Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 扩容tiflash失败
[TiDB Usage Environment] Production Environment
[TiDB Version] V6.1.0
[Problem Encountered] After upgrading the cluster from V5.2.2 to V6.1.0, tiflash generates an 11G core.* file every two minutes. Therefore, all tiflash nodes were scaled in and then scaled out again. During scaling out, it prompts a directory conflict Error: Deploy directory overlaps to another instance (spec.deploy.dir_overlap)
[Reproduction Path]
[Problem Phenomenon and Impact]
SELECT * FROM information_schema.tiflash_replica; and ALTER TABLE DB.TABLE SET tiflash replica 0;;tiup cluster scale-in hrdb --node X.X.X.X:X and tiup cluster prune cluster
[root@tidb01 config-tidb]# tiup cluster scale-out XXXX scale-out-20220728-51.yaml
[Attachment] Relevant logs and monitoring (https://metricstool.pingcap.com/)
If the question is related to performance optimization or fault troubleshooting, please download the script and run it. Please select all and copy-paste the terminal output results for upload.
Is forced scaling down effective? Add the parameter --force.
If not, try the following:
Manual scaling down…
The above commands do not contain information about Tiflash, so the scale-down should have been successful.
 But I am currently experiencing a scaling failure.
But I am currently experiencing a scaling failure.
Just re-expand it, anyway, if it fails, you know how to handle it.
The scale-down is complete, but now it’s impossible to scale up 
You need to clean up all the data directories on the original TiFlash node. All the initialization tasks must be done without exception…
Otherwise, it will be assumed that TiFlash is already running on the node, and expansion will not be possible…
The data related to TiFlash in the deploy_dir, data_dir, and log_dir directories has been cleaned up, but the expansion still failed.
You need to modify your configuration file. In the tiflash_servers module, define a separate folder for deploy_dir, data_dir, and log_dir that has not been used before.
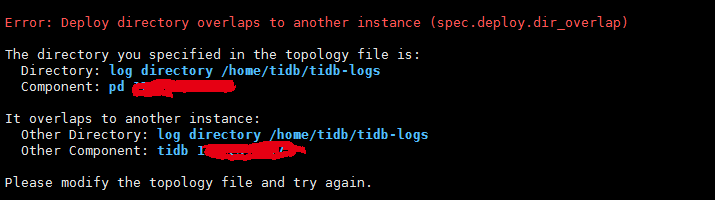
Specifying the directory also failed. After checking, it seems that at the very beginning of the deployment, the logs of each component were stored in the same directory log_dir: /home/tidb/tidb-logs.
Could you please remove the global part and try again, leaving only the tiflash_servers part like in my example?
Additionally, it seems that the log directories for all components in your current configuration are the same: log_dir: /home/tidb/tidb-logs. I’m not sure if this has any impact.
I have already tried it, but it still doesn’t work.
Hmm, I also suspect it might be due to this reason.
However, since it’s a production environment, using tiup cluster edit-config ${cluster-name} requires restarting the cluster, which is not feasible at the moment. Additionally, it’s not certain if this is the cause.
Didn’t it say that versions before 5.3 cannot be upgraded online to versions after 5.3 for TiFlash?
The image you provided is not accessible. Please provide the text you need translated.
Yes, that’s exactly what I meant. It seems a bit complicated, so it’s better to just delete the TiFlash replica and add it back after the upgrade.
I have now upgraded and deleted TiFlash, and I can no longer add TiFlash or other components. It keeps indicating a directory conflict.