Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: gc 不能正常工作
【TiDB Usage Environment】Production Environment
【TiDB Version】4.0
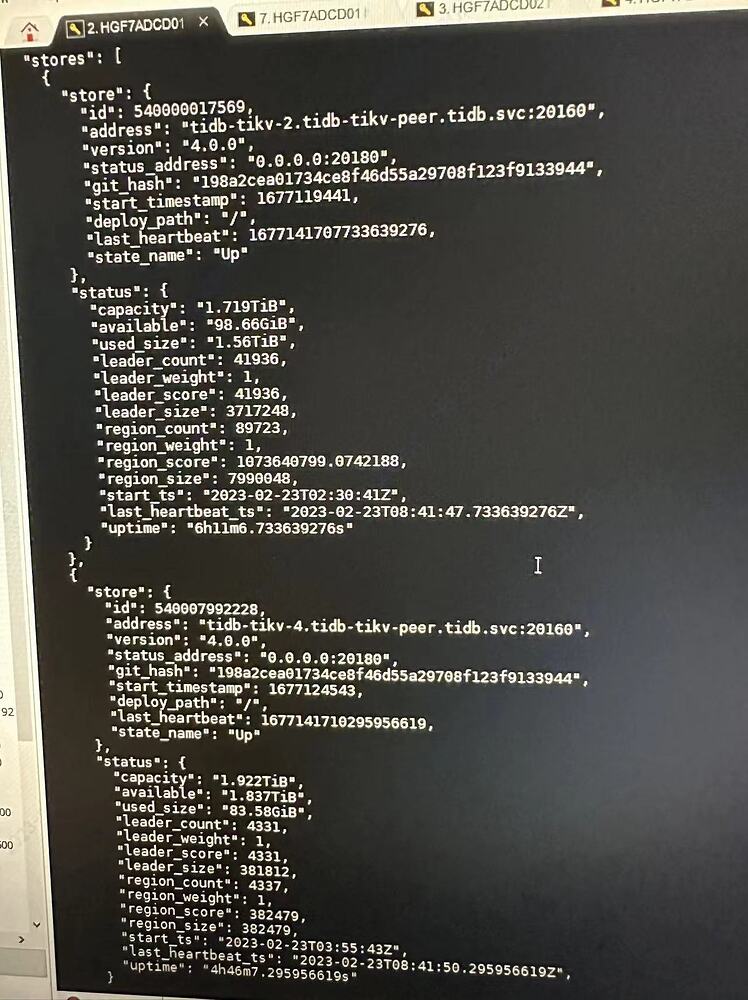
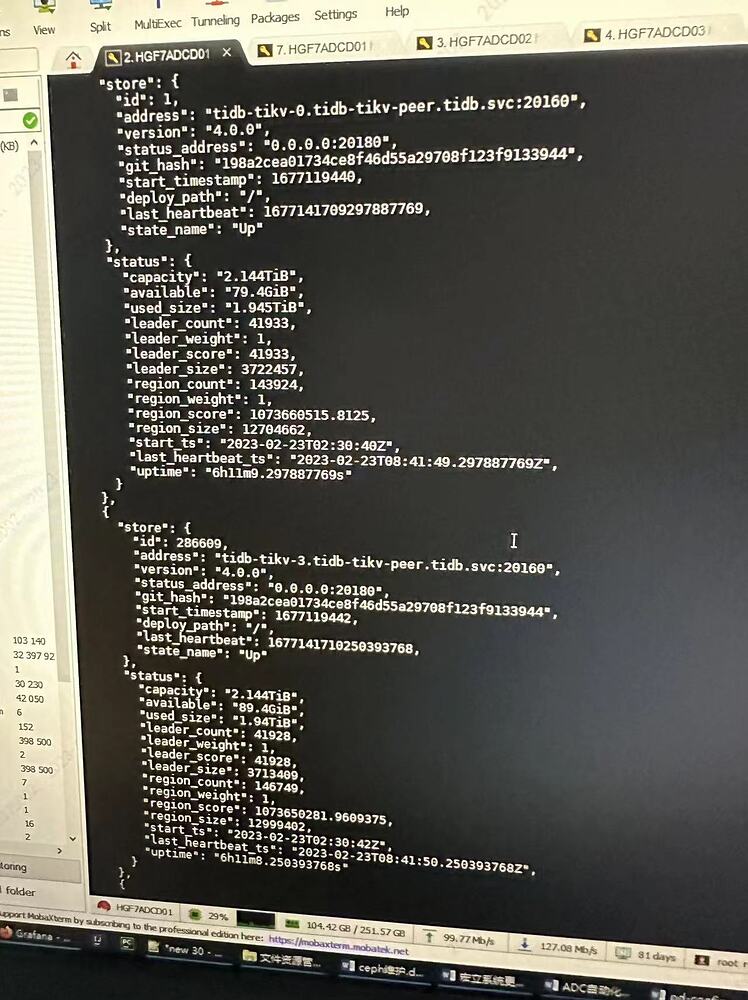
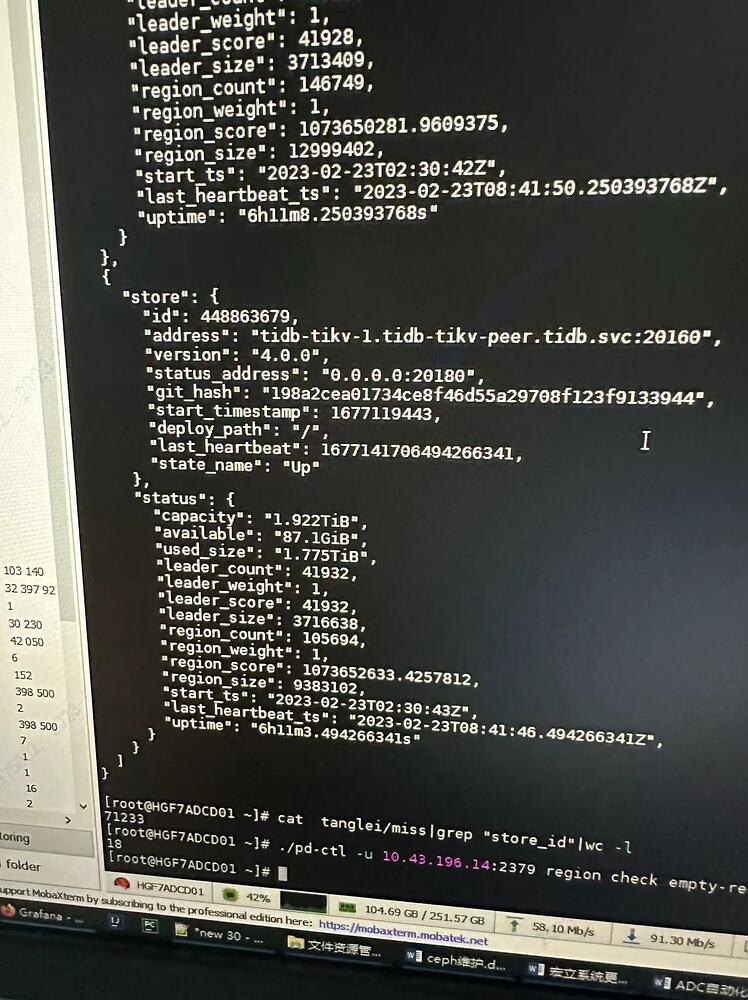
【Reproduction Path】5 TiKV nodes, mistakenly deleted the directories of 2 nodes, one node had issues so it was removed and became offline. I want it to become tombstone status and then delete it.
【Encountered Issues: Symptoms and Impact】
【Resource Configuration】5 TiKV nodes, 3 PD nodes, 2 TiDB nodes
TiKV 2T/node
【Reproduction Path】5 TiKV nodes, mistakenly deleted the directories of 2 nodes, one node had issues, later space was insufficient, truncated a large table, and GC has not been executed
【Encountered Issues: Symptoms and Impact】
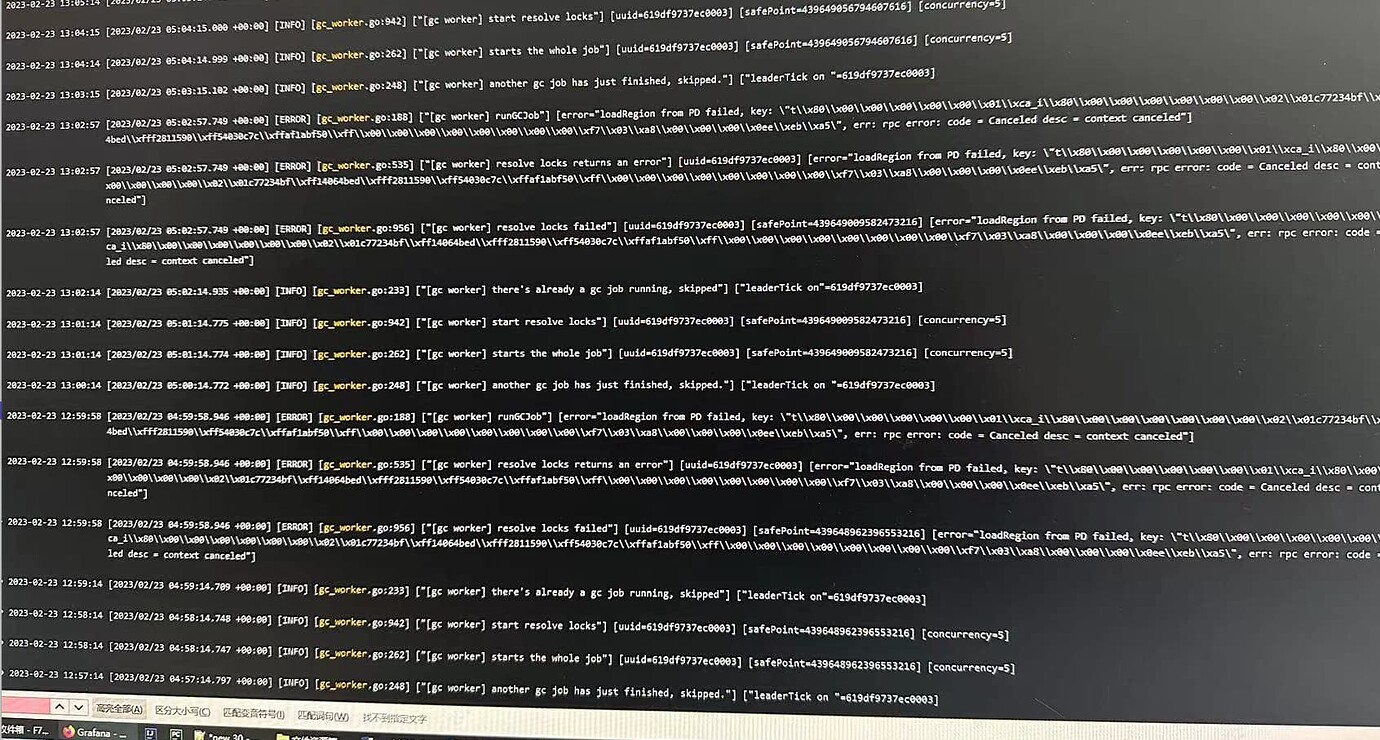
GC failed at resolve locks
[ERROR] [gc_worker.go:787] ["[gc worker] resolve locks failed"] [uuid=5cb549336b40001] [safePoint=417520979457343488] [error="loadRegion from PD failed, key: \""t\"\"x80\"\"x00\"\"x00\"\"x00\"\"x00\"\"x01m\"\"xcb_r\"\"xf8\"\"x00\"\"x00\"\"x00\"\"x01\"\"x8f\"\"xd7;\"", err: rpc error: code = Canceled desc = context canceled"] [errorVerbose="loadRegion from PD failed, key: \""t\"\"x80\"\"x00\"\"x00\"\"x00\"\"x00\"\"x01m\"\"xcb_r\"\"xf8\"\"x00\"\"x00\"\"x00\"\"x01\"\"x8f\"\"xd7;\"", err: rpc error: code = Canceled desc = context canceled\"ngithub.com/pingcap/tidb/store/tikv.(*RegionCache).loadRegion\"n\"tgithub.com/pingcap/tidb@/store/tikv/region_cache.go:621\"ngithub.com/pingcap/tidb/store/tikv.(*RegionCache).findRegionByKey\"n\"tgithub.com/pingcap/tidb@/store/tikv/region_cache.go:358\"ngithub.com/pingcap/tidb/store/tikv.(*RegionCache).LocateKey\"n\"tgithub.com/pingcap/tidb@/store/tikv/region_cache.go:318\"ngithub.com/pingcap/tidb/store/tikv.(
Read an article suggesting to modify the region-cache-ttl parameter