Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: ERROR 9005 (HY000): Region is unavailable
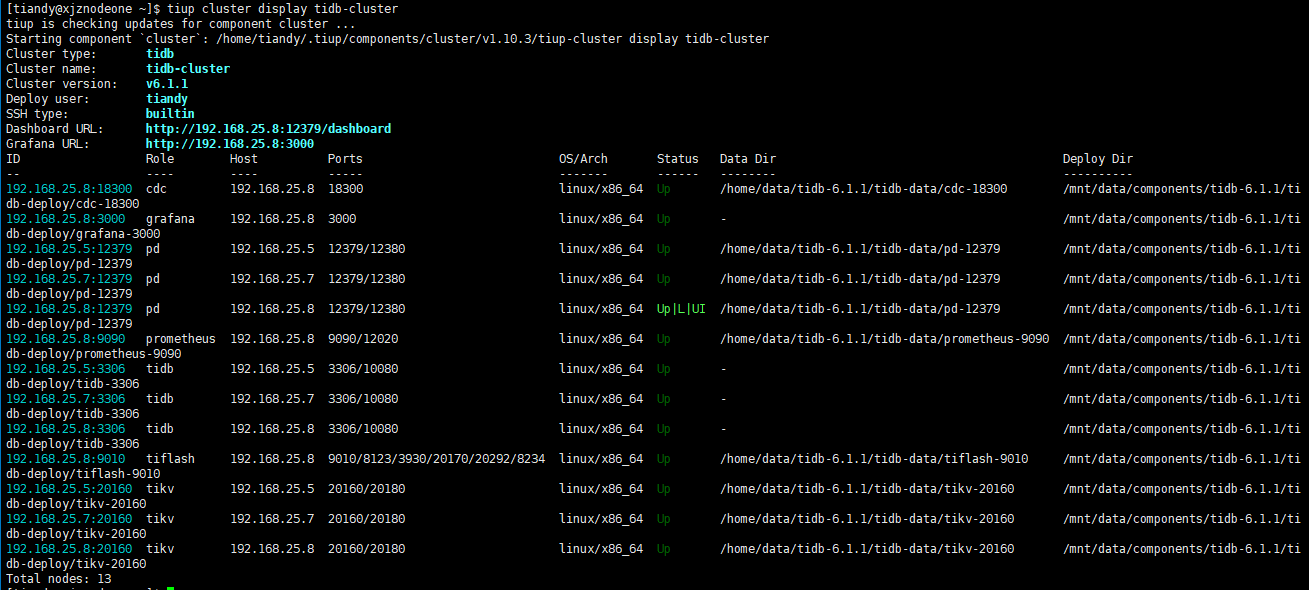
Cluster topology
Currently testing a three-node cluster. After manually taking one node offline (shutting down the server), the database becomes unusable;
Error: ERROR 9005 (HY000): Region is unavailable
Why can’t high availability be achieved when one node fails?
I see that PD and TiKV are deployed together. Shutting down the server causes not only TiKV to go offline, so you might encounter the above errors. For example, if the PD leader goes offline and there are TiKV or TiKV region leaders on it, it will take time to recover.
-
Is the configured number of replicas 3?
-
Has the PD leader gone down?
If these two conditions are not met, the above errors will occur…
It is recommended to deploy a single instance for easier testing of availability.
If it’s just for experience, the current mixed deployment is fine.
Hello: Is it always unavailable? Or is it only unavailable for a short period of time?
The default number of replicas is 3.
The leader did not crash.
It has been unavailable all the time. This is the distribution of the region.
If the one that went offline is not the leader, do we need to wait for TiKV to synchronize itself before it can recover when encountering this error?
Why is the 192 segment in tiup, but the 10 segment in tikv_store_status? It keeps reporting “Region is unavailable,” which definitely indicates that the majority of region replicas have failed. What operations have been performed?
No, the two screenshots are not from the same cluster, but the same tests were conducted, and the same situation occurred.
Find a smaller table that will report this error, use show table xxx regions to find the region_id, then use pd-ctl region xxx to check the output. Let’s take the 10 network segment as an example.
It seems to be on the disconnected machine. Will this situation automatically recover?
Why is there only one replica? Have you adjusted the number of replicas? Use pd-ctl config show to check; max-replicas should be >= 3. Also, check the Grafana overview monitoring, specifically the leader and region monitoring under TiKV.
It still looks like an environment issue… We need to check what operations were performed that caused this.
I found the problem. I changed the replica count to 1. If I change it to 3, this issue should not occur, right?
It depends on whether your data is lost. If not, start TiKV and it will automatically balance after changing to 3 replicas. If the data is lost, you’ll have to redo it.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.