Industry: Advertising
Authors:
Transcreator: Caitin Chen; Editor: Tom Dewan
58.com is China’s leading online marketplace for classifieds covering various categories, such as jobs, real estate, automotive, financing, used goods, and local services. Merchants and consumers can publish their advertisements on our online platform so that they can connect, share information, and conduct business. By the end of 2018, we had more than 500 million users, and our total revenue in 2019 was nearly US $2.23 billion.
As our businesses grew, large amounts of data flooded into our databases. But standalone MySQL databases couldn’t store so much data, and MySQL sharding was an undesirable solution. To achieve MySQL high availability, we needed an external tool. To perform Online Analytical Processing (OLAP), we had to use complicated and tedious extract, transform, load (ETL) jobs. We looked for a scalable, easy-to-maintain, highly available database to solve these issues.
After an investigation, we adopted TiDB, an open-source, distributed, Hybrid Transactional/Analytical Processing (HTAP) database. Now, our production environment has 52 TiDB clusters that store 160+ TB of data, with 320+ servers running in 15 applications. To maintain such large-scale clusters, we only need two DBAs.
In this post, we’ll deep dive into why we migrated from MySQL to TiDB and how we use TiDB to scale out our databases, perform real-time analytics, and achieve high availability.
Our pain points
We stored our private cloud monitoring data in MySQL. Because our data size was huge, we needed to regularly clean our tables. This was a lot of work for our DBAs.
When we used MySQL, we encountered these problems:
- A standalone MySQL database has limited capacity. It can’t store enough data to meet our needs.
- Sharding was troublesome. At 58.com, we didn’t have a middleware team, and our developers needed to operate and maintain sharding scenarios by themselves. After we sharded our database, it took a lot of work to aggregate the data.
- To perform OLAP analytics, we must do complex and boring ETL tasks. An ETL process was time-consuming, and this hindered our ability to do real-time data analytics.
- To achieve high availability, MySQL relies on an external tool. We used Master High Availability (MHA) to implement MySQL high availability, but it increased our maintenance cost.
- In the primary-secondary database framework, MySQL has high latency on the secondary database. When we performed data description language (DDL) operations, high latency occurred in the secondary database. This greatly affected real-time reads.
- A standalone MySQL database couldn’t support large amounts of writes. When our writes in a standalone MySQL database reached about 15,000 rows of data, we encountered a database performance bottleneck.
Therefore, we looked for a new database solution with the following capabilities:
- It has an active community. If its community is not active, when we find issues or bugs, we can’t get solutions.
- It’s easy to operate and maintain.
- It can solve our current problems, such as issues brought by sharding and lots of writes and deletes.
- It is suitable for many application scenarios and provides multiple solutions.
Why we chose TiDB, a NewSQL database
TiDB is an open-source, cloud-native, distributed SQL database built by PingCAP and its open-source community. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability. It’s a one-stop solution for both Online Transactional Processing (OLTP) and OLAP workloads. You can learn more about TiDB’s architecture here.
We adopted TiDB, because it met all our requirements for the database:
- TiDB uses distributed storage, and it can easily scale out. We no longer need to worry that a single machine’s capacity is limited.
- TiDB is highly available. We don’t need to use an additional high-availability service. So TiDB helps us eliminate extra operation and maintenance costs.
- TiDB supports writes from multiple nodes. This prevents a database performance bottleneck when we write about 15,000 rows of data to a single node.
- TiDB provides data aggregation solutions for sharding. With TiDB, we no longer need to shard databases.
- TiDB has a complete monitoring system. We don’t need to build our own monitoring software.
How we’re using TiDB as an alternative to MySQL
So far, we’ve deployed 52 TiDB clusters in the production environment to store 160+ TB of data, with 320+ servers running in 15 applications. Our databases have 5.5 billion daily visits. To maintain such large-scale clusters, we only need two DBAs, and, meanwhile, they’re also managing MySQL databases.
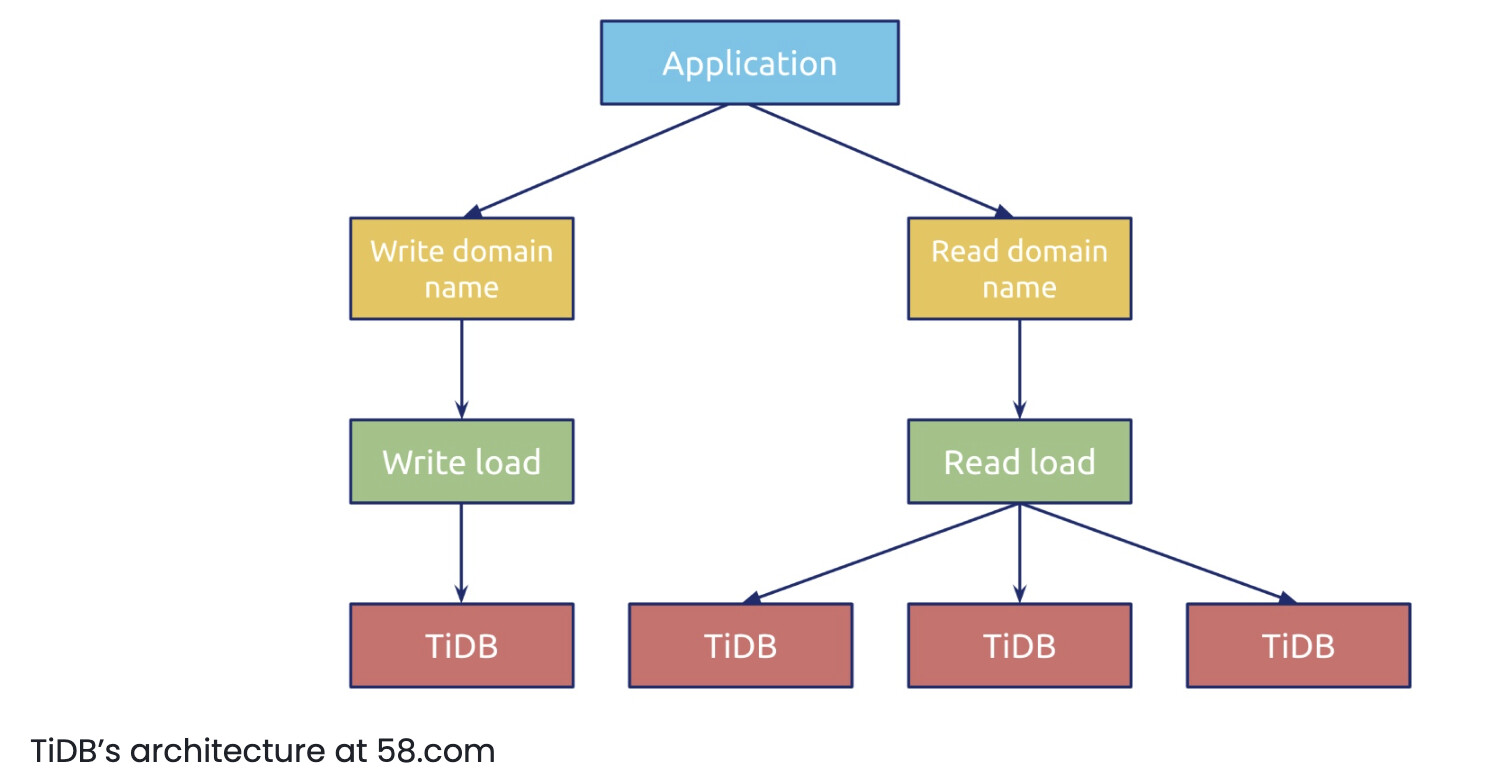
TiDB’s architecture at 58.com
In a TiDB cluster, our application separates read and write domain names, and the backend uses load balancers to balance read and write loads. By default, a single cluster has four TiDB nodes, one for writes and three for reads. If write performance becomes a bottleneck, we can add TiDB nodes.
From TiDB 2.0 to TiDB 4.0.2
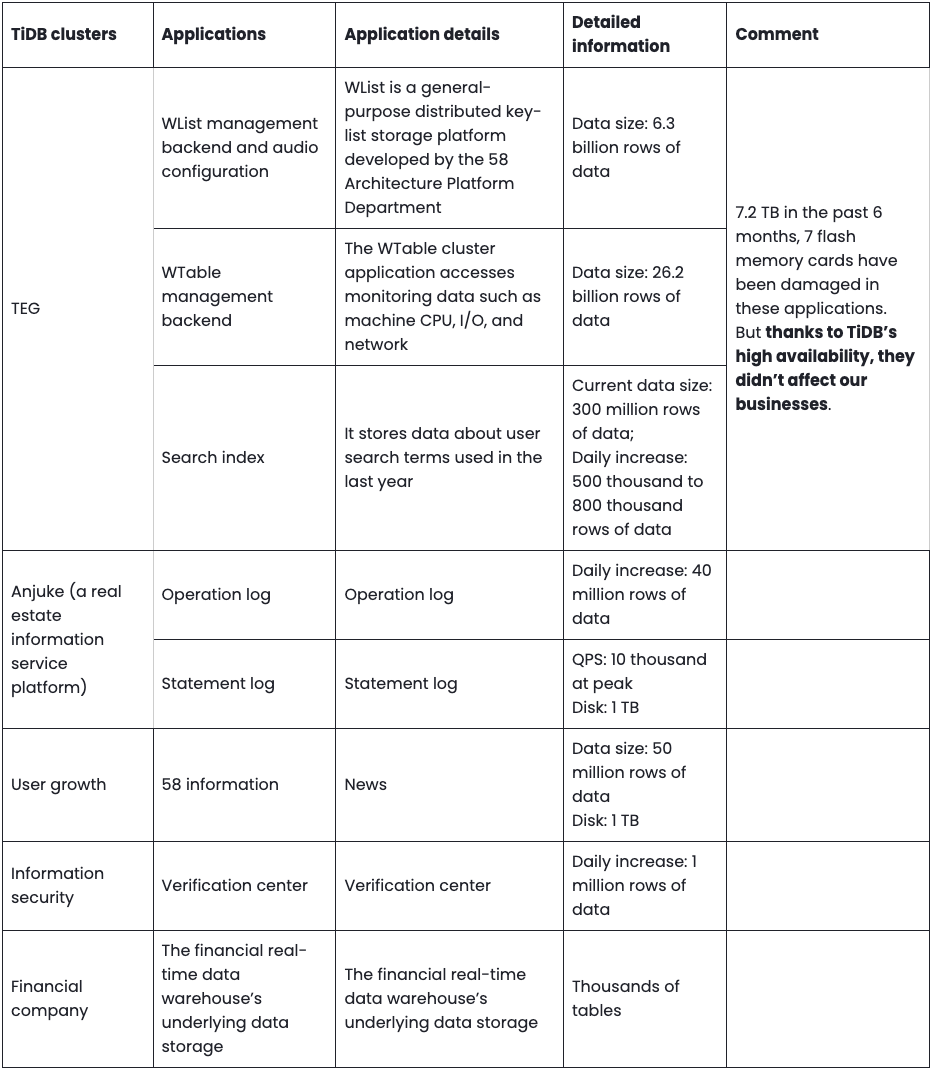
The following table summarizes how we’ve used TiDB over the years and how our reliance on TiDB has grown.

Our applications running on TiDB
We’re running 242 TiDB databases in 15 applications. To name a few:
Conclusion
Thanks to TiDB’s horizontal scalability, high availability, and HTAP capabilities, we could say goodbye to troublesome MySQL sharding and time-consuming ETL. It’s so easy to scale out our databases and maintain such large-scale clusters.
Now, at 58.com, we use databases including MySQL, Redis, MongoDB, Elasticsearch, and TiDB. We receive about 800 billion visits per day. We have 4,000+ clusters, with 1,500+ physical servers.
If you have any questions or you’d like to learn more about our experience with TiDB, you can join the TiDB community on Slack.
![]() Ready to supercharge your data integration with TiDB? Join our Discord community now!
Ready to supercharge your data integration with TiDB? Join our Discord community now! ![]() Connect with fellow data enthusiasts, developers, and experts to: Stay Informed: Get the latest updates, tips, and tricks for optimizing your data integration. Ask Questions: Seek assistance and share your knowledge with our supportive community. Collaborate: Exchange experiences and insights with like-minded professionals. Access Resources: Unlock exclusive guides and tutorials to turbocharge your data projects. Join us today and take your data integration to the next level with TiDB!
Connect with fellow data enthusiasts, developers, and experts to: Stay Informed: Get the latest updates, tips, and tricks for optimizing your data integration. Ask Questions: Seek assistance and share your knowledge with our supportive community. Collaborate: Exchange experiences and insights with like-minded professionals. Access Resources: Unlock exclusive guides and tutorials to turbocharge your data projects. Join us today and take your data integration to the next level with TiDB!