Note that this question was originally posted on the Chinese TiDB Forum. We copied it here to help new users solve their problems quickly.
Application environment
Test environment
TiDB version
TiDB v6.0.0-dmr
Reproduction method
Execute:
kubectl edit tc basic -n tidb-cluster
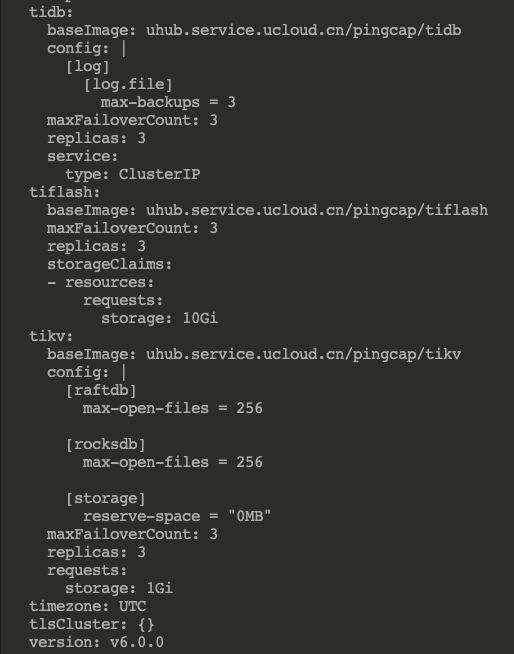
I modified the configuration file and added code:
tiflash:baseImage: pingcap/tiflashmaxFailoverCount: 3replicas: 3storageClaims:- resources:requests:storage: 10Gi
Then I got:
Problem
After I scaled out TiFlash on K8s, the pod could not start up. I checked out the log and found an error reported:
Poco::Exception. Code: 1000, e.code() = 0, e.displayText() = Exception: Cannot set max size of core file to 1073741824, e.what() = Exception
This was the only information in the log.
I checked out the source code and set the limit of the Docker service. This problem was solved.
Based on the error message, I viewed the source code and found:
struct rlimit rlim;
if (getrlimit(RLIMIT_CORE, &rlim))
throw Poco::Exception("Cannot getrlimit");
/// 1 GiB by default. If more - it writes to disk too long.
rlim.rlim_cur = config().getUInt64("core_dump.size_limit", 1024 * 1024 * 1024);
if (setrlimit(RLIMIT_CORE, &rlim))
{
std::string message = "Cannot set max size of core file to " + std::to_string(rlim.rlim_cur);
#if !defined(ADDRESS_SANITIZER) && !defined(THREAD_SANITIZER) && !defined(MEMORY_SANITIZER) && !defined(SANITIZER)throw Poco::Exception(message);
#else/// It doesn't work under address/thread sanitizer. http://lists.llvm.org/pipermail/llvm-bugs/2013-April/027880.html
std::cerr << message << std::endl;
#endif
}
This showed that the cause of the problem was that I set the value of core dump file too large.
First, I viewed the host system settings:
[root@host ~]# ulimit -c
unlimited
I found that it was unlimited, so I doubted the settings in the pod were incorrect.
I modified the configuration file config_templ.toml in configmap, added core_dump.size_limit = 1024 and restarted the pod. Then, TiFlash started normally. I checked out the pod:
I added limit-core.conf to /etc/systemd/system/docker.service.d/:
[Service]LimitCORE=infinity
Then, I executed:
systemctl daemon-reload systemctl restart docker.service
By deleting core_dump.size_limit = 1024, I solved the problem.