There are slow SQL queries, mainly concentrated on slow query analysis in the dashboard and a previous query. How can I check if there is an OOM (Out of Memory) issue?
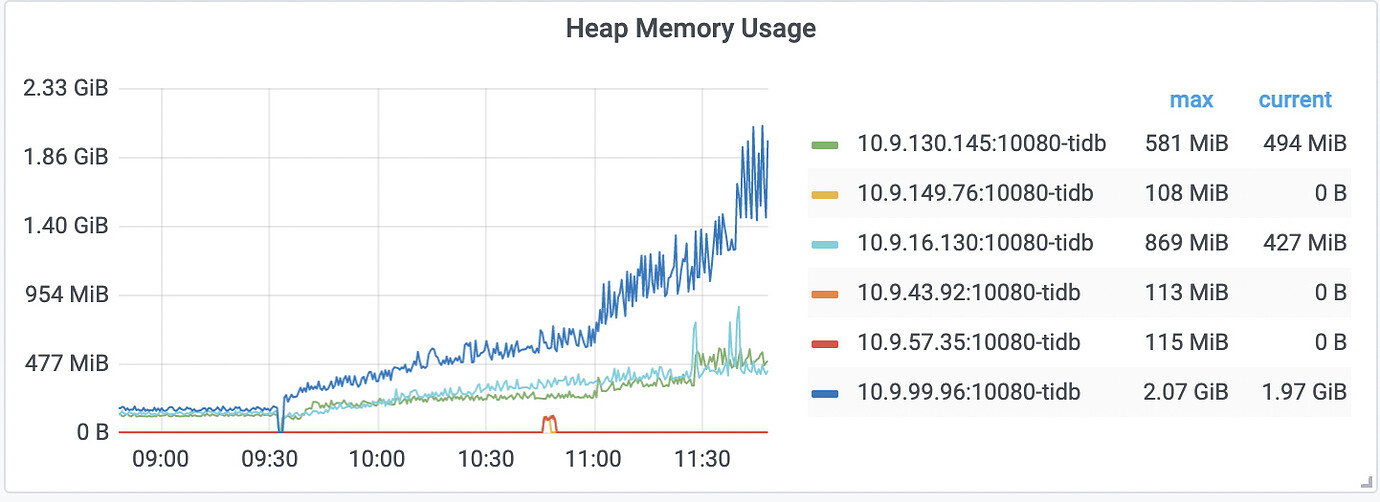
This is the latest update. After restarting the tidb-server, the values are not as unbalanced, and the growth of the three tidb instances is relatively synchronized.
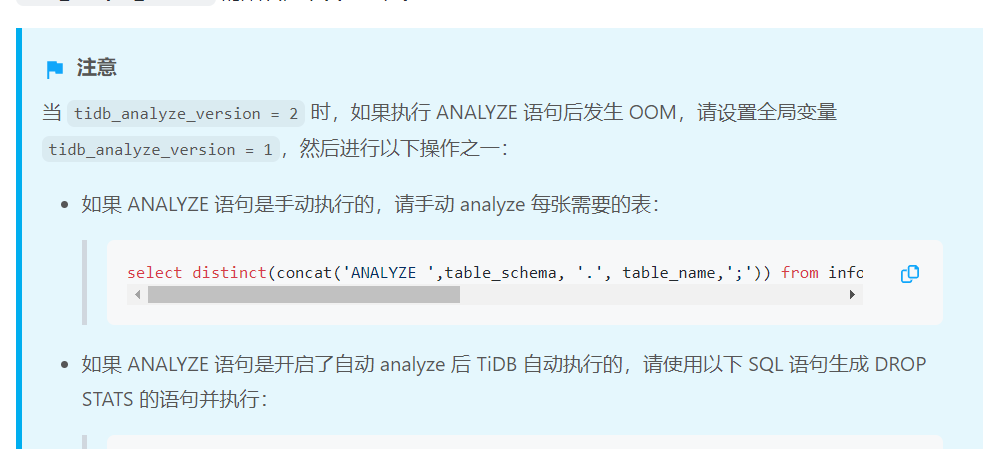
From the heap, the highest one is related to slow logs. It is estimated that the processing mechanism of this part may have changed after version 5.x. Check if the value of the analyze_version variable is 2, if so, change it to 1. Also, clear the historical statistics with a value of 2 as shown below.
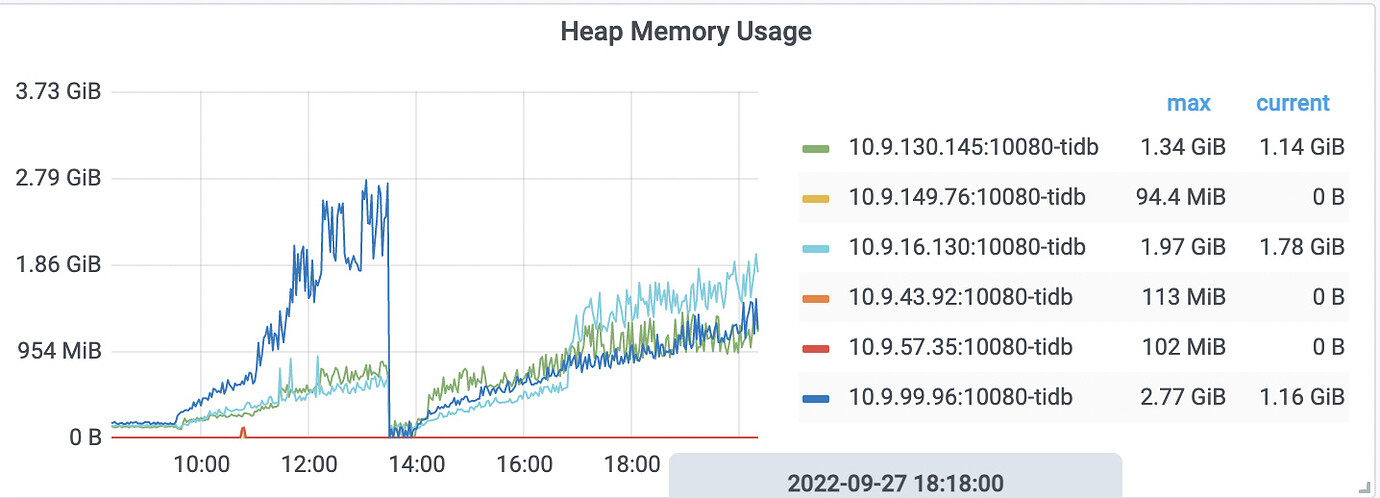
Adjusting analyze did not help, the memory usage still increased. In half an hour, the profile showed an increase of 100M, which is consistent with the increase in heap memory usage.
No abnormal queries were found in slow_query, and no analyze-related logs were found in tidb.log. Only the following two lines were found, corresponding to the time points when tidb-server was restarted:
At that time, there was only a small test table, which has already been dropped. The core business table does not require any drop operations. I would like to ask if it is still necessary to manually analyze the core business table?
Currently, it has stabilized at 2.4G, which is an increase of 2.2G compared to before. I would like to ask, apart from the 1G of Coprocessor cache, what other configurations could cause this increase in memory? Additionally, how can I determine if there is an automatic analyze? Should I check the tidb.log for relevant logs?