Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 大佬们,我的haproxy+keepalived代理的tidb,可能是网络不稳定 vip从主切到备,然后短时间又切回主上。 集群中有节点缓存了备的arp信息 导致连不上tidb,这个是什么原因?
Experts, my HAProxy + Keepalived setup for TiDB might be experiencing network instability. The VIP switches from the primary to the backup and then quickly switches back to the primary. Some nodes in the cluster cache the ARP information of the backup, causing them to be unable to connect to TiDB. What could be the reason for this?
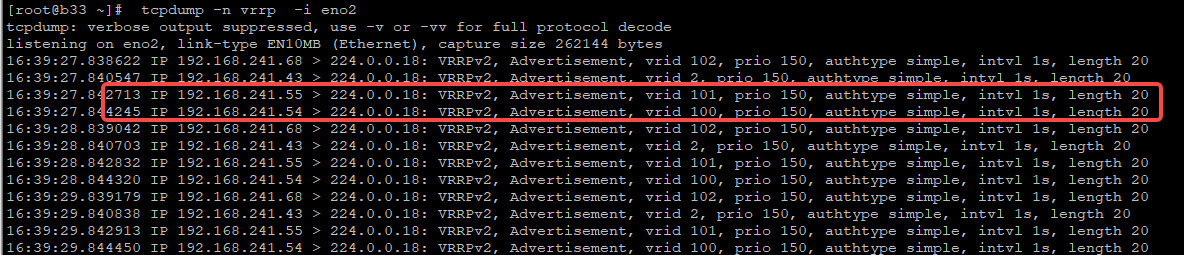
PS: In our cluster’s internal network, all servers are connected to a single/cascading switch. No gateway is configured.
Nodes can capture VRRP broadcast packets.