The “Global Secondary Index” here means that it allow to use a different partition key than the primary partitioning.
For example, for a table with just three colunms: user(userId varchar, email varchar, others varchar, PK userId, Partition(userId))
I can see that a “local” secondary index as <userId, email> works because it has the local partition key userId.
But I also want to have another “global” index as . So that I can get a record when just with an email, without knowing the userId. If I creates an index <email, userId> I guess it won’t works as I expected for performance reasons? The query like "Select * from user where email = "abc@efg.com " will essentially have to run in every partition.
What I am hoping is that, when creating the index , it will creates another partition key with just email. And the index data doesn’t have to be strong consistent. Eventual consistent is enough. This is how it works in DynamoDB.
LMK if that’s supported. I am very interested in using TiDB if this is available.
Thanks
TiDB does support secondary indexes, but it does not have the concept of “global secondary index” like DynamoDB. In TiDB, secondary indexes are created on a per-table basis and are not partitioned separately from the primary partitioning.
In your example, if you create a secondary index on the email column, it will be a local secondary index and will be partitioned based on the primary partitioning key (userId). This means that the query SELECT * FROM user WHERE email = "abc@efg.com" will still need to be executed on every partition, which may not meet your performance expectations.
TiDB does not currently provide a built-in mechanism for creating a separate partition key for a secondary index. However, you can consider using a different table structure or data modeling approach to achieve a similar result. For example, you could create a separate table with the email column as the primary key, and use it as a lookup table to retrieve the corresponding userId when querying by email. This approach would allow you to perform efficient queries on the email column without having to scan all partitions.
Please note that TiDB’s secondary indexes provide strong consistency, not eventual consistency like DynamoDB. If you require eventual consistency, you would need to implement a custom solution on top of TiDB.
I hope this clarifies the capabilities of TiDB’s secondary indexes. If you have any further questions, please let me know.
This is a typical workaround. But it will increase the latency when using transaction to update the two tables across partitions. Unless using CDC behind that to update the additional table. That’s why DynamoDB built that (and likely with CDC ) to make it much more friendly.
Thanks for the reply. I hope that can be in the future plan.
I understand your concern about the potential increase in latency when using a separate table for lookup. Indeed, using a separate table for lookup can introduce additional complexity and overhead, especially when updating both tables within a transaction.
It's worth noting that TiDB is an open-source distributed database that is continuously evolving and improving. The TiDB community is actively working on enhancing its features and capabilities based on user feedback and requirements.
I appreciate your feedback and suggestion regarding the support for a "global secondary index" feature similar to DynamoDB. I will pass this feedback along to the TiDB team for consideration in future development plans.
If you have any more questions or need further assistance, please feel free to ask. Thank you!
Hi prclqz, I reviewed the answer from TiDB-Bot, it was not that correct. TiDB actually will not create partition if don’t explicitly require it by using ‘partition table’: Partitioning | PingCAP Docs. TiDB use primary key or implicit primary key(we called it row id) to locate the data in the storage, and the secondary index is also supported just like MySQL does.
so in your example here:
But I also want to have another “global” index as . So that I can get a record when just with an email, without knowing the userId. If I creates an index <email, userId> I guess it won’t works as I expected for performance reasons? The query like "Select * from user where email = "abc@efg.com " will essentially have to run in every partition.
if you don’t have an index for <email, userId>, and you only give the email value, tidb can’t use the primary key to locate the row data. So it will execute as a table scan to find the exact data.
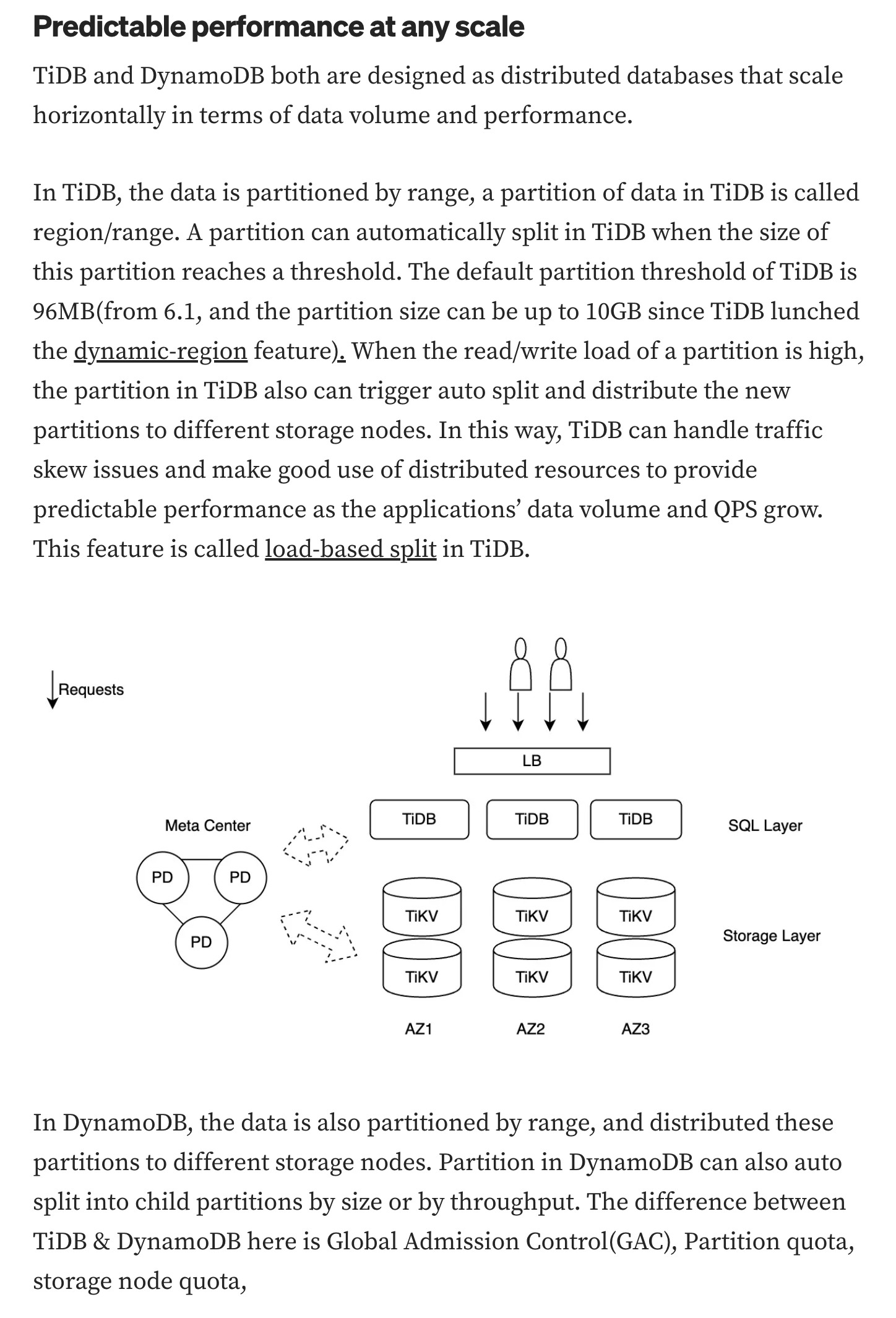
The concepts of TIDB and Dynamodb are different about partition.
In DynamoDB, the database determines the location of data in physical storage through a Partition Key, but in the underlying implementation of TiDB, it uses another concept called Region to distribute data across different physical machines.
I am not sure about the amount of data you need to process. Assuming that the data volume of a table does not exceed 100 million, you may not need to use TiDB’s partition table.
You can create your data table using the following SQL:
Do you meant that will provide the same performance & scalability compared to using GSI in DynamoDB, for query like "Select * from user where email = "abc@efg.com " ?
I am just making an example to help you understand what I meant by “Global Secondary Index”. The real use case is much more complicated than that. e…g the userId will be a VARCHAR instead of an integer. And we will have both heavy query using the PK and the above query for GSI.
Yes, TiDB achieves performance and scalability through the regions mechanism (compare to the partitions in DynamoDB), but this is transparent to users. Users can create data tables and indexes like they do with standalone MySQL, without the need for users to learn a new concept (like “Global Secondary Index”).
You can learn more about the differences between TiDB and DynamoDB through the following article:
Regarding actual performance, this requires a POC to verify.This depends on many factors, including the type of query you execute and the configuration of the machine you used.If you encounter problems in the POC process, you can continue to contact us.
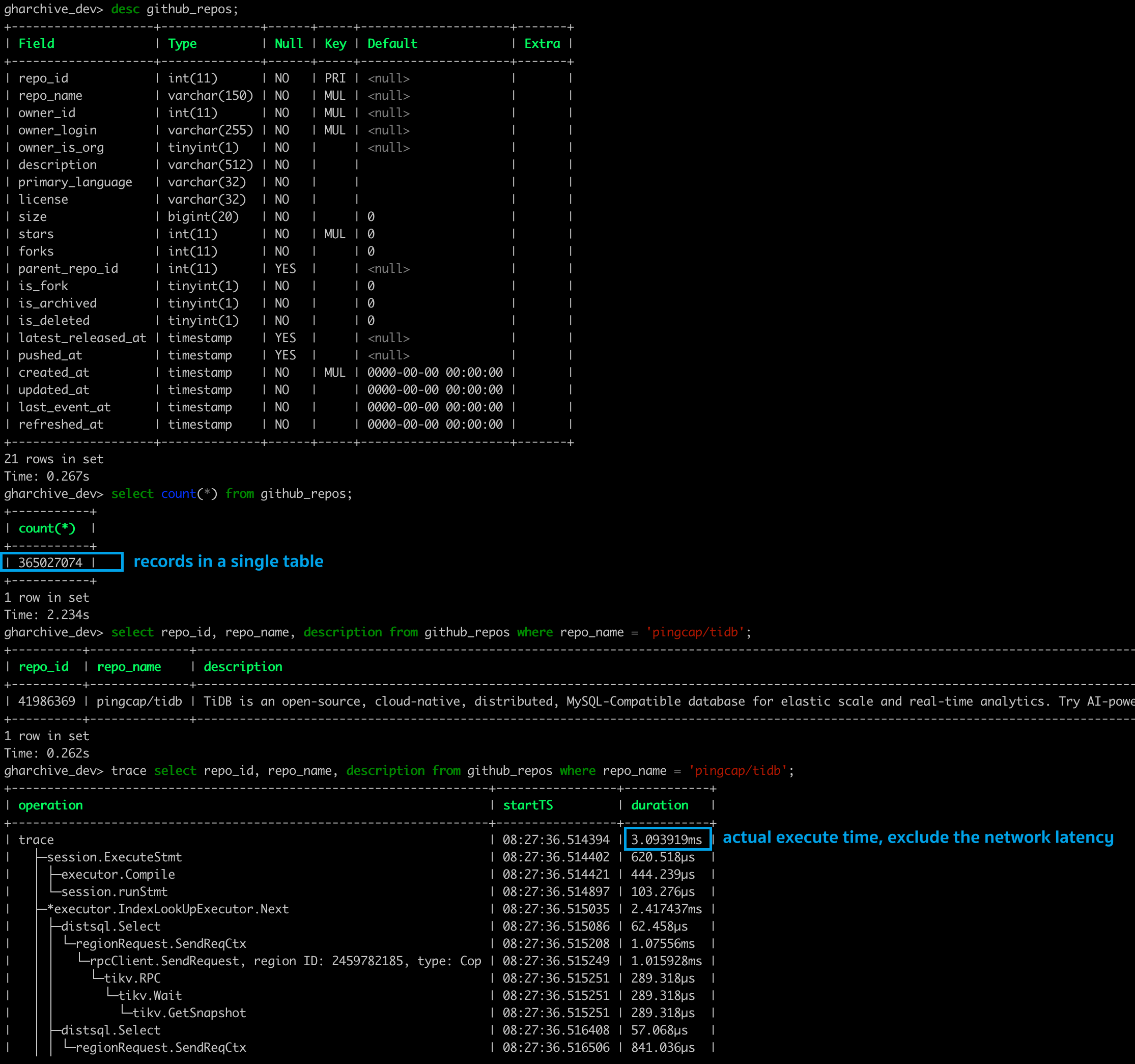
Here is a single table with 360 million records on TiDB Serverless, and I created a secondary index for the repo_name column, and then performed a query with condition WHERE repo_name='pincgap/tidb':
Thanks. With your example, does the query run against all the partitions and aggregate the results? If so it will hit the limit very soon if there are hundreds of queries like this running in parallel, and each query would expect thousands of rows (with ordering).
The perf not just a single query , but in parallel queries. And we also need sorted results. That’s what I need for my use case. (I may provide a poc here in the future)
In my example, the data is stored in a github_repos table (note: this is not a partition table), and the data in the table will be split into multiple regions in TiDB (= the partitions in DynamoDB).
When we create a secondary index index_gr_on_repo_name for the github_repos table, it doesn’t create a local secondary index on each region, it creates a secondary index globally, so when we query the data through the index, it’s NOT run against all regions and then aggregated to get the results.
Additionally, if your application does require the use of a partitioned table and you want to build a global index on the partitioned table, you are welcome to describe your scenario and requirements on this feature issue: