Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 分区大表执行 max(索引列) 报错或无返回
To improve efficiency, please provide the following information. A clear problem description can help solve the issue faster:
【TiDB Usage Environment】
Production environment, version 5.7.25-TiDB-v6.1.0
【Overview】 Scenario + Problem Overview
Background: The table has a total of about 50 billion rows, partitioned by day, with each partition having more than 100 million rows.
Partitioned Table Structure
Primary Key Index: PRIMARY KEY (dt, doc_id) /*T![clustered_index] NONCLUSTERED */,
PRIMARY KEY (dt, doc_id) /*T![clustered_index] NONCLUSTERED */,
KEY updatetime (updatetime),
KEY newdate (newdate)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin /*T![placement] PLACEMENT POLICY=storeonssd */
PARTITION BY RANGE (UNIX_TIMESTAMP(dt))
(PARTITION p20210601 VALUES LESS THAN (1622563200),
…)
【Background】 Operations performed
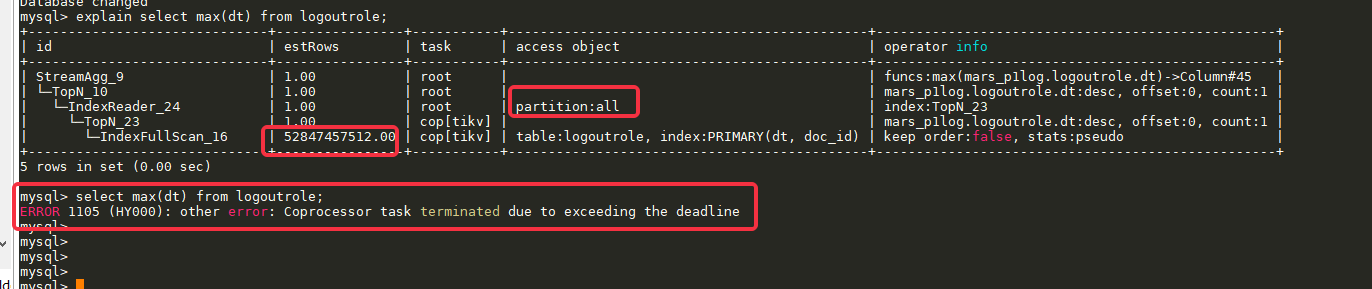
Executed a max query on the table, where dt is a time field and the first field of the primary key index:
select max(dt) from logoutrole;
【Phenomenon】 Business and database phenomena
【Problem】 Current issues encountered
-
Executing the query results in an error or no return for a long time. The error message is as follows:
mysql> select max(dt) from logoutrole;
ERROR 1105 (HY000): other error: Coprocessor task terminated due to exceeding the deadline
mysql> -
Execution plan
【Business Impact】
Unable to correctly retrieve content
【TiDB Version】
v6.1.0
【Application Software and Version】
5.7.25-TiDB-v6.1.0