Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: tikv&tidb升级6.1以后出现一些错误日志
【TiDB Usage Environment】
Production
【TiDB Version】
6.1.0
【Encountered Issues】
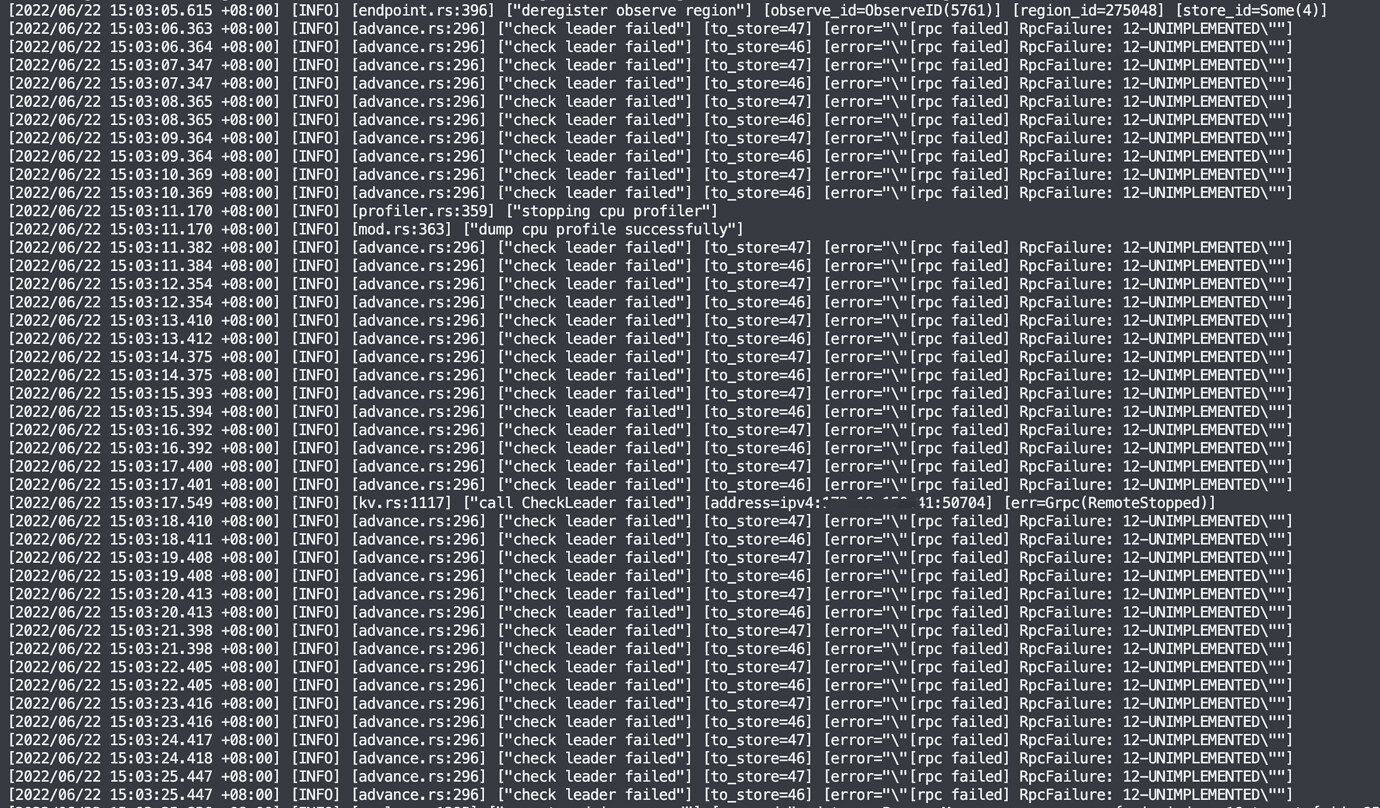
- The tikv log continuously shows [“check leader failed”] [to_store=46] [error=“"[rpc failed] RpcFailure: 12-UNIMPLEMENTED"”]
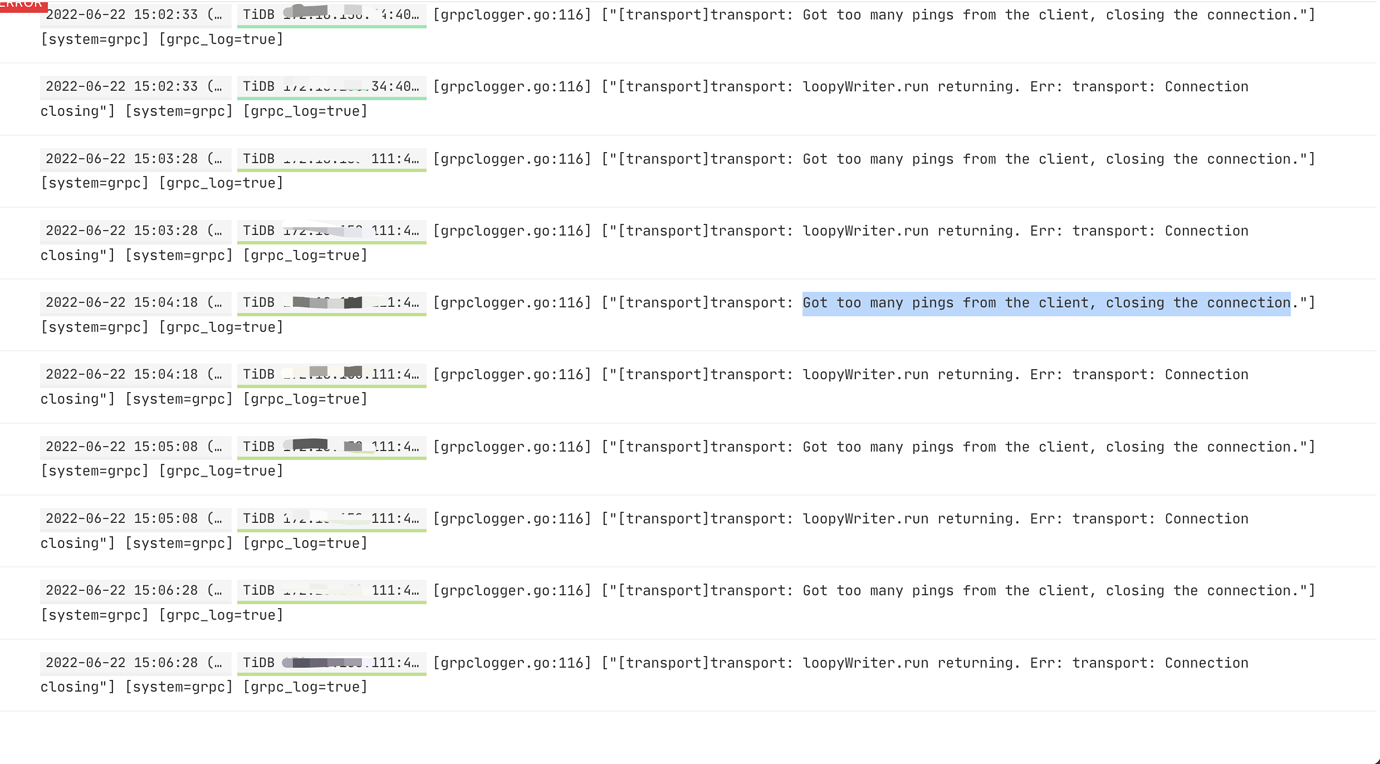
- The tidb log continuously reports “Got too many pings from the client, closing the connection”
【Reproduction Path】What operations were performed to encounter the issue
【Problem Phenomenon and Impact】
tikv.log
tidb log output from the console
What actions did you take before it appeared?
Upgrading from 5.4 to 6.1
tiup cluster upgrade tidb v6.1.0
Is there anyone who can help answer this question? There is too little information available. The only thing I could find is Got too many pings from the client, closing the connection. 和TiKV server timeout - TiDB 的问答社区, which doesn’t seem to be very helpful.
Yes, 1 is the TiKV log and 2 is the TiDB log. However, both of these errors appeared after the upgrade. Error 1 occurs almost every second, and Error 2 occurs approximately every 10 seconds. Although it does not affect the business, should such errors be reported? Should TiDB itself fix these issues through iterative versions, or should users troubleshoot and resolve these problems? It’s very strange to keep reporting these errors without addressing them, and it’s unclear whether some hidden issues might arise. There are basically zero answers online for these two errors.
Yes, the issue has been identified within TiDB and will be fixed in a future version.
tikv.log (18.8 MB)
I’ll also upload the full log for issue 1. Currently, I haven’t found any relevant context.
Is this a bug in version 6.1?
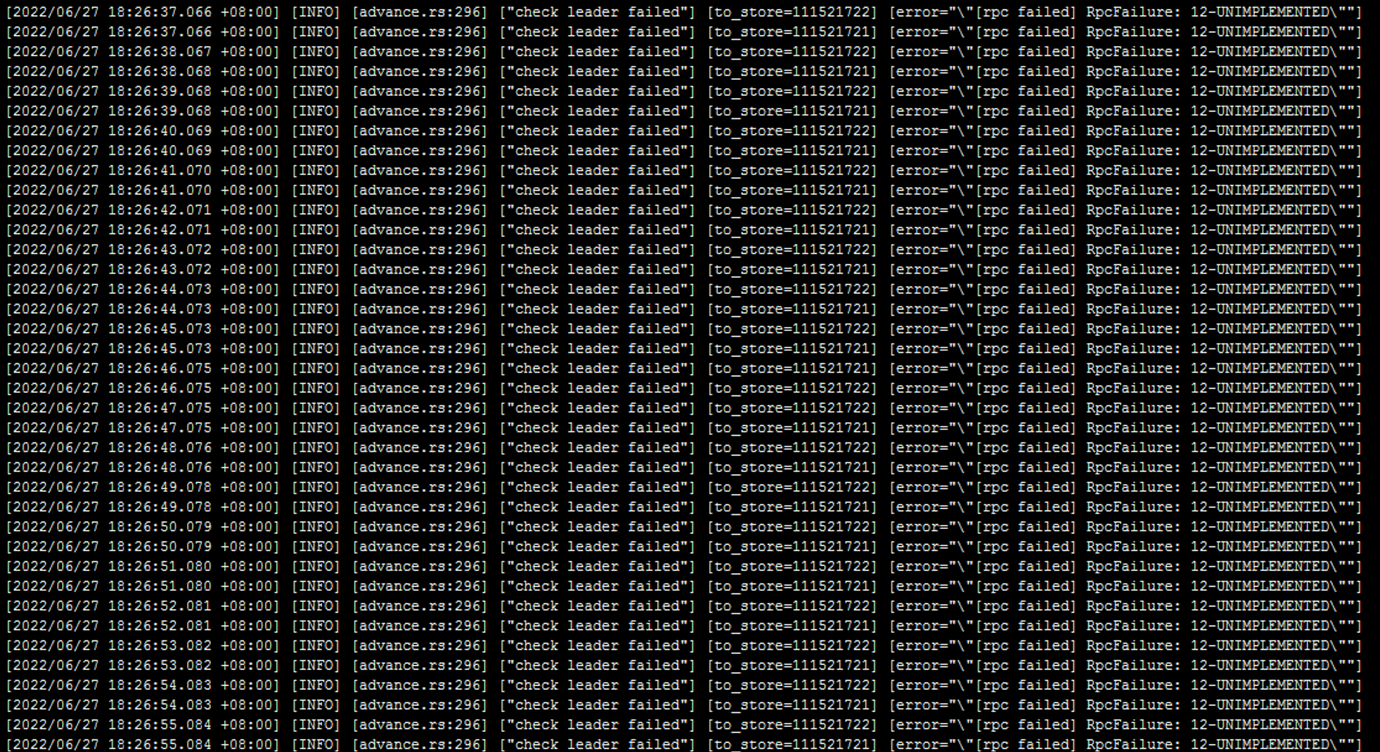
After the upgrade, I also encountered a lot of these logs:
[advance.rs:296] [“check leader failed”] [to_store=111521721] [error=“"[rpc failed] RpcFailure: 12-UNIMPLEMENTED"”]
Was this log generated during the upgrade process, or did it continue to be generated even after the upgrade was successful?
It will keep running after success. Mine is the same.
Info-type errors can be ignored. This error is actually encountered in the normal process. When the initiating RPC instance collects enough information, it will actively cancel, and this error will be reported upon cancellation. This issue has already been optimized on the master branch, filtering out cancel-type errors.
According to the expert, it means to ignore it just like the backoff error.
This topic was automatically closed 1 minute after the last reply. No new replies are allowed.