Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 查表出现"ERROR 9005 (HY000): Region is unavailable",集群状态又没有大问题
[TiDB Usage Environment] Production Environment
[TiDB Version] 6.1
[Encountered Problem: Phenomenon and Impact]
Phenomenon: Currently, many large table queries result in “ERROR 9005 (HY000): Region is unavailable,” leading to an inability to back up and query tables.

Architecture:
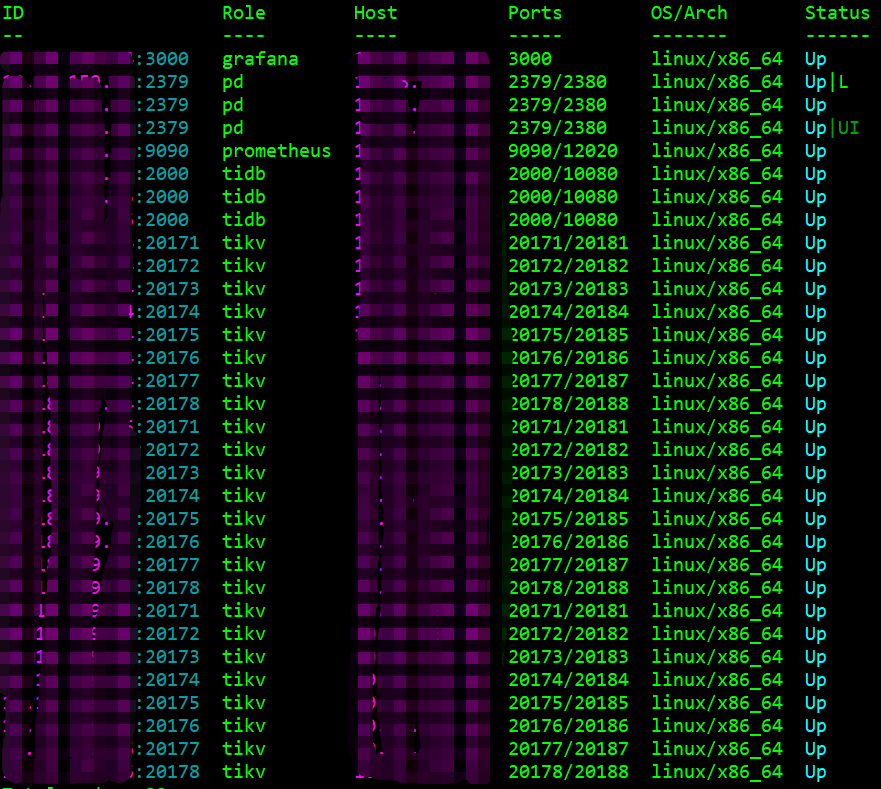
Background:
Once performed a BR, but due to insufficient memory, two KV nodes crashed. Finally, used manual region allocation and online unsafe recover to completely decommission the faulty nodes.
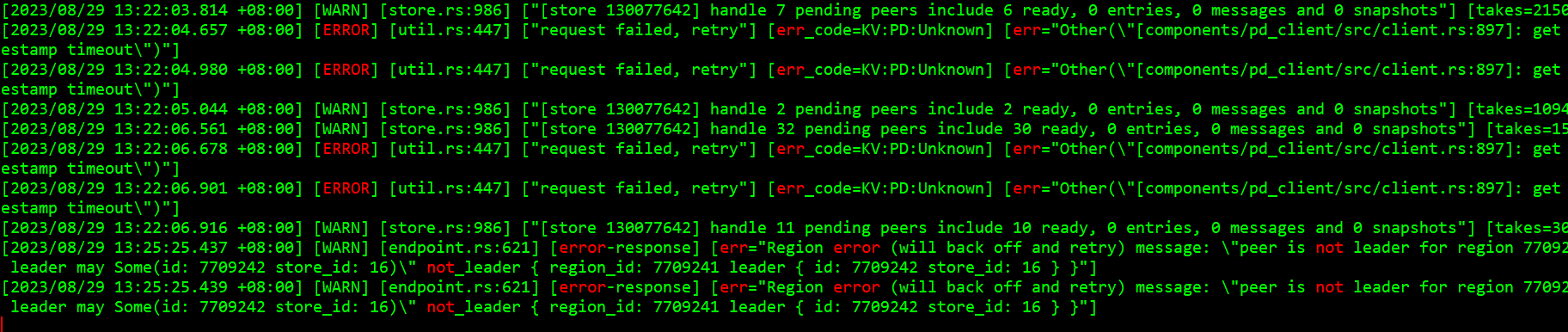
KV logs report a large number of errors:
[WARN] [peer.rs:5618] [“leader missing longer than abnormal_leader_missing_duration”] [expect=10m] [peer_id=33046701] [region_id=33046699]
[2023/08/29 13:22:03.814 +08:00] [WARN] [store.rs:986] [“[store 130077642] handle 7 pending peers include 6 ready, 0 entries, 0 messages and 0 snapshots”] [takes=2150]
[2023/08/29 13:22:04.657 +08:00] [ERROR] [util.rs:447] [“request failed, retry”] [err_code=KV:PD:Unknown] [err=“Other("[components/pd_client/src/client.rs:897]: get timestamp timeout")”]
[2023/08/29 13:22:04.980 +08:00] [ERROR] [util.rs:447] [“request failed, retry”] [err_code=KV:PD:Unknown] [err=“Other("[components/pd_client/src/client.rs:897]: get timestamp timeout")”]
[2023/08/29 13:22:05.044 +08:00] [WARN] [store.rs:986] [“[store 130077642] handle 2 pending peers include 2 ready, 0 entries, 0 messages and 0 snapshots”] [takes=1094]
[2023/08/29 13:22:06.561 +08:00] [WARN] [store.rs:986] [“[store 130077642] handle 32 pending peers include 30 ready, 0 entries, 0 messages and 0 snapshots”] [takes=1513]
[2023/08/29 13:22:06.678 +08:00] [ERROR] [util.rs:447] [“request failed, retry”] [err_code=KV:PD:Unknown] [err=“Other("[components/pd_client/src/client.rs:897]: get timestamp timeout")”]
[2023/08/29 13:22:06.901 +08:00] [ERROR] [util.rs:447] [“request failed, retry”] [err_code=KV:PD:Unknown] [err=“Other("[components/pd_client/src/client.rs:897]: get timestamp timeout")”]
[2023/08/29 13:22:06.916 +08:00] [WARN] [store.rs:986] [“[store 130077642] handle 11 pending peers include 10 ready, 0 entries, 0 messages and 0 snapshots”] [takes=3061]
[2023/08/29 13:25:25.437 +08:00] [WARN] [endpoint.rs:621] [error-response] [err=“Region error (will back off and retry) message: "peer is not leader for region 7709241, leader may Some(id: 7709242 store_id: 16)" not_leader { region_id: 7709241 leader { id: 7709242 store_id: 16 } }”]
[2023/08/29 13:25:25.439 +08:00] [WARN] [endpoint.rs:621] [error-response] [err=“Region error (will back off and retry) message: "peer is not leader for region 7709241, leader may Some(id: 7709242 store_id: 16)" not_leader { region_id: 7709241 leader { id: 7709242 store_id: 16 } }”]
My personal approach is to add a few more physical machines, expand all the nodes, and then decommission the existing nodes. I am not sure if this solution is feasible. Could the experts please help me see if there is a better and simpler way?