Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 三节点单副本tidb4000服务启动失败
【TiDB Usage Environment】Local environment, used for storing some historical log data
【TiDB Version】6.5.0
【Reproduction Path】
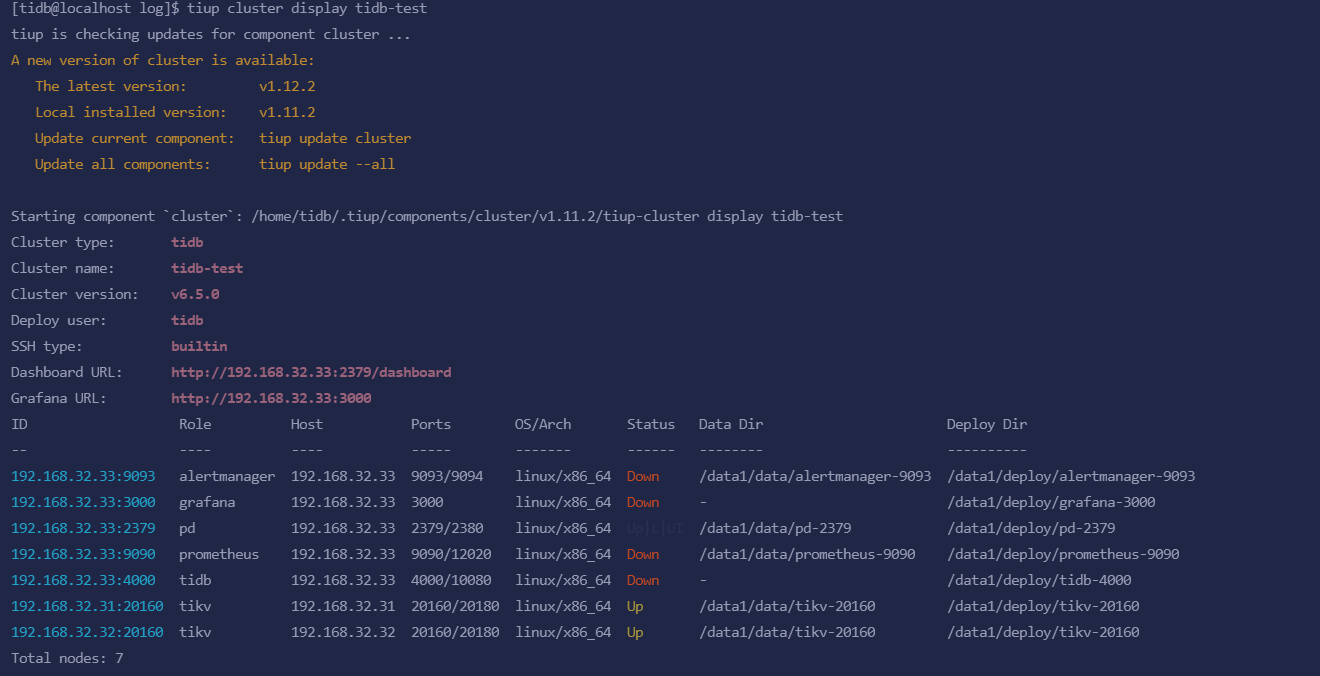
The cluster consists of 3 KVs, 1 PD, and 1 TiDB.
The 3 KVs are 192.168.30.30, 192.168.30.31, and 192.168.30.32, while PD and TiDB are 192.168.30.33.
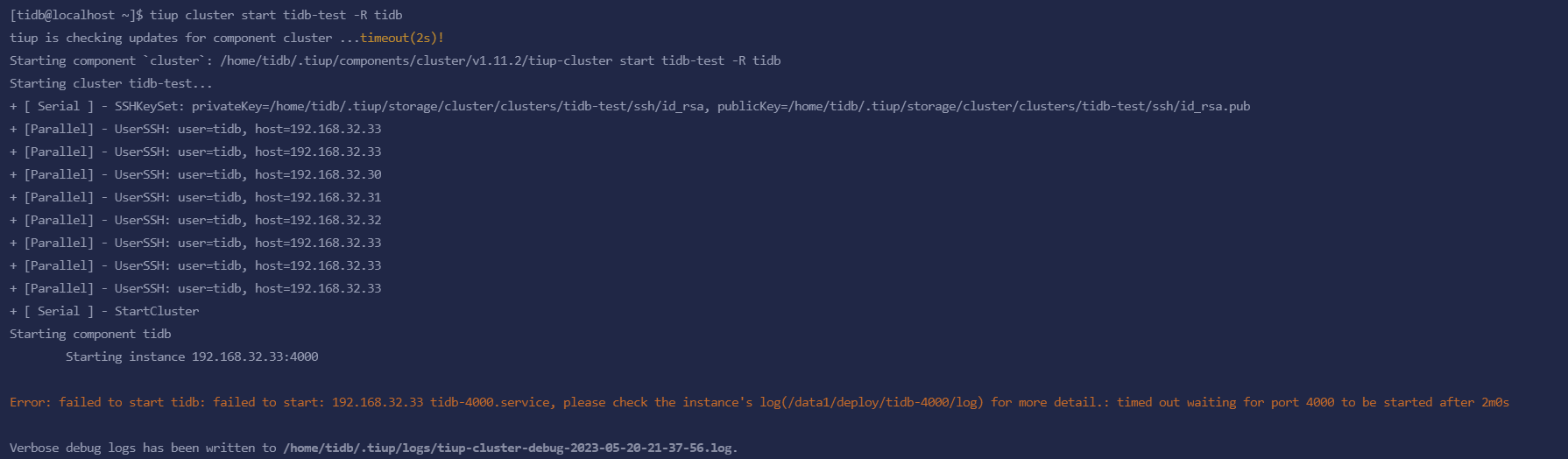
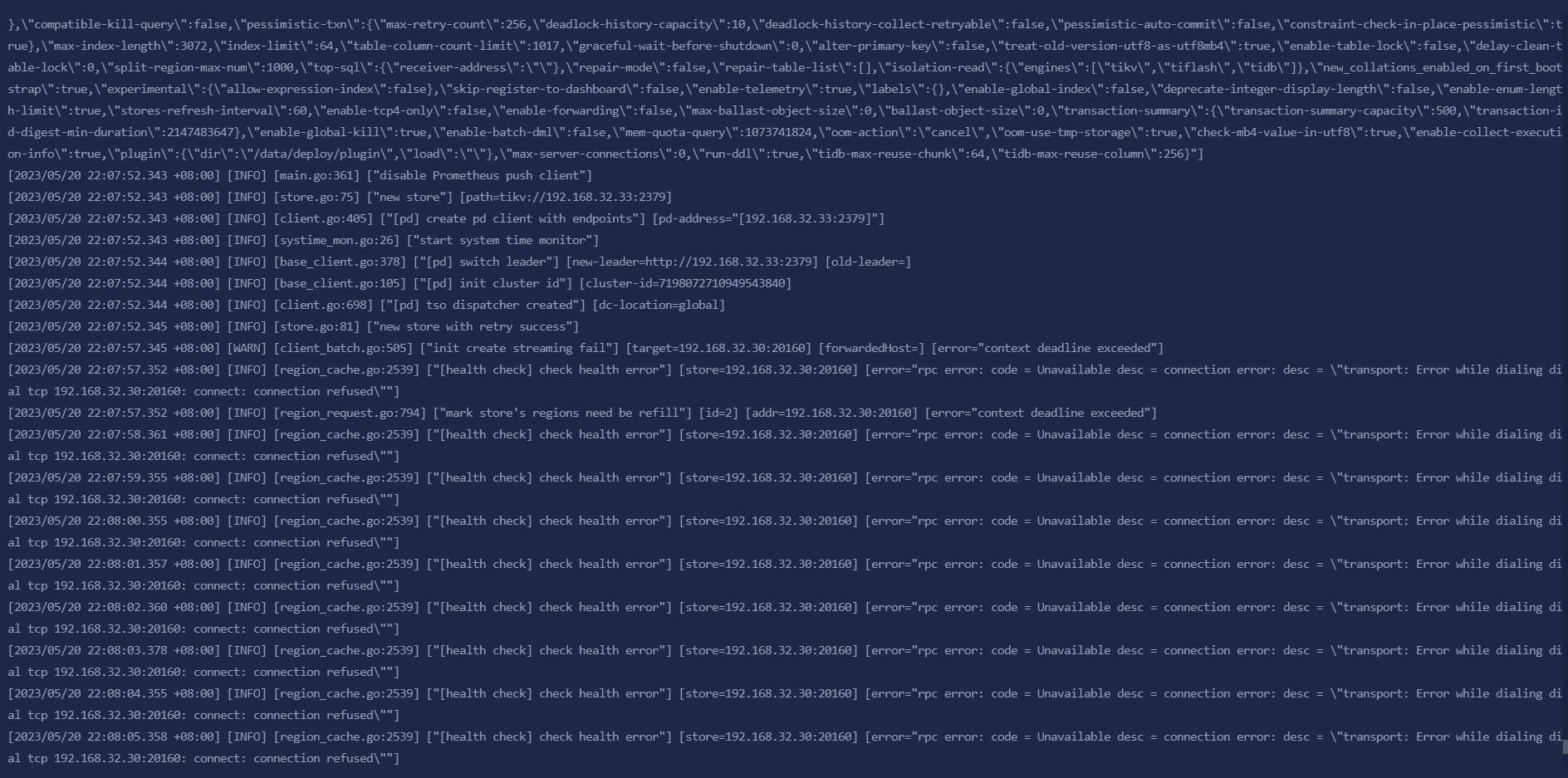
A couple of days ago, the company experienced a power outage, and the server at 192.168.30.30 entered rescue mode. Therefore, we decided to abandon this server and directly killed it by executing tiup cluster scale-in tidb-test --node 192.168.30.30:20160 --force. This operation was successful, but executing tiup cluster start tidb-test -R tidb still failed. After executing tiup cluster stop tidb-test and then tiup cluster start tidb-test, it still didn’t work. If I am determined to abandon the data on the 30 server and only want to retain the data on the remaining two servers to restore the 4000 service, what should I do?
【Encountered Problem: Symptoms and Impact】
【Resource Configuration】Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
【Attachments: Screenshots/Logs/Monitoring】