Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 大家遇到过同一个Tidb集群中,不同的tidb-server,执行同一条sql语句,执行计划不一样
【TiDB Usage Environment】Production Environment / Testing / PoC
【TiDB Version】
【Reproduction Path】What operations were performed that led to the issue
【Encountered Issue: Problem Phenomenon and Impact】
【Resource Configuration】Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
【Attachments: Screenshots / Logs / Monitoring】
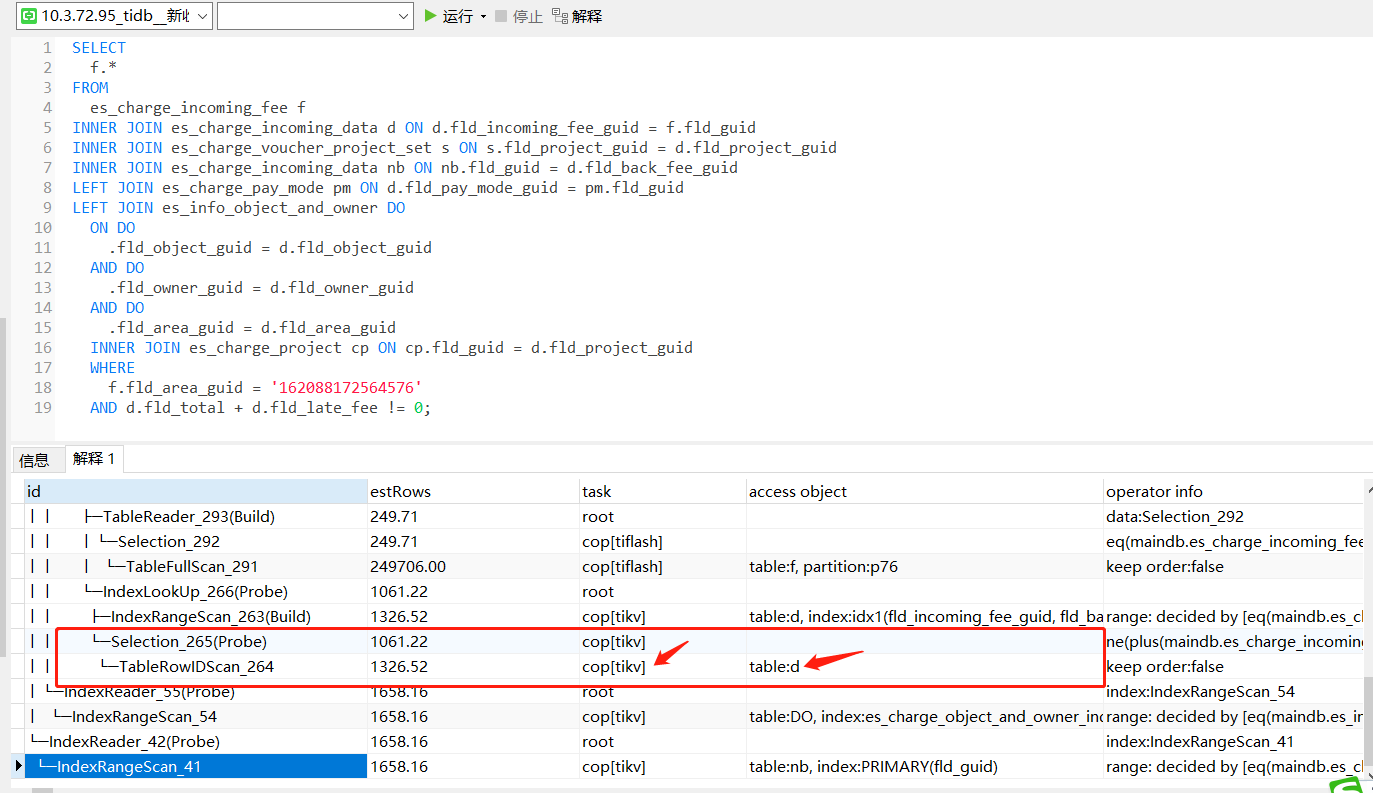
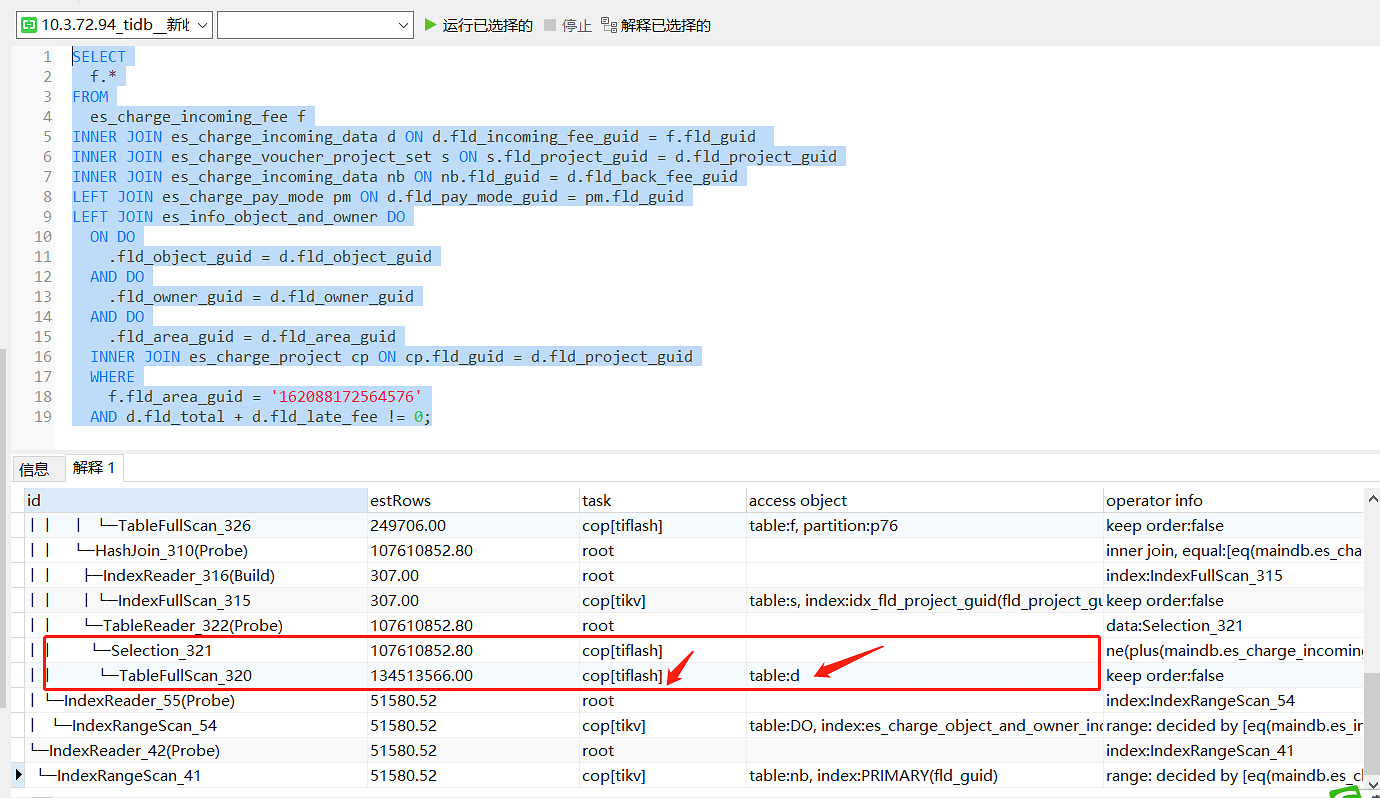
Has anyone encountered a situation where different tidb-servers in the same TiDB cluster execute the same SQL statement but have different execution plans?
Could you provide the two execution plans? Did they go to TiKV and TiFlash respectively?
Post the execution plan immediately.
Check if the configurations of the two TiDB servers are different. Did one configure TiFlash and the other didn’t?
The configuration is the same.
show variables like ‘%tidb_isolation_read_engines%’;
Take a look.
The cluster hasn’t been upgraded, right?
I haven’t upgraded before; I directly installed version v6.5.0.
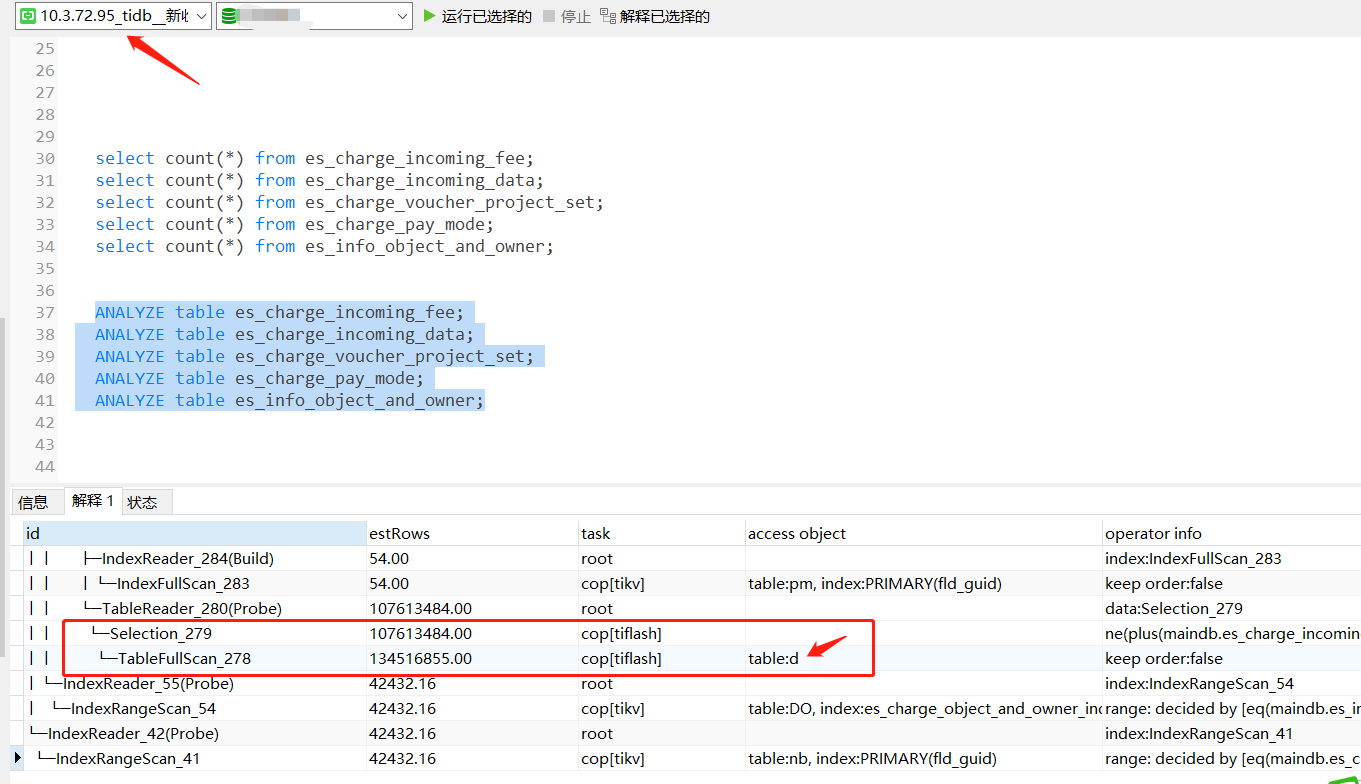
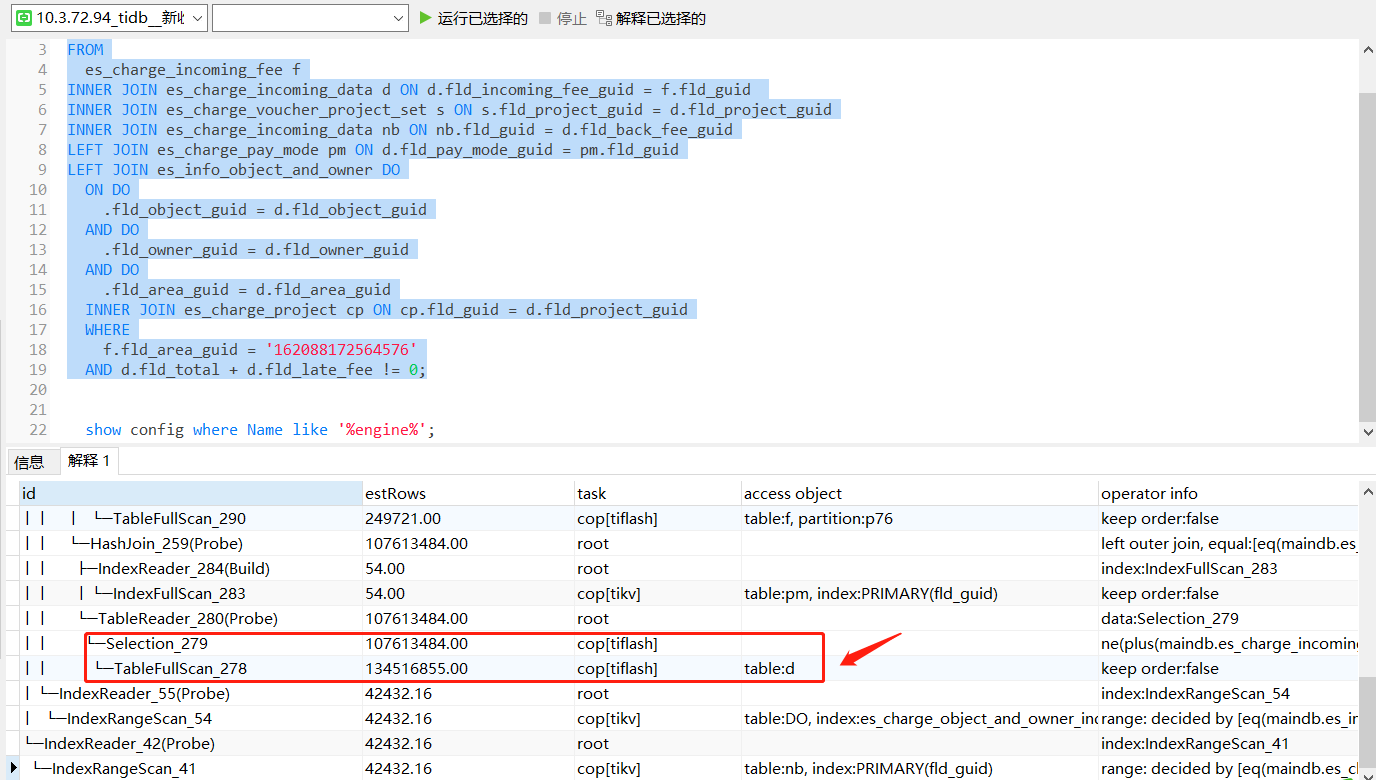
The case has been closed. On the tidb-server at 10.3.72.95, I executed the following commands on five tables:
ANALYZE table es_charge_incoming_fee;
ANALYZE table es_charge_incoming_data;
ANALYZE table es_charge_voucher_project_set;
ANALYZE table es_charge_pay_mode;
ANALYZE table es_info_object_and_owner;
After execution, I checked the two tidb-servers again, and this time, the execution plans were the same.
The deployment resources of the services are different, right? Check the health status of the table analysis loaded on the two TiDBs.
In other words, the statistics cache of different TiDB servers varies.
Isn’t the statistical information stored on PD, and is there a difference between the two TiDBs?
I can only suspect that the statistical information of the original table is outdated, and then TiDB used pseudo-random numbers to collect the statistical information when executing SQL, resulting in different random outcomes for the two TiDBs.
Statistics and region information are stored in PD, but TiDB also needs to cache this data, otherwise the efficiency would be too low.
There should be an execution plan cache, similar to Oracle’s hard parsing and software parsing. If statistics need to be cached on each node, then for a database with high load, frequent updates, and many nodes, the update mechanism for this cache would be difficult to design.
Execution plans rely on statistics. If the statistics are inaccurate, the execution plan will change.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.