Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 消除告警,调整参数
[TiDB Usage Environment] Production Environment / Testing / PoC
[TiDB Version] v5.4.0 3tidb 3pd 3tikv
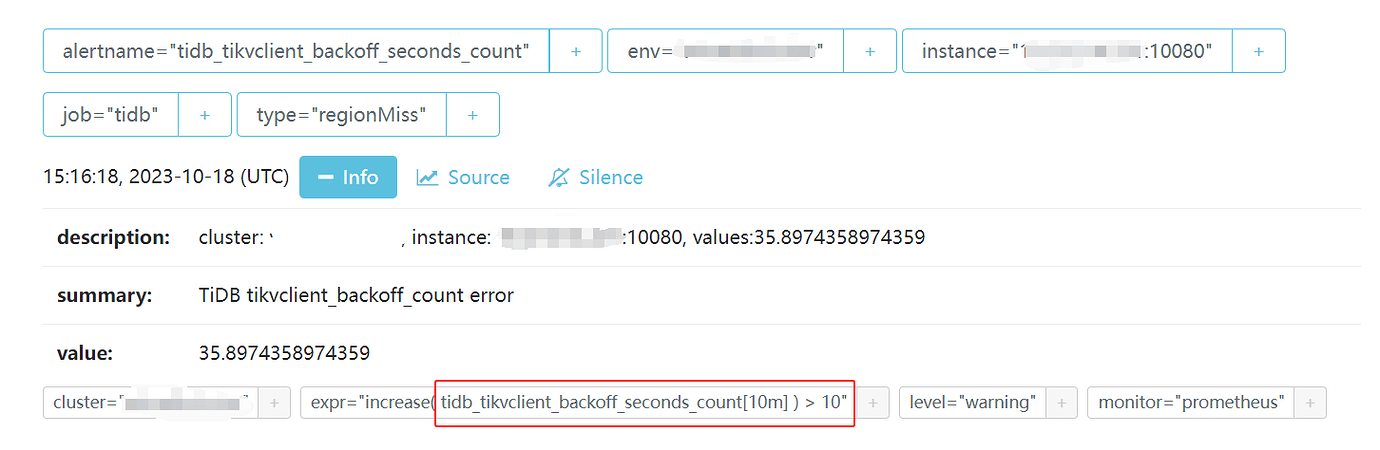
[Reproduction Path] The monitoring indicates TiDB_tikvclient_backoff_seconds_count[10M]>10. This warning does not affect the business but occurs frequently. How can I eliminate this warning, and how can I increase the TiDB_tikvclient_backoff_seconds_count parameter?
[Encountered Problem: Problem Phenomenon and Impact]
[Resource Configuration] Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
[Attachment: Screenshot/Log/Monitoring]
Modify the parameters in the /tidb-deploy/prometheus-8249/conf/tidb.rules.yml file
labels:
env: tsp-prod-tidb-cluster
level: warning
expr: increase(tidb_tikvclient_backoff_seconds_count[10m]) > 10
Then restart the Prometheus service
TiDB_tikvclient_backoff_seconds_count
- Alert rule:
increase(tidb_tikvclient_backoff_seconds_count[10m]) > 10
- Rule description: The number of retries initiated when TiDB encounters an error accessing TiKV. If the number of retries exceeds 10 within 10 minutes, an alert is triggered.
It is best to configure the central control machine, otherwise the reload configuration will be overwritten.
Add to the blacklist, out of sight, out of mind.
Oh no, what if it really backoffs…
That must be a disk issue, there will be other error alerts.
The alert level is warning and can be ignored.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.