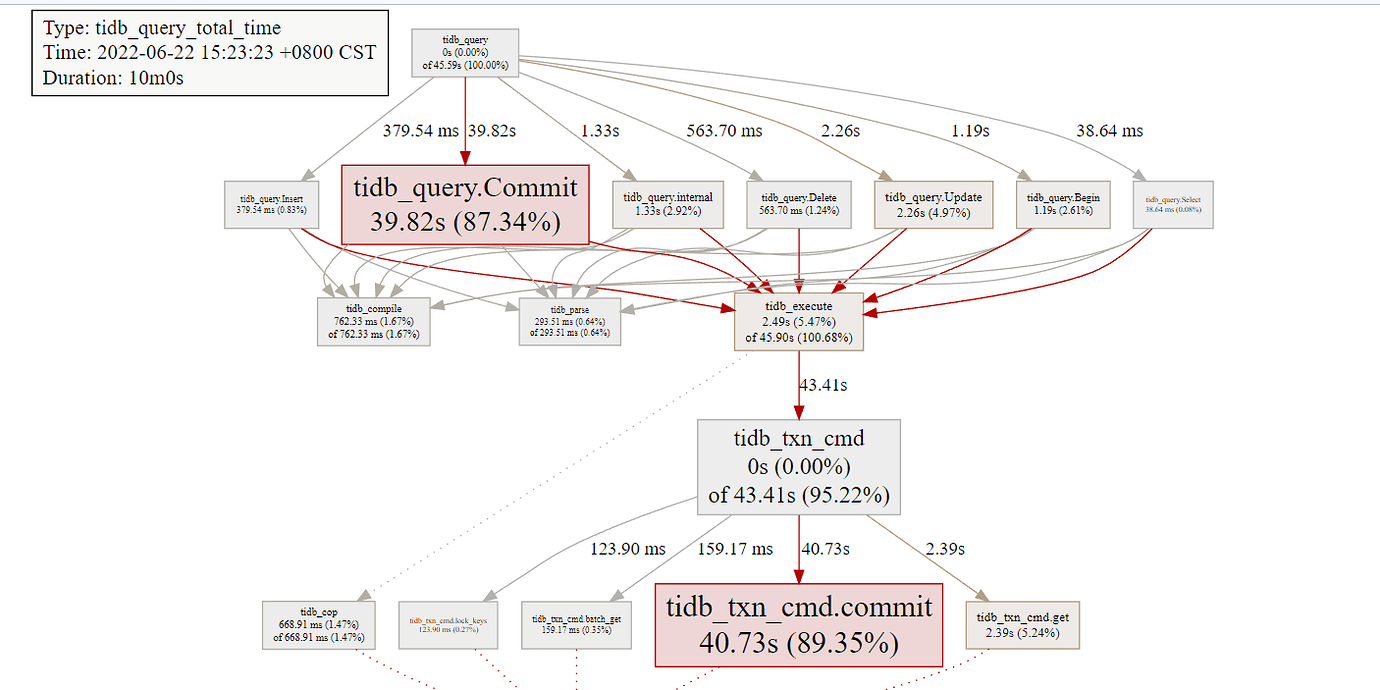
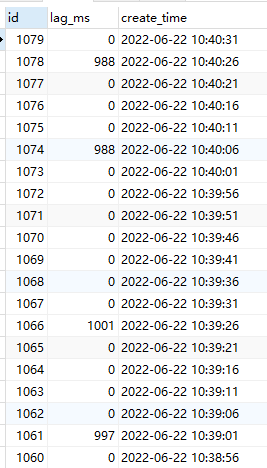
[Problem Encountered] Through our own latency monitoring and application testing, we found that the downstream TiDB latency fluctuates, sometimes being 0 and sometimes close to 1s. In the test environment with SSD and around 100 QPS, the dashboard shows slow logs all related to commit latency of 600ms (is the unstable latency related to slow commits???).
DM Configuration
# ----------- Global Configuration -----------
# Task name, must be globally unique
name: “my2tidb_xxxzy”
# Task mode, can be set to "full", "incremental", "all". "all" means full + incremental
task-mode: all
# Database to store `meta` information downstream, sync point information is stored in the table xxxx_syncer_checkpoint
meta-schema: "dm_meta"
# Case sensitivity
case-sensitive: false
# Online DDL
online-ddl: true # Supports automatic handling of upstream "gh-ost" and "pt"
#online-ddl-scheme: "pt" # `online-ddl-scheme` will be deprecated in the future, it is recommended to use `online-ddl` instead of `online-ddl-scheme`
# Downstream database instance configuration
target-database:
host: "ccc"
port: 4000
user: "root"
password: "zLHo4i9gnUshZyPgIKZvXECpFxInJEA=" # It is recommended to use the encrypted ciphertext by dmctl
max-allowed-packet: 67108864 # TiDB default 67108864 (64 MB)
# Black and white list configuration
block-allow-list: # Block-allow-list filtering rule set for tables matched by upstream database instances
bw-rule-1: # Name of the black and white list configuration
do-dbs: ["xxx",]
mydumpers: # Configuration parameters for the dump processing unit
global: # Configuration name
#rows: 2000 # Enable multi-threaded concurrent export for a single table, the value is the maximum number of rows contained in each chunk exported. If rows is set, DM will ignore the value of chunk-filesize.
threads: 4 # Number of threads for the dump processing unit to export data from the upstream database instance, default is 4
chunk-filesize: 64 # Size of data files generated by the dump processing unit, default is 64 MB
extra-args: "--consistency none" # Other parameters for the dump processing unit, no need to configure table-list in extra-args, DM will automatically generate it
loaders: # Configuration parameters for the load processing unit
global: # Configuration name
pool-size: 16 # Number of threads for the load processing unit to concurrently execute SQL files from the dump processing unit, default is 16. Normally, this does not need to be set. When multiple instances are migrating data to TiDB simultaneously, this value can be appropriately reduced based on the load.
dir: "./dumped_data" # Directory where the dump processing unit outputs SQL files, and also the directory where the load processing unit reads files. The default value for this configuration item is "./dumped_data". Different tasks corresponding to the same instance must configure different directories.
syncers: # Configuration parameters for the sync processing unit
global: # Configuration name
worker-count: 16 # Number of concurrent threads applying the binlog transmitted to the local, default is 16. Adjusting this parameter will not affect the concurrency of upstream log pulling, but will put significant pressure on the downstream.
batch: 200 # Number of SQL statements in a transaction batch migrated to the downstream database by sync, default is 100.
# ----------- Instance Configuration -----------
mysql-instances:
- source-id: "mysql-xxxzy" # Upstream instance, i.e., MySQL source_id
block-allow-list: "bw-rule-1" # Name of the black and white list configuration
mydumper-config-name: "global" # Name of the mydumpers configuration
loader-config-name: "global" # Name of the loaders configuration
syncer-config-name: "global" # Name of the syncers configuration
Sync latency screenshot:
Dashboard screenshot: