Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 有没有处理过单表2亿条数据,33个字段(无大数据字段 text,blob之类的),要求:一个 select-from返回全表数据的
【TiDB Usage Environment】Production Environment
【TiDB Version】7.1.1
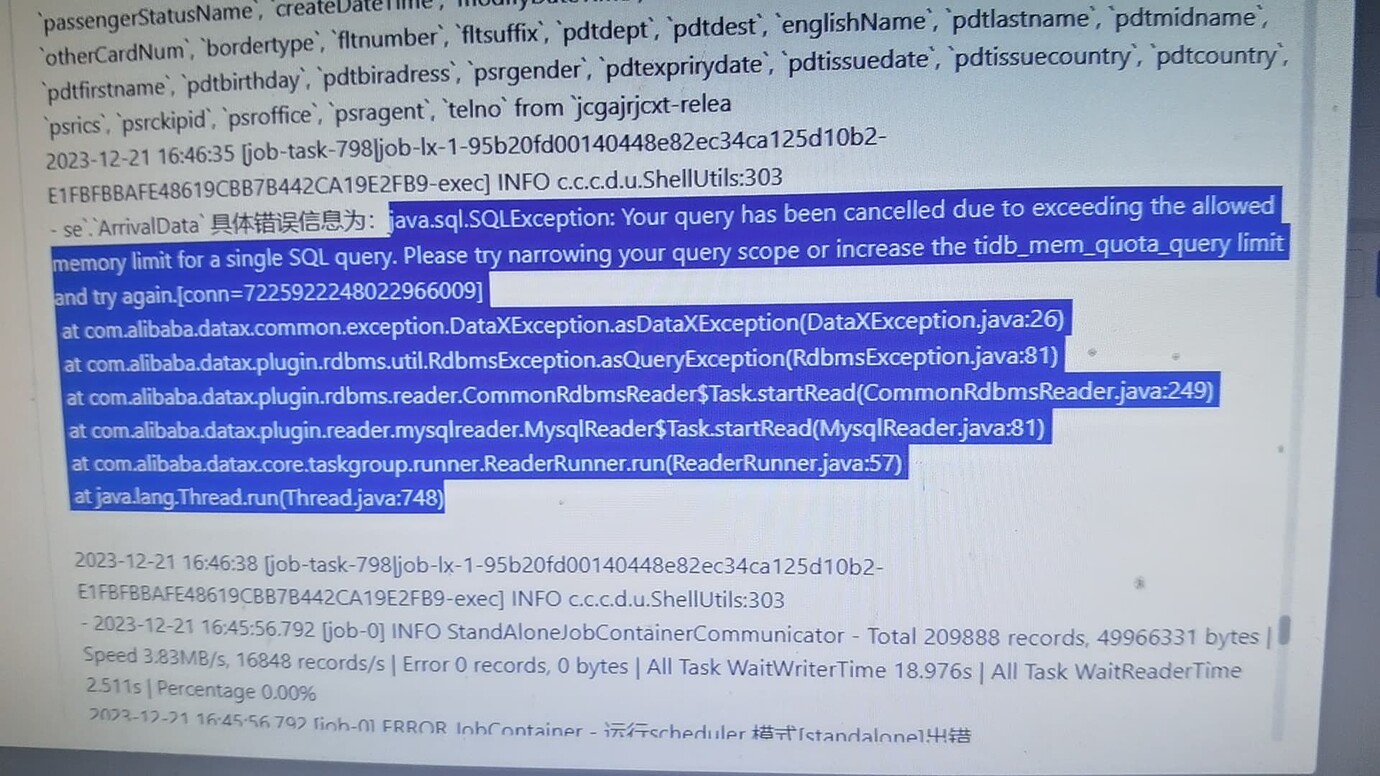
I allocated 24GB of memory, but it reports an out-of-memory error after running for a bit:
Does anyone have experience with this:
- How much data can TiDB return in a single query?
- How do I adjust this parameter?
If the memory is insufficient, it is estimated that it won’t work without enabling spill to disk. If a slower performance is acceptable, then enable spill to disk.
When SQL statements containing Sort, MergeJoin, or HashJoin cause memory OOM, TiDB will trigger spill to disk by default.
After setting up the operators that can trigger spill to disk, there are only these three. Therefore, when you perform a single table select -from, you need to add an order by. Use the sort operator to trigger spill to disk.
Not good to use, because whether TiDB retrieves data in a streaming manner or using cursors, it will cause this large SQL to OOM.
- Therefore, a feasible solution is to split the batch processing, retrieve the data with multiple SQLs, split the batch according to business logic, and if the batch is still relatively large, split it further using window functions.
- Another approach is to solve it from the business side. Why do you need to retrieve 200 million data records with one SQL? This is unreasonable in itself.
Streaming and cursor data retrieval: 连接池与连接参数 | PingCAP 文档中心
Lobster’s two ideas are very targeted. The original poster can confirm whether the business requirement is reasonable. Unreasonable requirements can be directly rejected.
Another idea is to read data through Flink or Spark and write it downstream, but this depends on the relevant technology stack to implement.
First, clarify the requirements: why do you need to query all 200 million records? If it’s for transmission, other methods can be used.
You can increase the tidb_mem_quota_query parameter. We previously expanded the memory of one TiDB specifically for such large query statements.
Where should the 200 million data records be displayed after querying? Or do you need to export the 200 million data records to Excel or something similar? The requirement is not clear.
If the memory is insufficient, you can increase tidb_mem_quota_query. First, check the space occupied by the table data. You need to set it larger than this value.
SELECT TABLE_NAME as tableName,
concat((DATA_LENGTH/(1024*1024*1024)),"GB")
FROM information_schema.`TABLES`
WHERE TABLE_SCHEMA='z_qianyi'
AND TABLE_NAME='ticket'
Low-level solution: Divide and conquer, split into small batches, export bit by bit, trading time for space.
Advanced solution: Make the business side’s head buzz. Such demands are akin to trying to determine the color of a user’s phone case by capturing the reflection in their eyes through the front camera, and then automatically adjusting the app theme. The result would be the product manager getting beaten up. For such demands in the future, just outright reject them.
Carefully read the topic. The error message in the console log appears when the original poster uses DataX, right? For the source data, you used select * from table; the data is cached locally. Considering the size of the database, it’s bound to throw an error. This approach is inherently problematic and unreasonable. If you want to try it, you can increase the relevant DataX configuration, such as the Java memory parameters. Of course, TiDB also needs to configure the query memory parameters, but be cautious as it might affect other service instances.
 Very detailed, I didn’t even notice
Very detailed, I didn’t even notice alibaba.datax. So this means data transmission needs to be synchronized in batches and segments, right?
Marking this for later. This issue is highly likely to be encountered. If there’s really no other way, segmenting it is the only option, but the complexity will increase significantly.
If pagination is not used, it will probably result in an OOM (Out of Memory) error.
I have a solution for your reference:
In Java JDBC, there is a parameter called cursor scrolling, which only allows forward scrolling and not backward scrolling. It is usually used as a pipeline for stream processing. However, the core issue is: after processing so much data through the pipeline, where do you put it? (Of course, this is something you need to worry about)
When querying MySQL with JDBC, by default, all the data queried by the SQL is loaded into memory from the server at once. When there is too much data, it leads to memory overflow. The best way is to fetch the data in pages incrementally.
Statement statement = connection.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
// Set the fetch size for retrieving multiple rows from the database
statement.setFetchSize(batchSize);
// Set the maximum number of rows that any ResultSet object generated by this Statement object can contain to the given number
statement.setMaxRows(maxRows);
Set the number of rows fetched each time and the maximum limit according to the actual memory size of your service to avoid overload.
Please refer to this.
Extracting 200 million rows of data through DataX, I want to know what your target end is.
First, check the table size. The memory should be at least 2 to 3 times the table size.
In what scenarios would such a requirement arise? If it’s for business purposes, it obviously seems unnecessary. How would you view such a large amount of data at once? If it’s for data processing, you can achieve it through professional ETL tools, executing in multiple batches, with each batch processing data that meets certain conditions.
Why do this? What kind of business scenario requires such an operation? It feels like an unreasonable demand. Batch processing is not handled this way either. I suggest explaining the real business requirement scenario; it feels like a pseudo-demand.
Directly using select for a one-time query resulting in OOM is normal. The simplest way is to write a simple code for batch queries, which can run locally.
It mainly depends on your use case. If it is to provide data to downstream, you can use Dumpling to export it into a file for downstream.