Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 执行truncate 语句卡住
[TiDB Usage Environment] Production Environment
[TiDB Version] 6.5.1
[Reproduction Path] What operations were performed when the problem occurred: No operations were performed
[Encountered Problem: Problem Phenomenon and Impact] Executing truncate on a table, the operation statement gets stuck, and subsequent scheduling tasks cannot be executed normally
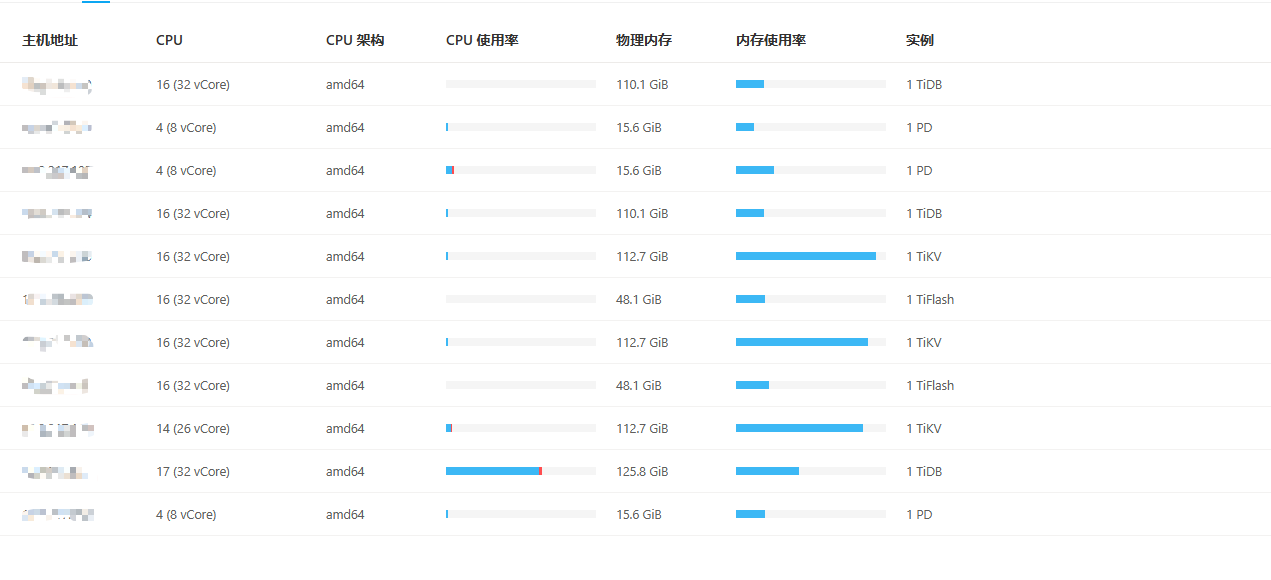
[Resource Configuration] Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
[Attachments: Screenshots/Logs/Monitoring]
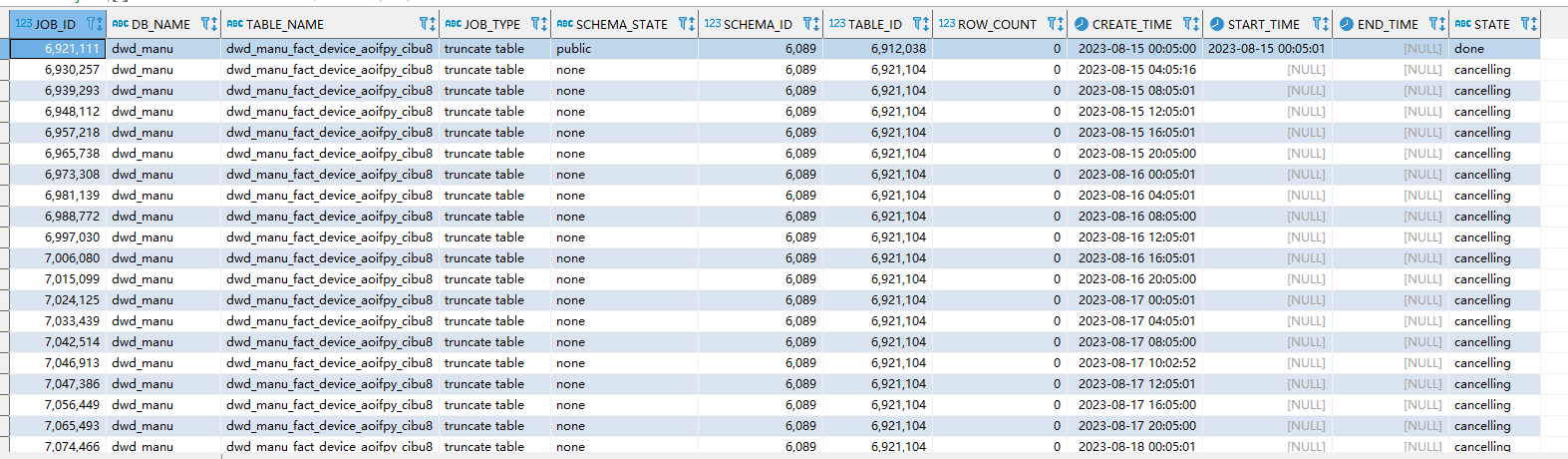
Monitoring DDL execution status
Attempted Solutions
- ADMIN CANCEL DDL JOBS related job_id
- – Execute tidb owner re-election
curl -X POST http://xxxx:xx/ddl/owner/resign
Current Status
The truncate operation on this table is stuck, causing subsequent DDL and DML statements to be unexecutable. How should this be resolved?
Restart method: shut down all TiDB nodes, then start them again.
Restart after closing everything.
SELECT ID, USER, INSTANCE, INFO FROM INFORMATION_SCHEMA.CLUSTER_PROCESSLIST; ------Query all active queries in the current cluster, find the id of the truncate table, then kill the id. Take a look.
ADMIN CANCEL DDL JOBS job_id doesn’t work either, then just restart the TiDB node 
I have tried using kill id, but it doesn’t work very well.
Is it necessary to restart the leader node, or restart all TiDB server nodes one by one, or shut down all TiDB server nodes and then restart them? Currently, there are 50,000 scheduling tasks running on TiDB every day. How can we minimize the impact as much as possible?
Are there any other methods? Shutting down all TiDB servers would have too much of an impact on the production environment.
Restart after closing everything.
There’s no better solution, you can restart with tiup cluster restart tidb-test -R tidb.
Restart command: tiup cluster restart clustername -R tidb
At that time, did you check for any zombie processes on the TiDB server using the ps command with the l parameter? The second column from the left should display a ‘Z’.
Restarting in a polling manner is also acceptable.
Checked, no zombie processes.
The current answer is that we can only restart.
So do you shut them all down one by one and then start them up one by one, or do you restart each TiDB instance individually?
Haven’t restarted yet, is there any other good solution?
ADMIN CANCEL and kill are not working, it seems that we can only resort to restarting.
Sequentially restarted the TiDB server nodes, but the DDL task is still stuck and has not been canceled.