Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 执行Create table卡死
【TiDB Version】: 5.7.25-TiDB-v5.4.0
【K8s Version】: v1.20.15
【TiDB Operator Version】: 1.3.2
【Problem Encountered】:
After executing a create table command, it gets stuck and cannot be killed using kill tidb sessionid:
CREATE TABLE `test` (
`orderId` varchar(50) NOT NULL COMMENT 'Production Plan Order Number',
`state` tinyint(3) NULL DEFAULT 10 COMMENT 'Status 10 Not Cut 20 Partially Cut 50 Fully Cut',
`data` json NULL COMMENT 'Extended Data',
PRIMARY KEY (`orderId`)
) COMMENT = 'Cutting List';
Using SELECT ID, USER, INSTANCE, INFO FROM INFORMATION_SCHEMA.CLUSTER_PROCESSLIST order by info desc to view the process

Viewing DDL job through admin show ddl jobs as follows:
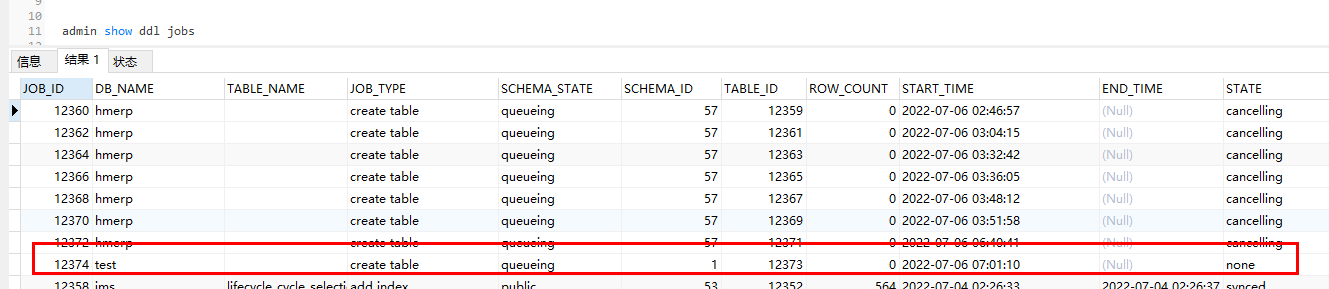
The state status is always none, the several cancelling statuses in the above image were cancelled by me.
Checking the tidb logs, many errors like the following appear, reported every ten seconds:
[2022/07/06 07:36:03.170 +00:00] [ERROR] [terror.go:307] ["encountered error"] [error=EOF] [stack="github.com/pingcap/tidb/parser/terror.Log\
\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/parser/terror/terror.go:307\
github.com/pingcap/tidb/server.(*Server).onConn\
\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/server/server.go:516"]
[2022/07/06 07:36:13.171 +00:00] [ERROR] [terror.go:307] ["encountered error"] [error=EOF] [stack="github.com/pingcap/tidb/parser/terror.Log\
\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/parser/terror/terror.go:307\
github.com/pingcap/tidb/server.(*Server).onConn\
\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/server/server.go:516"]
[2022/07/06 07:36:23.171 +00:00] [ERROR] [terror.go:307] ["encountered error"] [error=EOF] [stack="github.com/pingcap/tidb/parser/terror.Log\
\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/parser/terror/terror.go:307\
github.com/pingcap/tidb/server.(*Server).onConn\
\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/server/server.go:516"]
Why does executing the DDL command get stuck, and how can I check where the problem is:
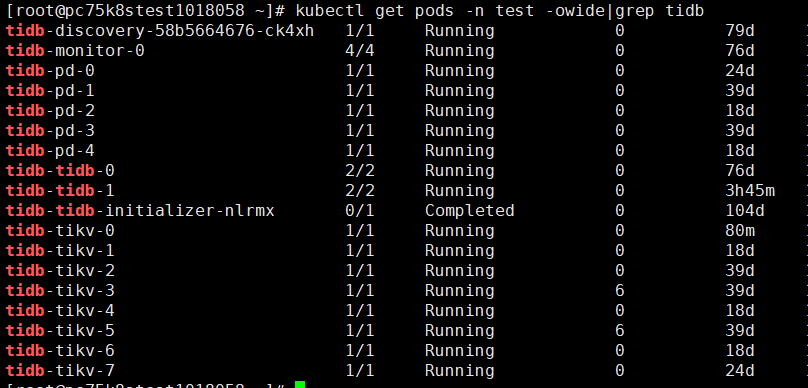
Cluster node information: