Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 求救 ,我ticdc同步到自己tidb上面去了,需要怎么处理,在9点10分左右发现的
【TiDB Usage Environment】Production Environment
【TiDB Version】v5.4.0
【Reproduction Path】Configured ticdc to sync to itself this morning, now all data has rolled back to 8:44 AM, discovered around 9:10 AM, what should I do?
【Encountered Problem: Problem Phenomenon and Impact】
【Resource Configuration】Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
【Attachments: Screenshot/Logs/Monitoring】
This is really hopeless. By default, it can be restored within 10 minutes.
Is your GC interval 10 minutes, or have you customized it?
GC taking a long time can still be resolved.
The default is 10 minutes.
Let me share how I handled a similar issue before:
- Upon discovering an operational error, regardless of the GC duration, stop the GC first to ensure historical data is still available. Then, carefully analyze and compare to restore the original data.
- If it’s beyond the GC time range, you can only use backups for restoration.
In your scenario, it seems like there’s no impact. If TiCDC synchronization is complete, isn’t that your latest data? It’s just that the production database is under heavy load and needs some time to recover.
I don’t think it has any impact. If ticdc synchronization is completed, isn’t it your latest data at that moment?
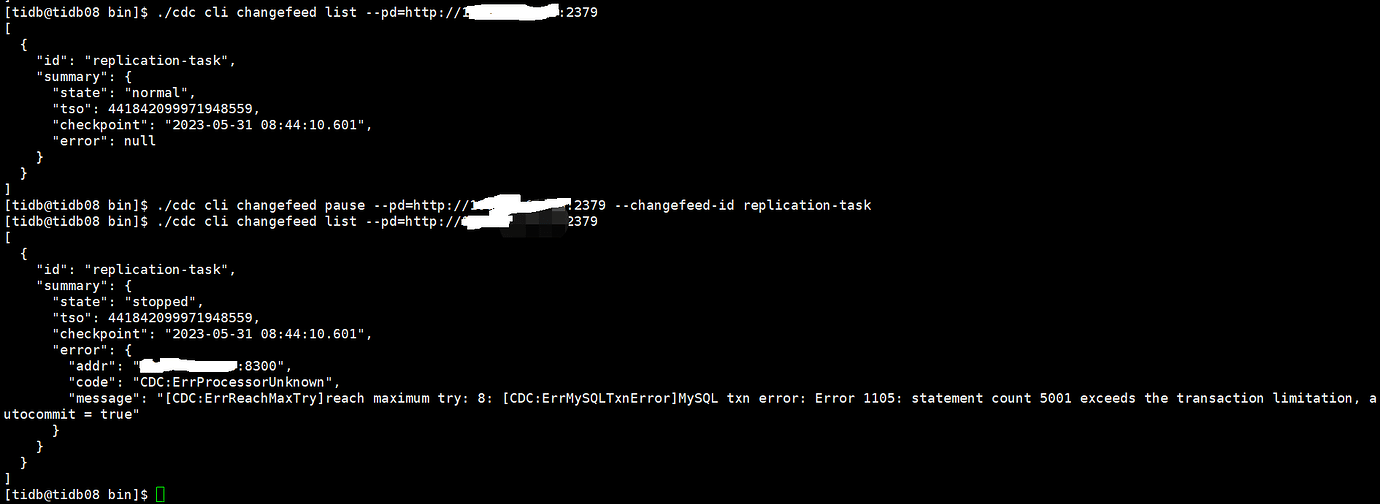
I thought the same, but the time interval is about 30 minutes apart. The customer reported that the data processed yesterday reverted today, and there was also an error reported during synchronization.
There should be a problem. ticdc will only synchronize tables with valid indexes, excluding idempotent 5 minutes. Subsequent operations are the original SQL. I understand that it should exit when encountering an insert… update should loop, and delete should execute once.  You can think about it more carefully.
You can think about it more carefully.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.