Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: k8s上部署的TiDB集群使用br备份数据到s3时报错
[TiDB Usage Environment] Production Environment
[TiDB Version] v6.1.0
[Reproduction Path] Following the official documentation to use br to back up the database to s3 storage results in an error
[Encountered Problem: Problem Phenomenon and Impact]
[Resource Configuration]
backup-rbac.yaml

kubectl create secret generic s3-secret --from-literal=access_key=xxxxx --from-literal=secret_key=xxxxxx --namespace=tidb-cluster
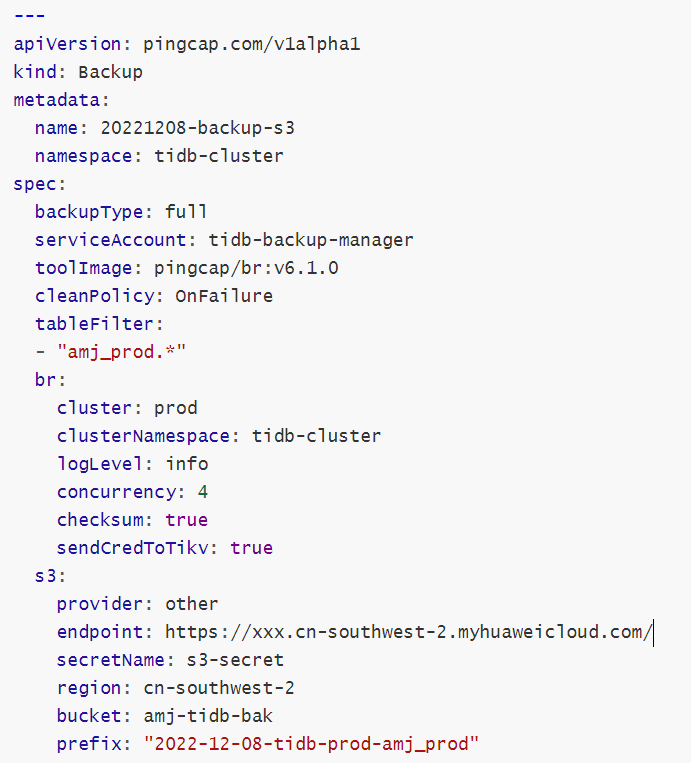
backup-tidb-s3.yaml
[Attachment: Screenshot/Log/Monitoring]
I1208 10:56:16.200308 9 backup.go:93] [2022/12/08 10:56:16.200 +00:00] [INFO] [client.go:610] [“finish backup push down”] [range-sn=56] [small-range-count=0]
I1208 10:56:16.200314 9 backup.go:93] [2022/12/08 10:56:16.200 +00:00] [INFO] [client.go:718] [“start fine grained backup”] [range-sn=56] [incomplete=1]
I1208 10:56:16.200446 9 backup.go:93] [2022/12/08 10:56:16.200 +00:00] [INFO] [client.go:1041] [“try backup”] [range-sn=55] [store-id=5] [“retry time”=0]
I1208 10:56:16.201802 9 backup.go:93] [2022/12/08 10:56:16.201 +00:00] [INFO] [client.go:672] [“find leader”] [Leader=“{"id":26000,"store_id":4}”] [key=7480000000000027FF185F720000000000FF0000000000000000FA]
I1208 10:56:46.202196 9 backup.go:93] [2022/12/08 10:56:46.202 +00:00] [INFO] [client.go:1041] [“try backup”] [range-sn=56] [“retry time”=0]
I1208 10:56:46.202221 9 backup.go:93] [2022/12/08 10:56:46.202 +00:00] [INFO] [client.go:1041] [“try backup”] [range-sn=54] [“retry time”=0]
I1208 10:56:46.202227 9 backup.go:93] [2022/12/08 10:56:46.202 +00:00] [INFO] [client.go:1041] [“try backup”] [range-sn=57] [store-id=1806129] [“retry time”=0]
I1208 10:56:46.202427 9 backup.go:93] [2022/12/08 10:56:46.202 +00:00] [WARN] [push.go:86] [“fail to connect store, skipping”] [range-sn=55] [store-id=1815001] [error=“[BR:Common:ErrFailedToConnect]failed to make connection to store 1815001: context deadline exceeded”] [errorVerbose=“[BR:Common:ErrFailedToConnect]failed to make connection to store 1815001: context deadline exceeded\ngithub.com/pingcap/errors.AddStack\n\t/go/pkg/mod/github.com/pingcap/errors@v0.11.5-0.20211224045212-9687c2b0f87c/errors.go:174\ngithub.com/pingcap/errors.(*Error).GenWithStack\n\t/go/pkg/mod/github.com/pingcap/errors@v0.11.5-0.20211224045212-9687c2b0f87c/normalize.go:155\ngithub.com/pingcap/tidb/br/pkg/conn.(*Mgr).getGrpcConnLocked\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/pkg/conn/conn.go:352\ngithub.com/pingcap/tidb/br/pkg/conn.(*Mgr).GetBackupClient\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/pkg/conn/conn.go:371\ngithub.com/pingcap/tidb/br/pkg/backup.(*pushDown).pushBackup\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/pkg/backup/push.go:82\ngithub.com/pingcap/tidb/br/pkg/backup.(*Client).BackupRange\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/pkg/backup/client.go:606\ngithub.com/pingcap/tidb/br/pkg/backup.(*Client).BackupRanges.func1\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/pkg/backup/client.go:562\ngithub.com/pingcap/tidb/br/pkg/utils.(*WorkerPool).ApplyOnErrorGroup.func1\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/pkg/utils/worker.go:73\ngolang.org/x/sync/errgroup.(*Group).Go.func1\n\t/go/pkg/mod/golang.org/x/sync@v0.0.0-20220513210516-0976fa681c29/errgroup/errgroup.go:74\nruntime.goexit\n\t/usr/local/go/src/runtime/asm_amd64.s:1571”]

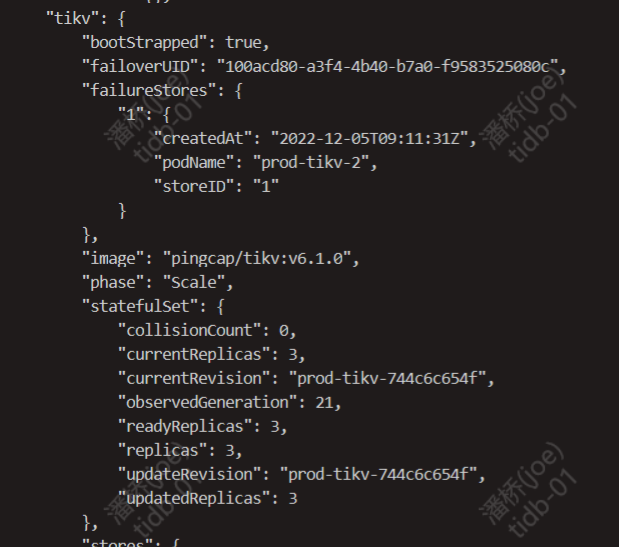
The info and warn messages here keep repeating, the directory I created on s3 exists, but data cannot be written into it. Can any expert explain this?