Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: Flinksql读取tidb数据丢失
[TiDB Usage Environment]
Production Environment
[TiDB Version]
6.1.0
[Encountered Problem]
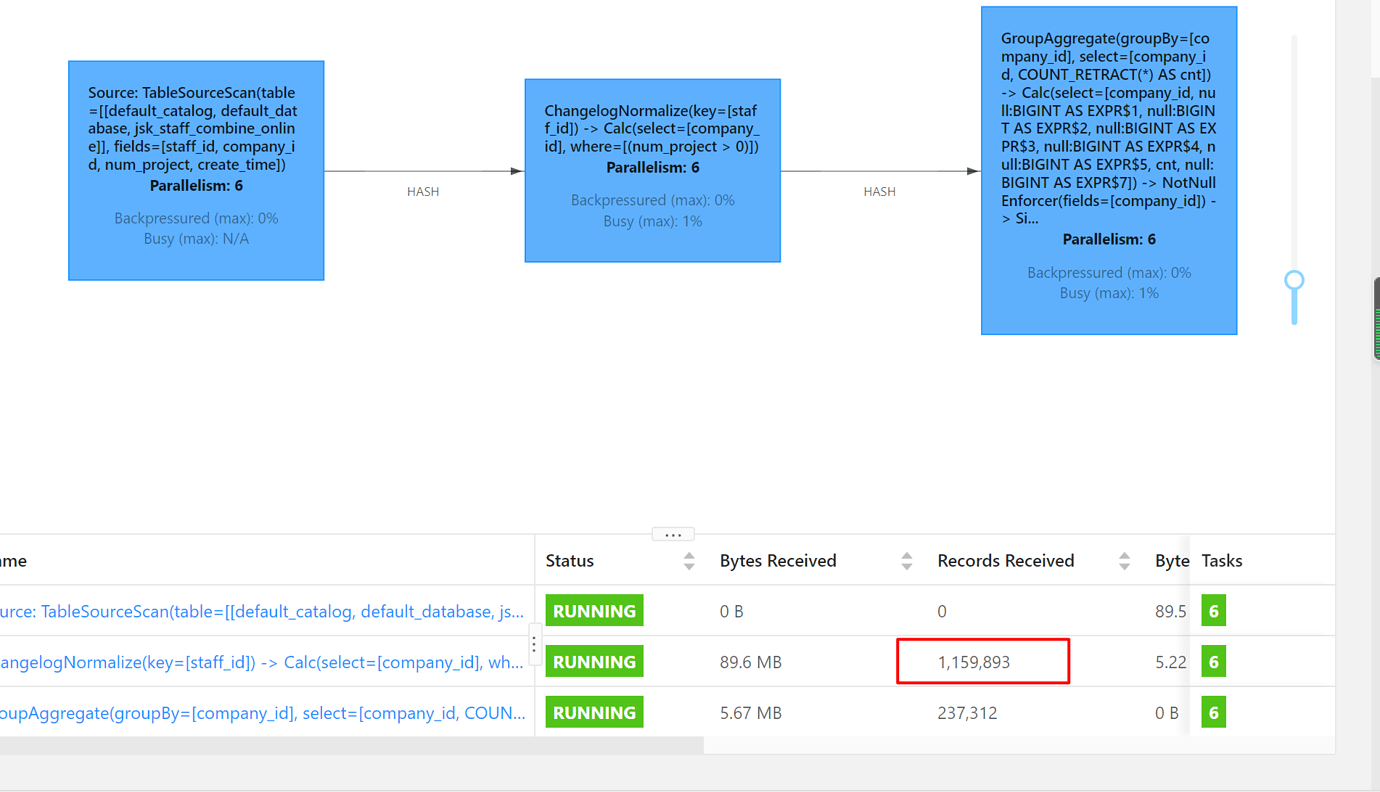
When Flink SQL reads the TiDB table and performs aggregation counting, it is found that the data read from the source table is significantly less (the source table has over 10 million records), resulting in incorrect aggregation results.
[Attachments]
What value is given to scan.startup.mode?
If you expect a full table scan, the Flink state can’t hold that much, and streaming processing isn’t really designed for that…
The default initial state stored in RocksDB, even if used only to synchronize table data, such as TiDB->TiDB, has the same issue of only synchronizing part of the data.
It’s hard to help you analyze without knowing your specific scenario.
Is this happening with all tables or just one of them?
I tried several tables and encountered the same issue.
Requirement: Count the data in the table grouped by company ID.
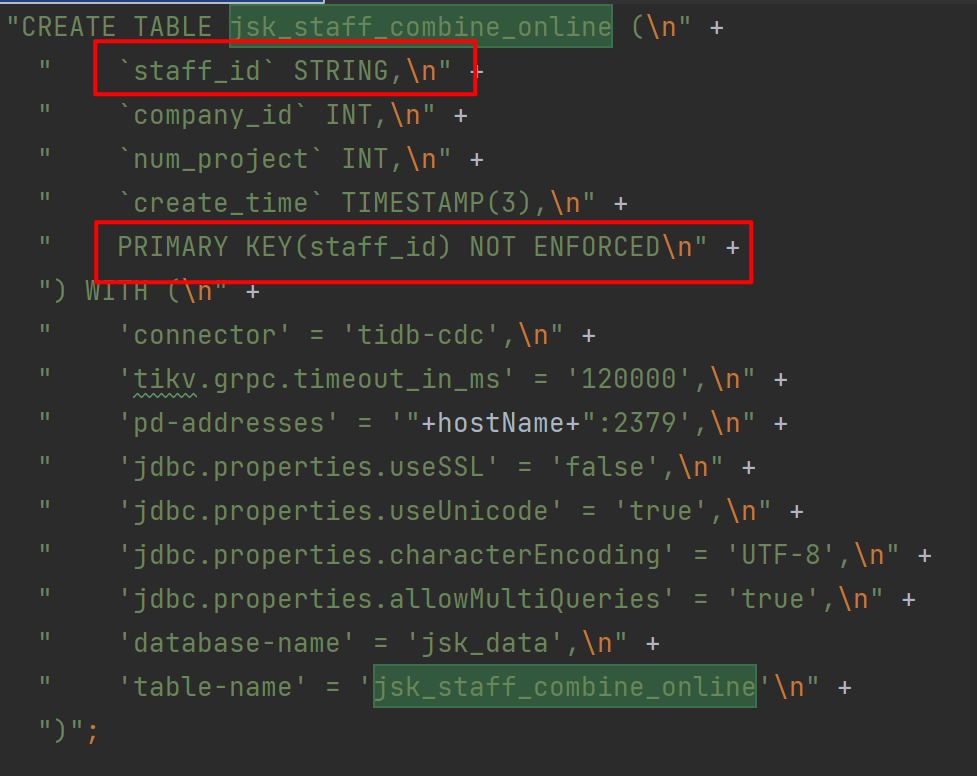
Table creation statement:
CREATE TABLE jsk_staff_combine_online (
`staff_id` STRING,
`company_id` INT,
`num_project` INT,
PRIMARY KEY(staff_id) NOT ENFORCED
) WITH (
'connector' = 'tidb-cdc',
'tikv.grpc.timeout_in_ms' = '120000',
'pd-addresses' = '"+hostName+":2379',
'jdbc.properties.useSSL' = 'false',
'jdbc.properties.useUnicode' = 'true',
'jdbc.properties.characterEncoding' = 'UTF-8',
'jdbc.properties.allowMultiQueries' = 'true',
'database-name' = 'jsk_data',
'table-name' = 'jsk_staff_combine_online'
)
Insert statement:
insert into jsk_dws_count_professional(company_id,team_leader)
select company_id, count(*) as cnt
from jsk_staff_combine_online
where num_project > 0
group by company_id
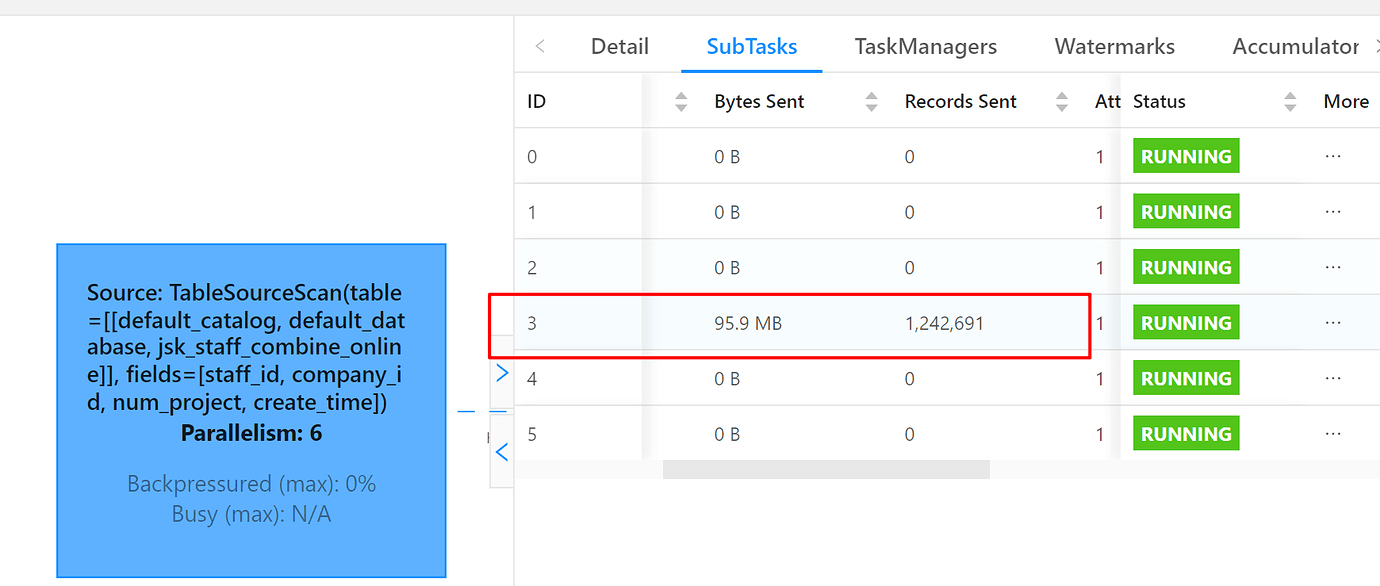
Then I tried synchronizing two tables. The jsk_staff_combine_online table was synchronized to the test table, but the result was the same. Only 1 million+ records were synchronized, and only one source task had data.
Insert statement:
insert into test_jsk_staff_combine_online(staff_id, company_id, num_project)
select staff_id, company_id, num_project
from jsk_staff_combine_online
What about 1-to-1 direct synchronization? Is the data still incorrect?
What are the characteristics of the lost data? Are there any errors or warnings in the logs?
It’s still not right, I can’t see any error messages at all.
There are no errors because the primary key is UUID, so the characteristics of data loss are not easily noticeable.
Are the data write results inconsistent now? Or are the query results consistent?