Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 求助:上游MySQL一跑批,下游TiDB所有tikv IO就飙高
[TiDB Usage Environment] Production Environment
[TiDB Version] v5.4.3
[Reproduction Path] Operations performed that led to the issue
[Encountered Issue: Problem Phenomenon and Impact] The upstream MySQL cluster is synchronized to a downstream small TiDB cluster via DM, with TiDB mainly used for OLAP queries. At the end of the month, when the upstream MySQL runs a batch process, all TiKV nodes in the downstream TiDB cluster start experiencing IO bottlenecks.
The situation is as follows:
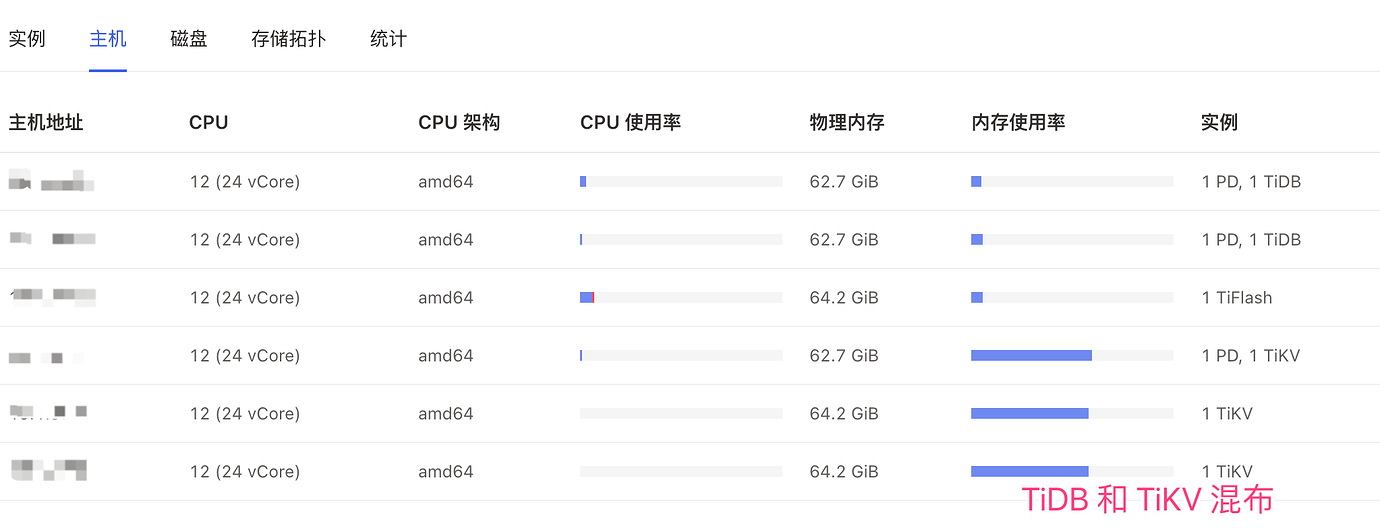
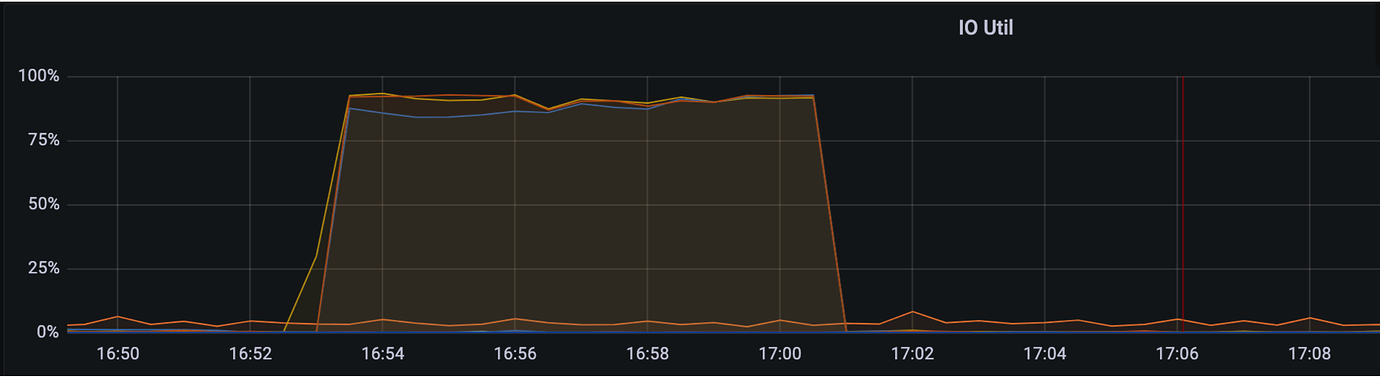
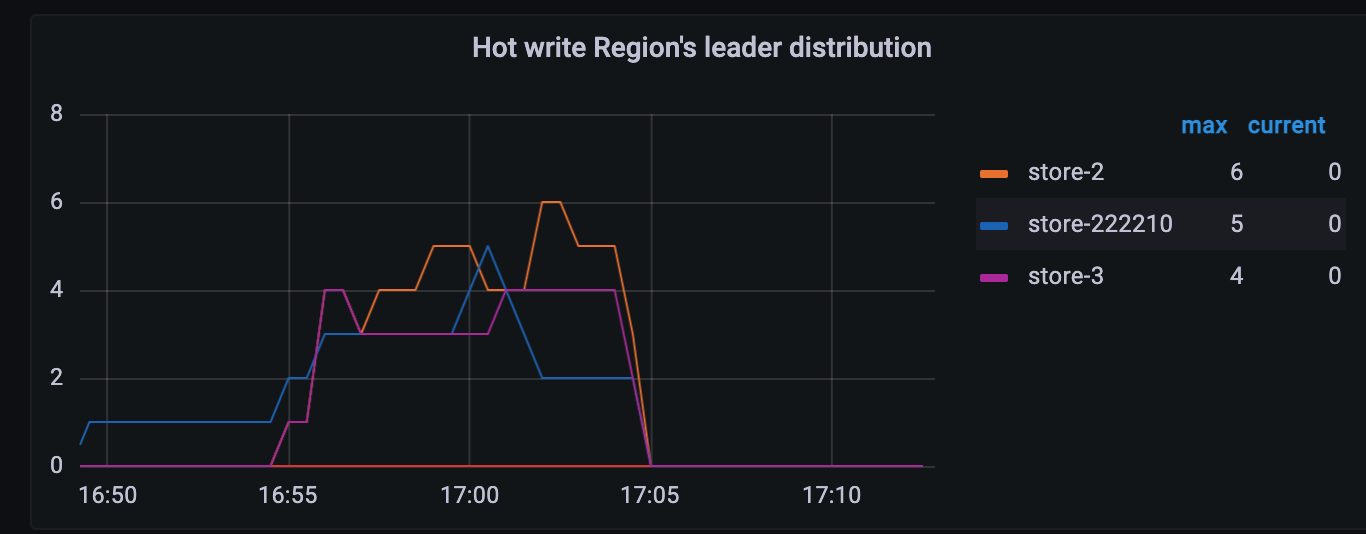
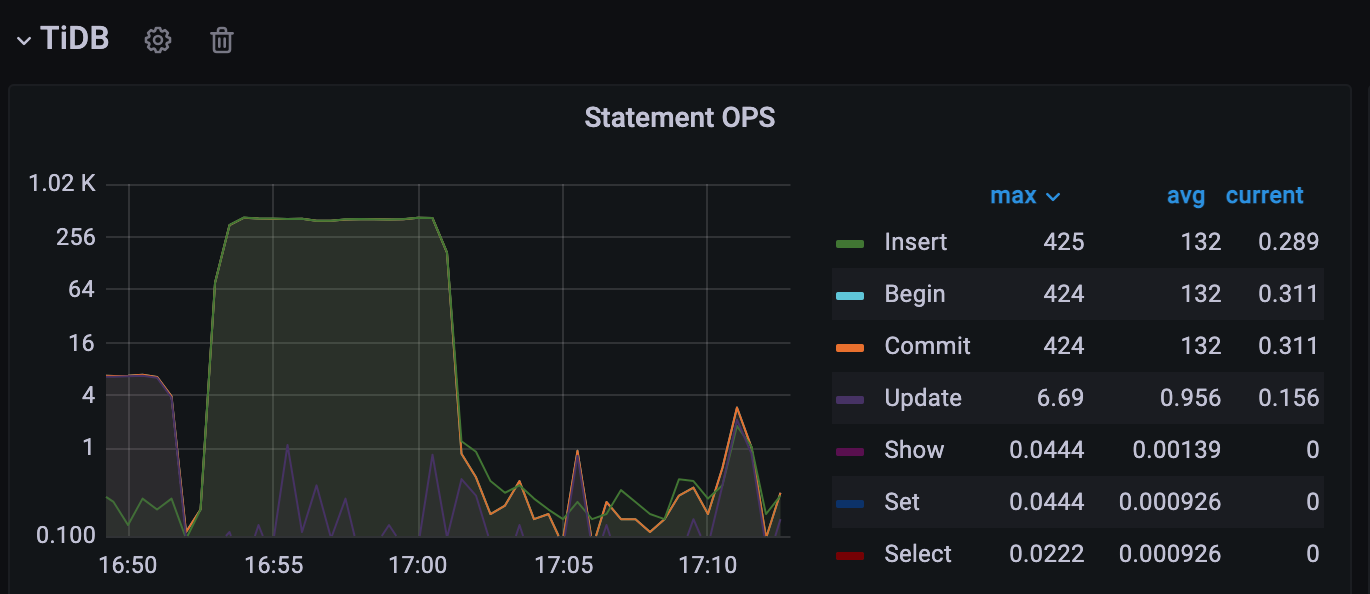
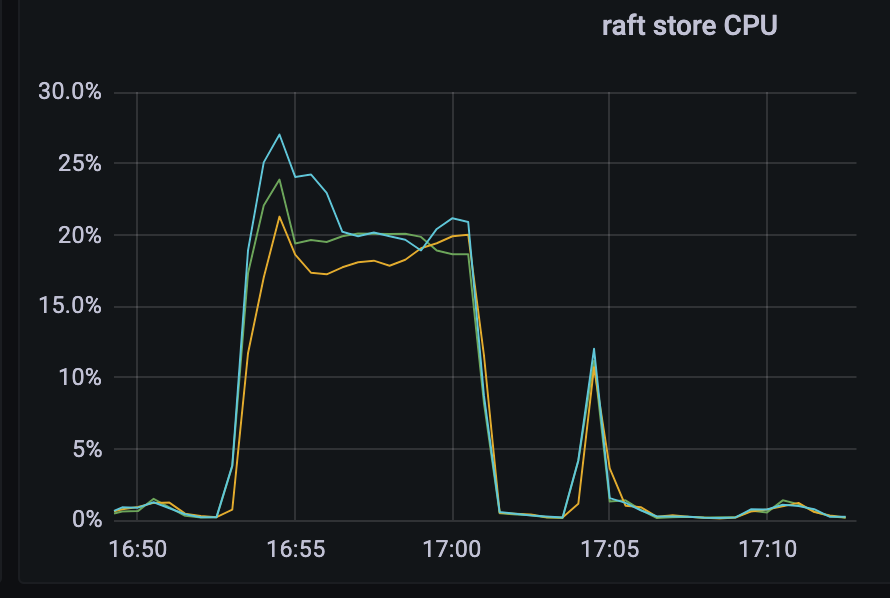
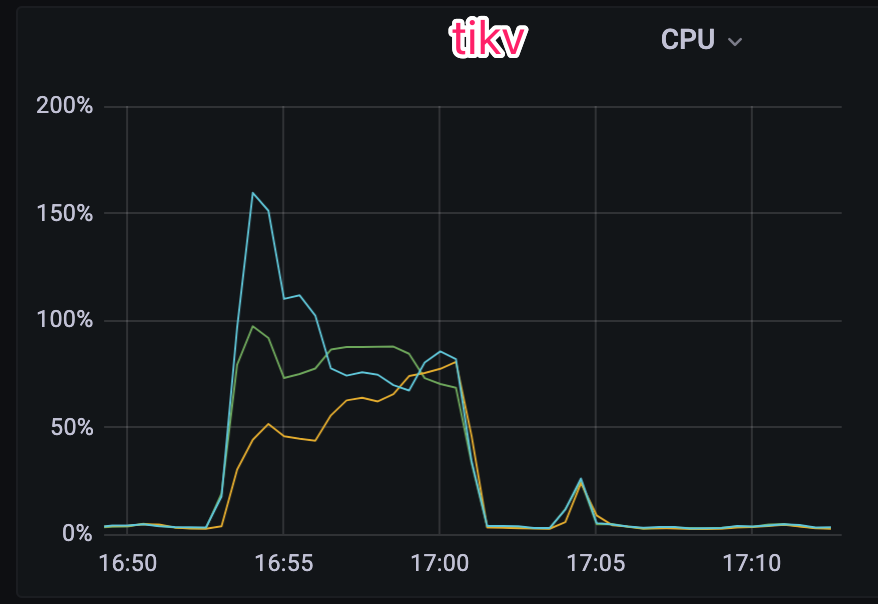
The table structure involved is as follows:
CREATE TABLE `t1` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'Auto-increment primary key',
`aid` varchar(64) NOT NULL COMMENT 'aid',
`order_no` varchar(64) NOT NULL COMMENT 'Original order number',
`p_code` varchar(64) NOT NULL COMMENT 'Primary label',
`tag_code` varchar(64) NOT NULL COMMENT 'Label code',
`created_by` varchar(45) DEFAULT NULL COMMENT 'Created by',
`updated_by` varchar(45) DEFAULT NULL COMMENT 'Updated by',
`created_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Creation time',
`updated_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Update time',
`is_default` tinyint(4) DEFAULT '0' COMMENT 'Is default enum, 1-yes',
`effective_date` timestamp NULL DEFAULT NULL COMMENT 'Effective date',
`expire_date` timestamp NULL DEFAULT NULL COMMENT 'Expiration date',
`remark` varchar(512) DEFAULT NULL COMMENT 'Remark',
PRIMARY KEY (`id`),
KEY `idx_aid_p_code` (`aid`,`p_code`),
KEY `idx_order_no` (`order_no`),
KEY `idx_tag_code` (`tag_code`),
KEY `idx_p_code` (`p_code`)
) ENGINE=InnoDB;
The main TiDB cluster parameters are:
server_configs:
tidb:
log.level: info
log.slow-threshold: 300
mem-quota-query: 10737418240
performance.txn-entry-size-limit: 125829120
performance.txn-total-size-limit: 10737418240
prepared-plan-cache.enabled: true
tikv:
raftstore.apply-pool-size: 8
raftstore.messages-per-tick: 4096
raftstore.raft-max-inflight-msgs: 2048
raftstore.store-pool-size: 5
raftstore.sync-log: false
readpool.coprocessor.use-unified-pool: true
readpool.storage.use-unified-pool: true
readpool.unified.max-thread-count: 12
rocksdb.defaultcf.force-consistency-checks: false
rocksdb.lockcf.force-consistency-checks: false
rocksdb.max-background-jobs: 3
rocksdb.max-sub-compactions: 2
rocksdb.raftcf.force-consistency-checks: false
rocksdb.writecf.force-consistency-checks: false
server.grpc-concurrency: 8
storage.block-cache.capacity: 32GB
storage.block-cache.shared: true
The table synchronized from MySQL to the TiDB cluster has an auto-increment primary key ID and three auxiliary indexes, all of which are incremental attributes. When the upstream MySQL performs batch writes, the downstream TiKV IO spikes. How can this situation be handled better? ![]()