Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: Sysbench写测试时报错
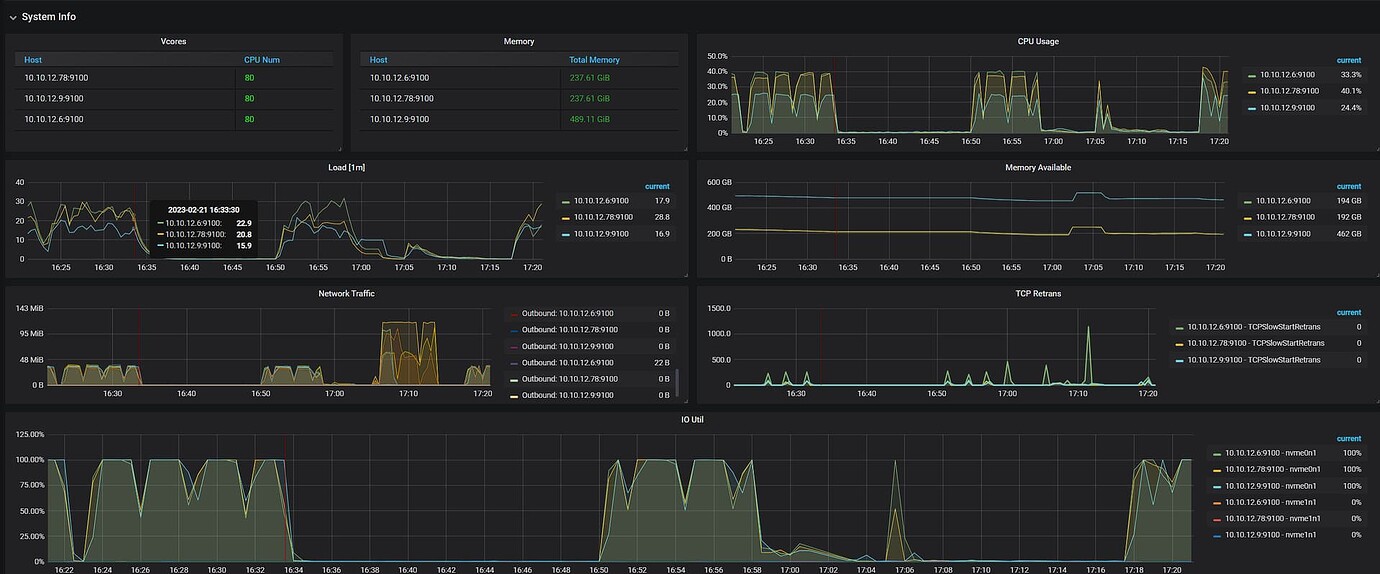
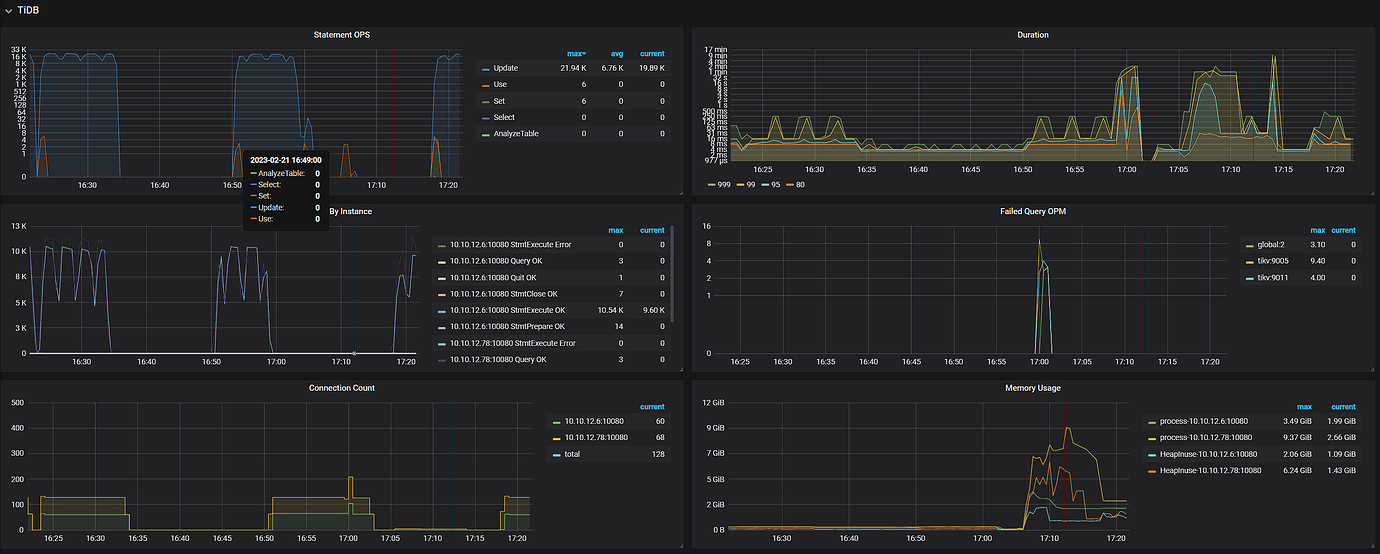
After setting up the cluster and using Sysbench for testing, the read test (point_select) can proceed normally, but the write test (index_update) encounters an error.
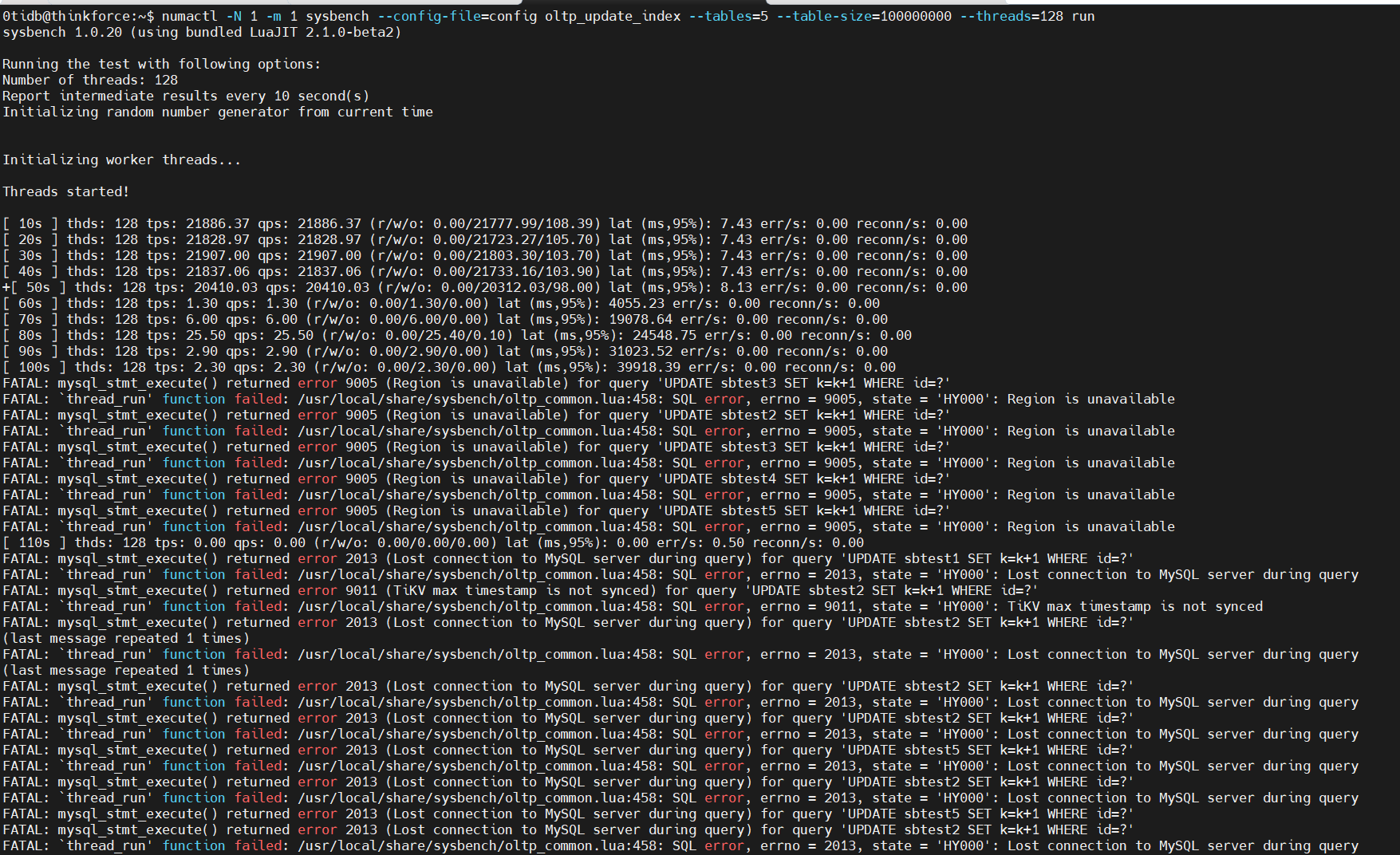

It seems like there is a consistency issue. I would like to ask the experts how to solve this problem.
Hardware configuration: 3 machines: ARM processor (2×40c 2.5GHz) Memory: 32GB×8 Hard disk: 500G SSD / dapustor 3.2T
| Cluster Topology | 10.10.12.6 | 10.10.12.78 | 10.10.12.9 |
|---|---|---|---|
| numa 0 | TiKV, PD | TiKV, PD | TiKV, PD |
| numa 1 | TiDB | TiDB | Haproxy, Sysbench |
TiDB configuration items:
server_configs:
tidb:
log.level: error
mem-quota-query: 34359738368
performance.server-memory-quota: 34359738368
performance.txn-total-size-limit: 10485760000
prepared-plan-cache.enabled: true
token-limit: 3001
tikv:
coprocessor.split-region-on-table: false
log-level: error
raftdb.max-background-jobs: 12
raftstore.apply-max-batch-size: 1024
raftstore.apply-pool-size: 8
raftstore.hibernate-regions: true
raftstore.raft-max-inflight-msgs: 1024
raftstore.store-max-batch-size: 1024
raftstore.store-pool-size: 4
rocksdb.compaction-readahead-size: 2MB
rocksdb.defaultcf.max-write-buffer-number: 32
rocksdb.writecf.max-write-buffer-number: 32
server.grpc-concurrency: 8
server.max-grpc-send-msg-len: 5242880
storage.block-cache.capacity: 64G
storage.scheduler-worker-pool-size: 8