Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: hashjoin前过滤数据,提高sql查询速度
[TiDB Usage Environment] All environments
[TiDB Version]
[Reproduction Path] SQL query is slow. Example: select * from t left join bt on t.cust_no=bt.cust_no where and bt.cust_name='adad'
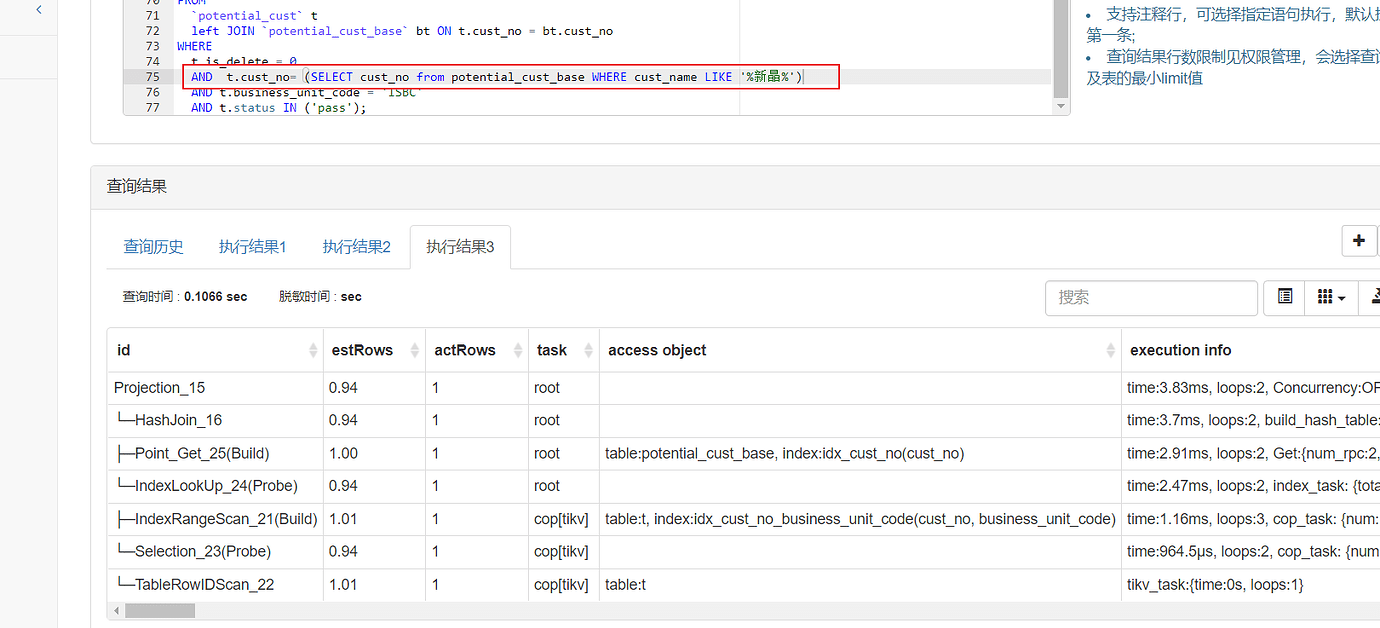
[Encountered Problem: Phenomenon and Impact] The query is slow. Before performing the hash join, the bt table is filtered to match only one row, but it reads all data from the t table for the hash join. Is there a way to first filter the bt table based on the query condition and then perform the hash join, as shown in the second image? However, using = does not meet business requirements, and only IN can be used. Is there any way to optimize this?
[Resource Configuration] Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
[Attachments: Screenshots/Logs/Monitoring]
You can consider using HINT.
First, analyze tables t and bt to see if there are any issues with the execution plan.
Can the LIKE statement here be optimized? Could it be that LIKE is causing the index to be invalid?
Try using /+ INL_JOIN(t)/, provided that the table t has an index starting with the customer number.
Specify the index with hnit
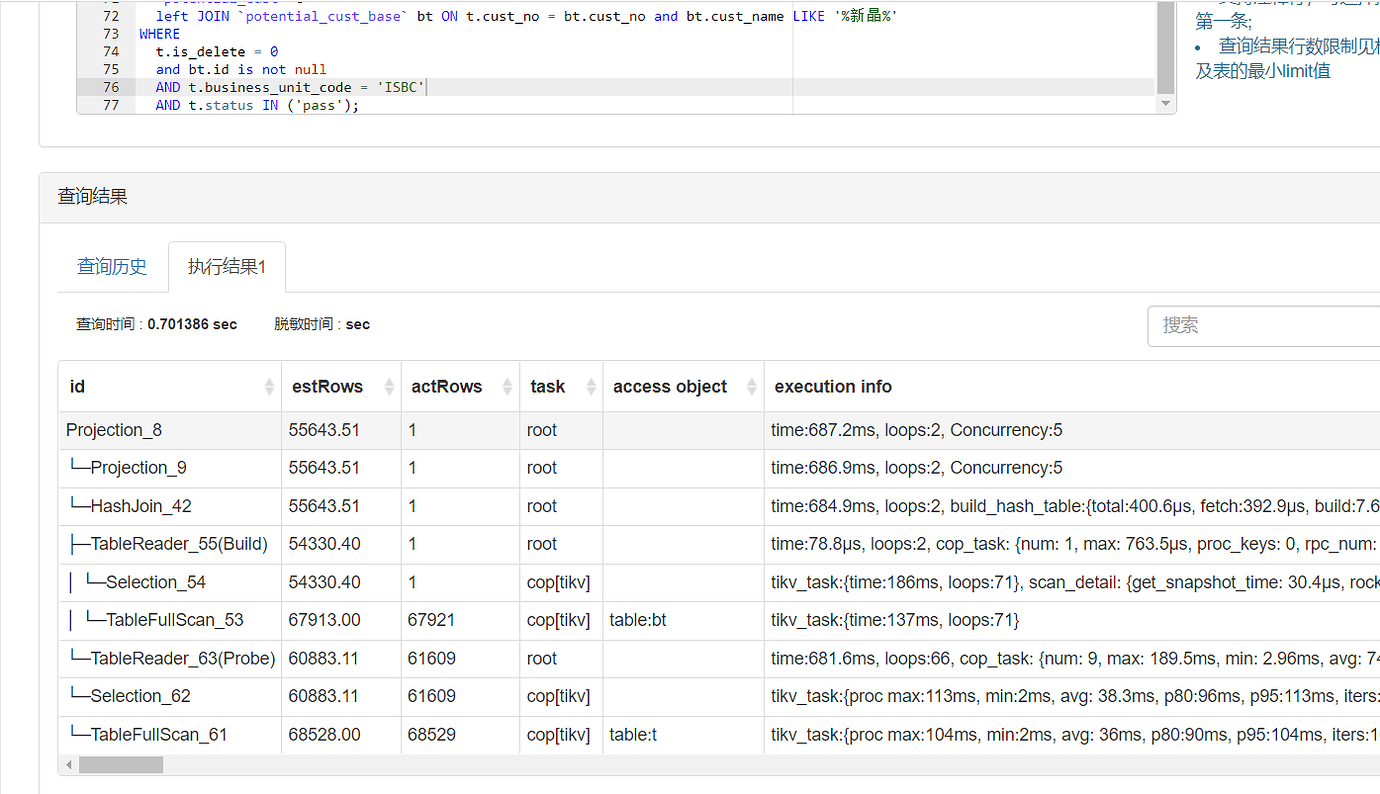
It is recommended to replace left join with inner join.
Because when there are fields from the left join table in the where condition, it is equivalent to an inner join.
The speed of inner join is much faster than left join in practice.
Try replacing the IN function with EXISTS, for example:
WHERE t.is_delete = 0
AND EXISTS (
SELECT 1
FROM potential_cust_base AS pcb
WHERE pcb.cust_no = t.cust_no
AND pcb.cust_name LIKE ‘新 晶%’
)
AND t.business_unit_code = ‘ISBC’
AND t.status IN (‘pass’);
Please also share the table structure. It seems that the index design is not very reasonable.
It doesn’t matter if it fails. The problem is that it returns the full data of table t and joins with table bt.
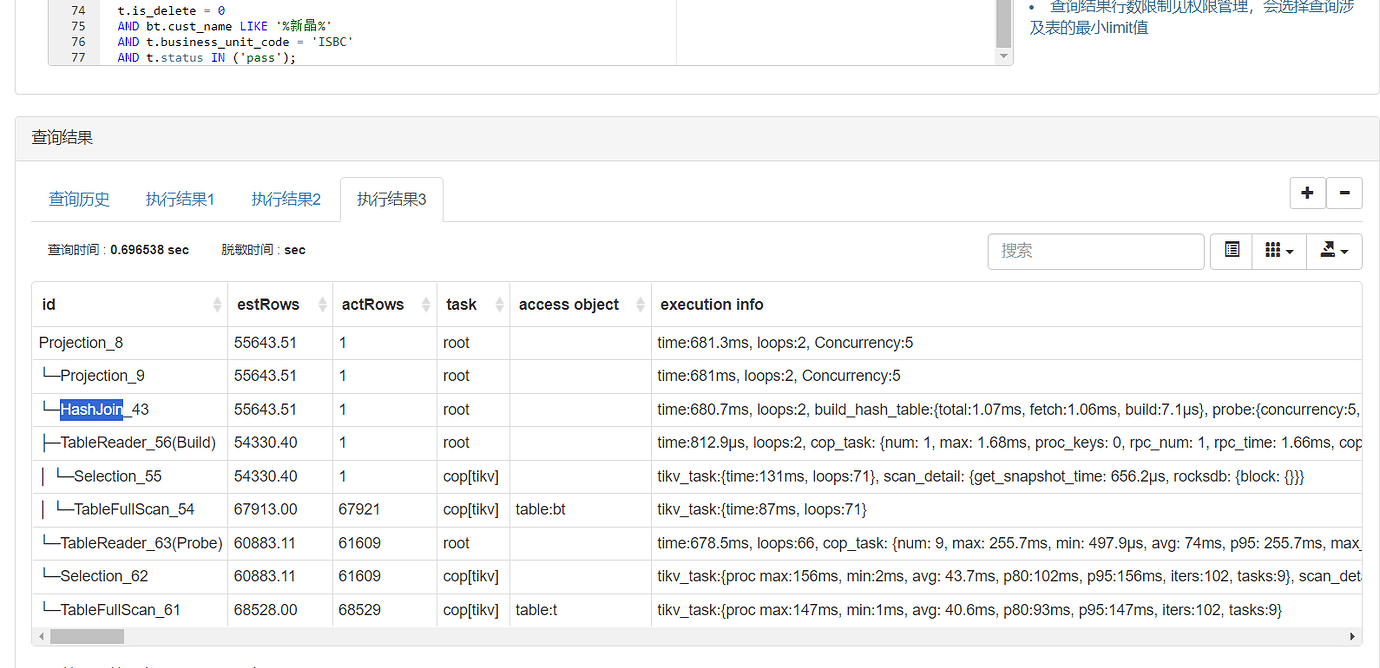
In Figure 1, under the condition of a left join, the 61,000 rows in table t that meet the criteria are definitely all needed, right? The bt table is not performing a full table scan either. The bt table has only one row of data, and the entire tableReader operator execution takes less than 1 millisecond. The bottleneck in the entire execution plan lies in reading the 61,000 rows from table t, not in the bt table.
I tried it, but it still doesn’t work  . Anyway, filtering data before the join would be much faster.
. Anyway, filtering data before the join would be much faster.
Yes, the same applies to joins. The issue is whether the tableReader for table t can filter based on the qualifying data from table bt instead of returning everything for the join. I’m starting to wonder if the underlying database algorithm isn’t optimized enough.
The root cause is not the issue with the index.
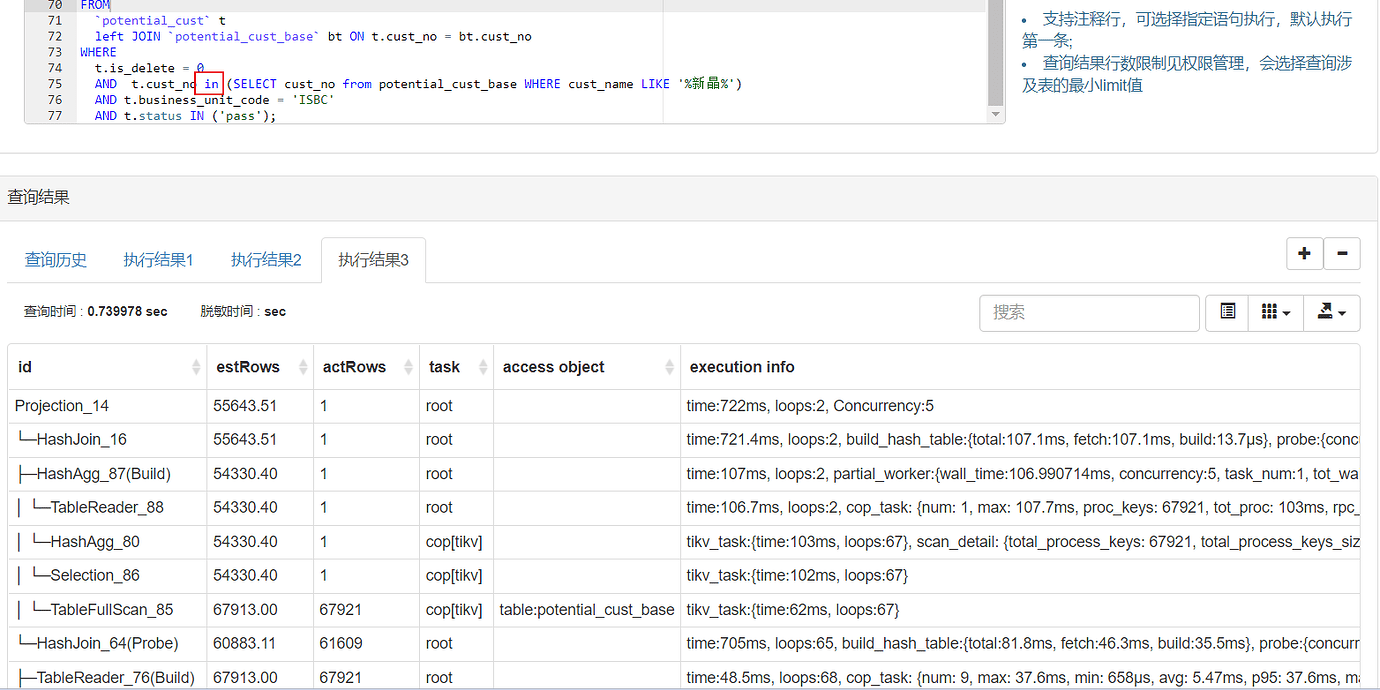
in and exists are equivalent.
I roughly understand your point. You mean that the bt table should first find the associated id of the t table, and then directly scan the t table with the conditions, instead of performing a hash join.
The reason why the optimizer didn’t do this, I feel, is due to the statistics. In Figure 1, based on the conditions of your bt table, the estimated data is 54,000.
When using the = join, the estimated data becomes 1 row. Then the query meets the expectation.
When using in, the statistics are still 54,000, so the execution time becomes longer again.
The solution, I feel, is to create an index and then try the index-join hint. It would be more reliable.
Yes, this way it’s faster. Thank you, master!
Yes, because filtering before executing the SQL will significantly reduce the amount of data scanned. Therefore, before execution, try to filter out invalid data using conditions to reduce the scanning scope.
Yes, the question is how to filter it