[TiDB Usage Environment] Production Environment
[TiDB Version] 7.5.0
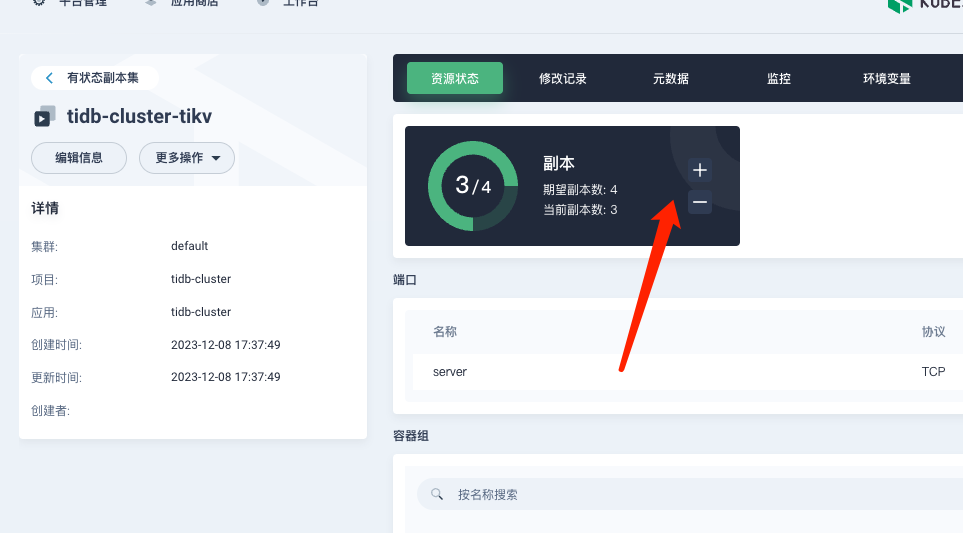
[Reproduction Path] Adding tikv pod node
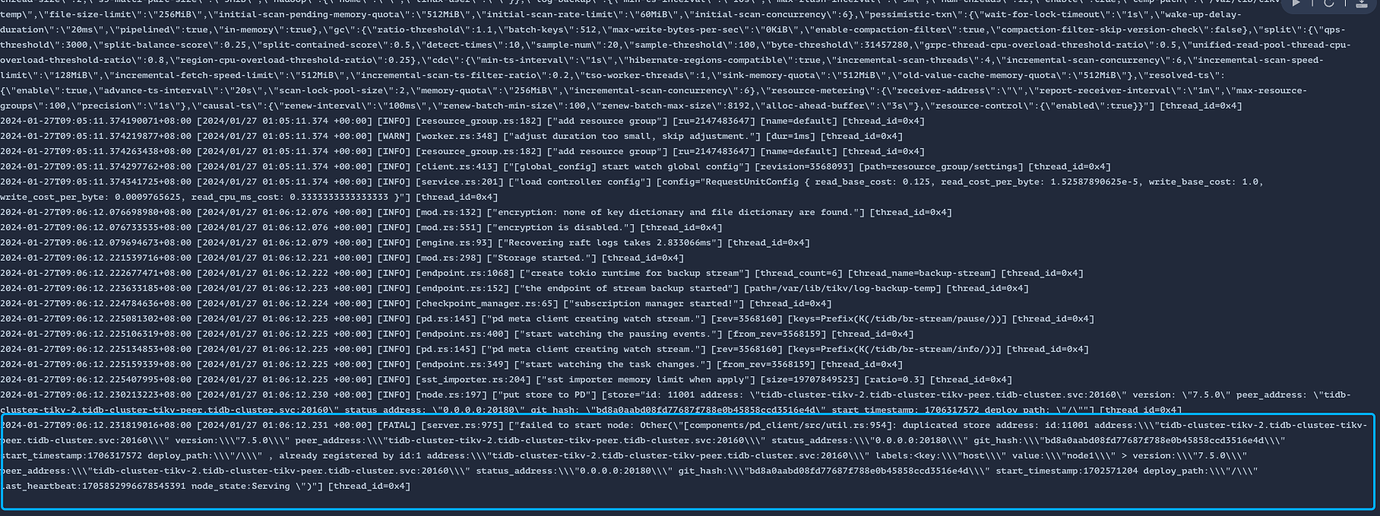
[Encountered Problem: Problem Phenomenon and Impact] ["failed to start node: Other("[components/pd_client/src/util.rs:954]: duplicated store address: id:11001
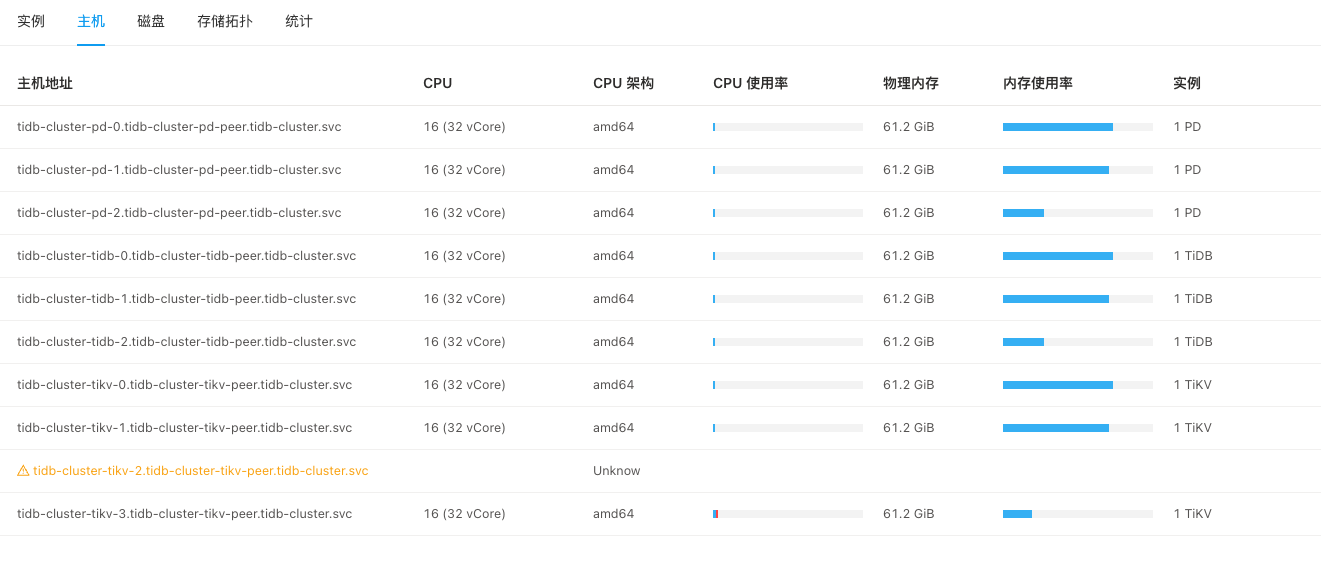
[Resource Configuration] Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
Dear experts, what is the cause of this issue and how can it be resolved?
TiDB Operator version: 1.5.2
TiDB version: 7.5.0
Deployed using k8s+kubesphere
Thank you for the reply!
Before scaling, the tikv-2 node kept reporting the error [“failed to start node: Other(“[components/pd_client/src/util.rs:756]: version should compatible with version 7.5.0, got 5.0.1”)”]. After I specified the image version to 7.5.0, I deleted and recreated the pod several times and also deleted and recreated the persistent volume of the pod. Then this issue occurred.
Thanks for the reply!
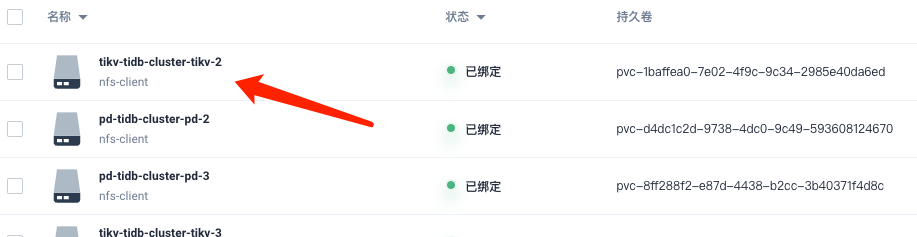
Since it was not deployed using tiup, the node expansion and reduction were done through Kubesphere, and the persistent volumes were manually deleted.
Thank you for the reply!
The node had previously deployed TiKV, and the scaling down did not clean it up completely.
I would like to ask, where is the directory of the old version of TiKV deployed in this (k8s) way stored? Is it in the persistent volume?
The old TiKV was scaled down by directly deleting the PV, right? Then execute store delete xxx to delete the old TiKV. After it becomes a tombstone, the new TiKV will automatically come up.