Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: GC数据不回收
[TiDB Usage Environment] Online
[TiDB Version] 5.0.6
[Encountered Problem]
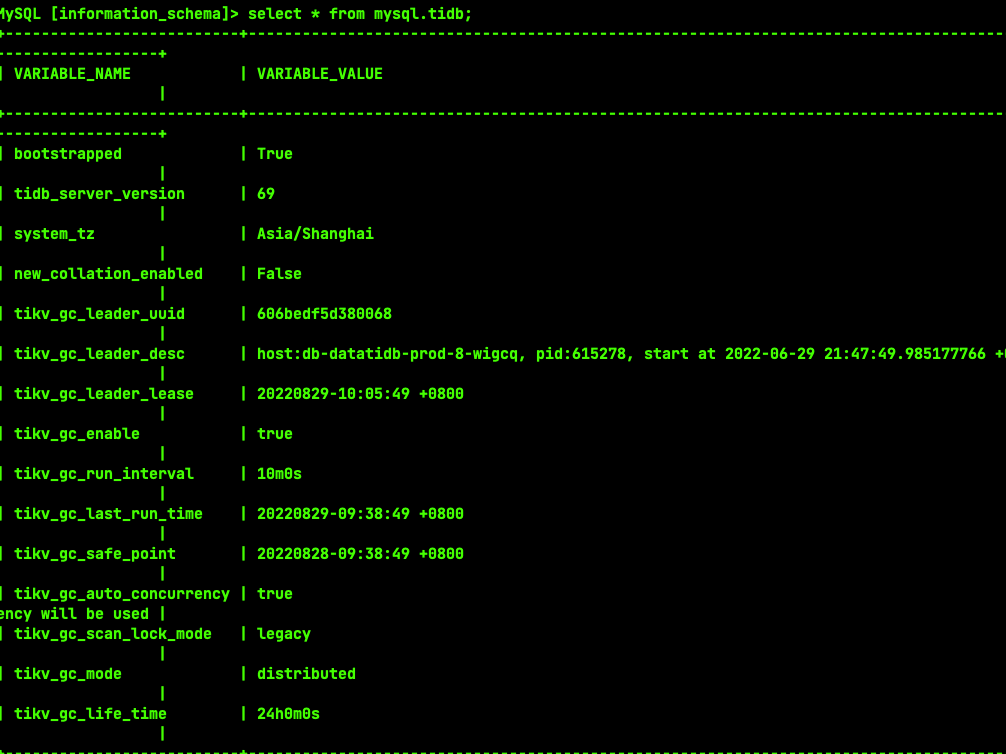
The tidb log reports “gc work is too busy”. The gc safe time query is normal, but currently, data is not being reclaimed, leading to rapid data growth. I don’t know how to solve this issue.
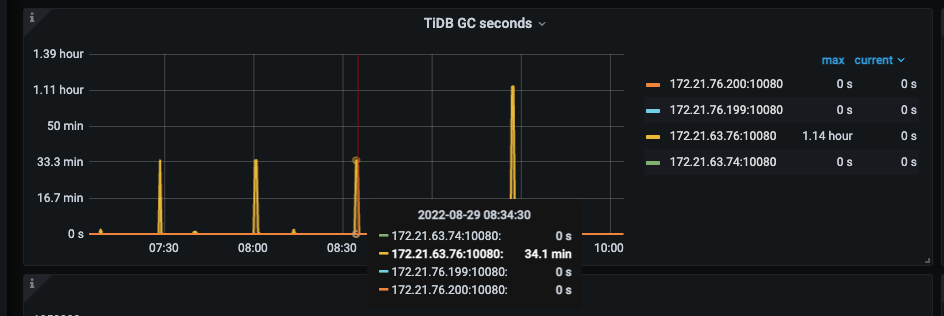
However, each GC takes 34 minutes to 1 hour.
The business performs around 10 truncates every 5 minutes, but no unsafe destroy range is observed.
[Reproduction Path]
What operations were performed that led to the problem
[Problem Phenomenon and Impact]
[Attachment]
tikv_gc_lift_time 24 hours is too long…
Setting tikv_gc_life_time to be slightly longer than the maximum query time is sufficient, around 1 hour should be fine.
Check the mysql.gc_delete_range and gc_delete_range_done tables, which record the progress of GC after truncate/drop. If there is no cleanup, it is likely that you have encountered a bug.
TiDB 节点大量[gc worker] delete range failed 报错信息 - #6,来自 h5n1 - TiDB 的问答社区…
Is there any other way besides upgrading~~
Find time to manually compact using tikv-ctl
tikv-ctl --host tikv_ip:port compact -d kv -c write
tikv-ctl --host tikv_ip:port compact -d kv -c default
tikv-ctl --host tikv_ip:port compact -d kv -c write --bottommost force
tikv-ctl --host tikv_ip:port compact -d kv -c lock --bottommost force
Could you please explain the purpose and approximate risks of this operation? I searched the documentation but it wasn’t explained in detail.
Execution time is long, and resource consumption is relatively high.
The data volume might be too large for GC to clean up.
Will this recycle the previous GC data? How long will it take to execute approximately 2T of data on a single TiKV?
Hmm, it looks like it can’t be cleaned up. Are you also using compact?
This depends on the system performance. You can try it during off-peak hours.
There isn’t really a low peak; tasks are heavier in the evening, and data queries are more important in the morning!  Maybe there’s only a low peak for 2 hours at noon, but I’m afraid it won’t be enough.
Maybe there’s only a low peak for 2 hours at noon, but I’m afraid it won’t be enough.
Let me run it in my environment and see the time.
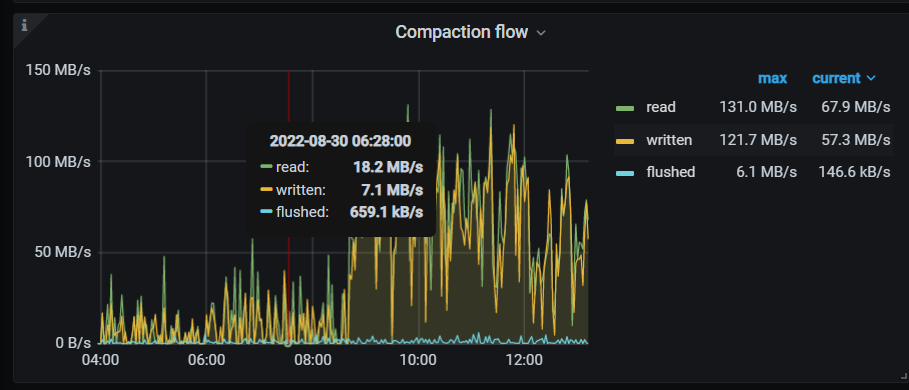
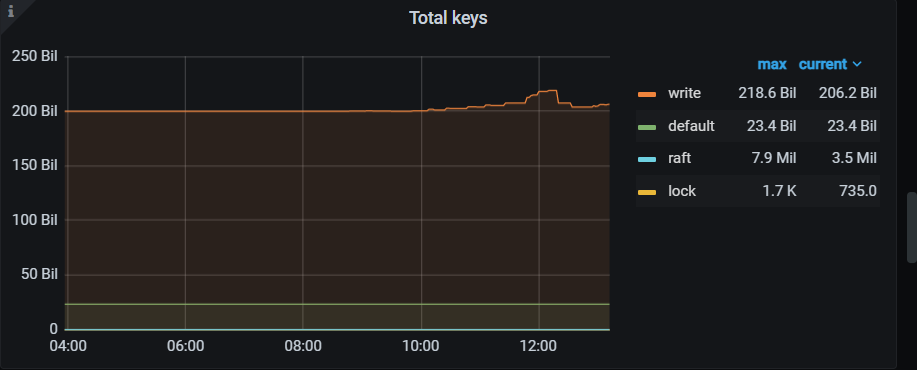
I have completed running 5.4T on 5 TiKV SAS disks, with only inserts and no updates/deletes, so the space hasn’t been released. Below are the time consumption and resource usage details. Without specifying --threads, the disk IO is fine, but the RocksDB CPU utilization has increased.
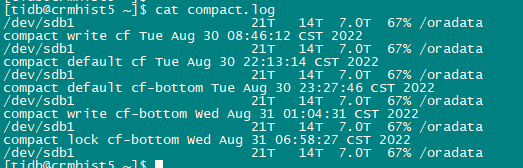
Thank you, master. It seems that your cluster took about 22 hours. Here are a few screenshots from my side. I’m worried about affecting the cluster. If it impacts the cluster during execution, can it be terminated?
You should just kill it. There’s a --threads option, which defaults to 8.
Or, to put it another way, which version upgrade can solve this problem? Are there any additional risks with upgrading? The documentation says it’s just one command, and I’ve tried upgrading a small cluster. I’m not sure if there are any pitfalls or additional issues with a large cluster.
I don’t know exactly which version can solve it, you can compare the release date of your current version. I recommend 5.2.4.
Upgrading can refer to the following documentation: