【TiDB Usage Environment】Production environment
【TiDB Version】v4.0.9
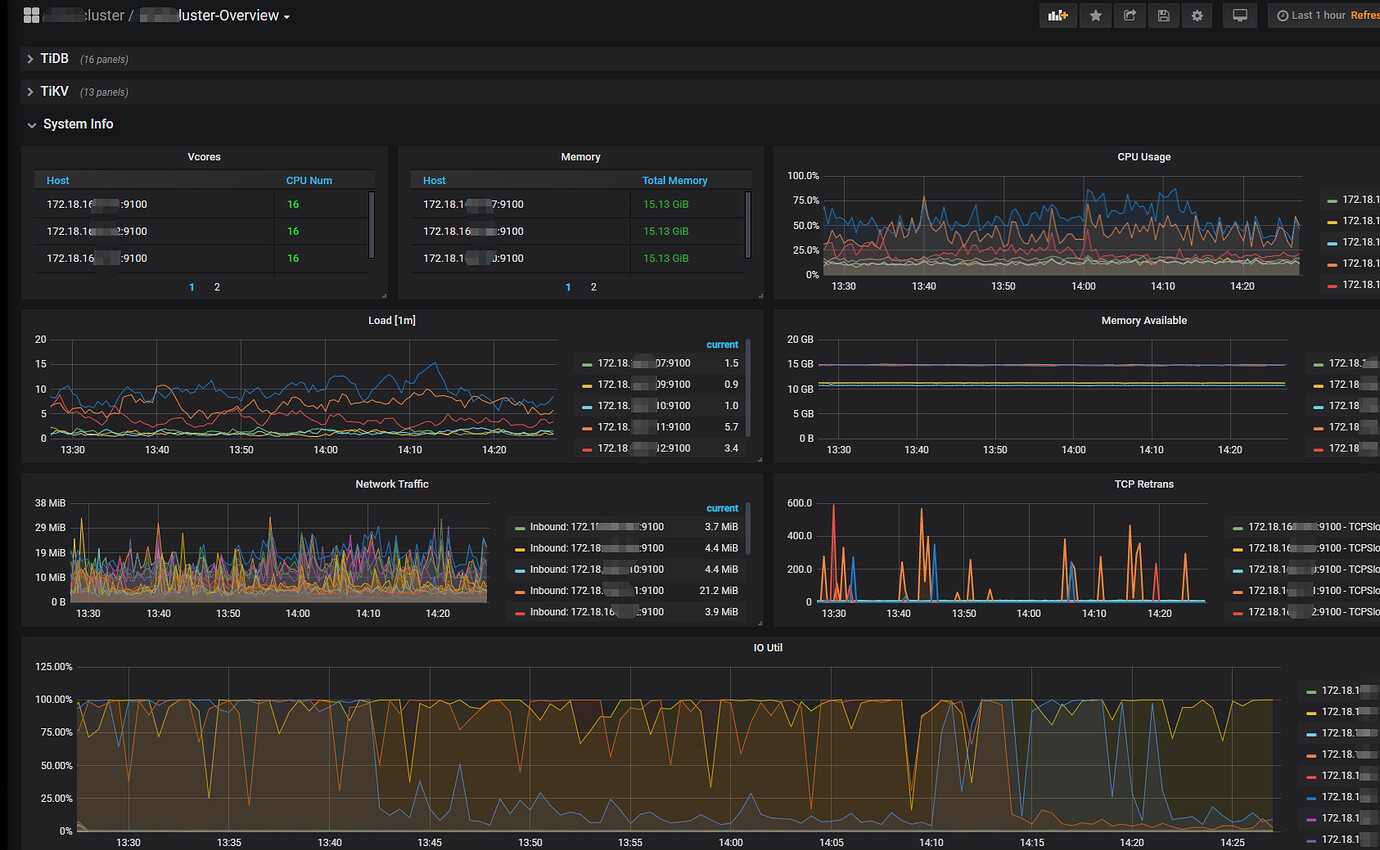
【Encountered Problem】The cluster has 3 TiKV nodes. Through the monitoring panel, it is often seen that the CPU load of a single TiKV is higher than the other two, and the IO of a single TiKV is always at 100%.
【Reproduction Path】Operations performed that led to the problem
【Problem Phenomenon and Impact】
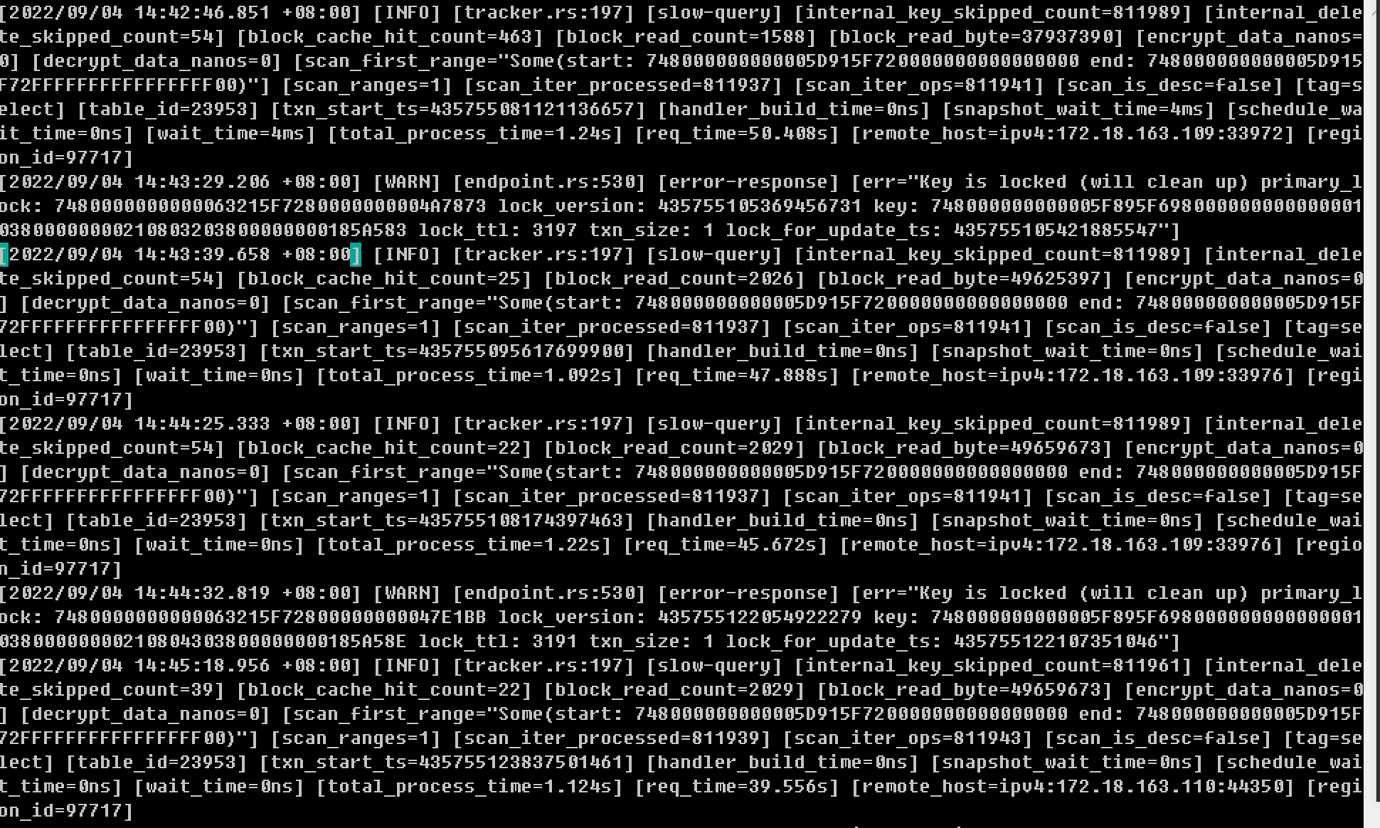
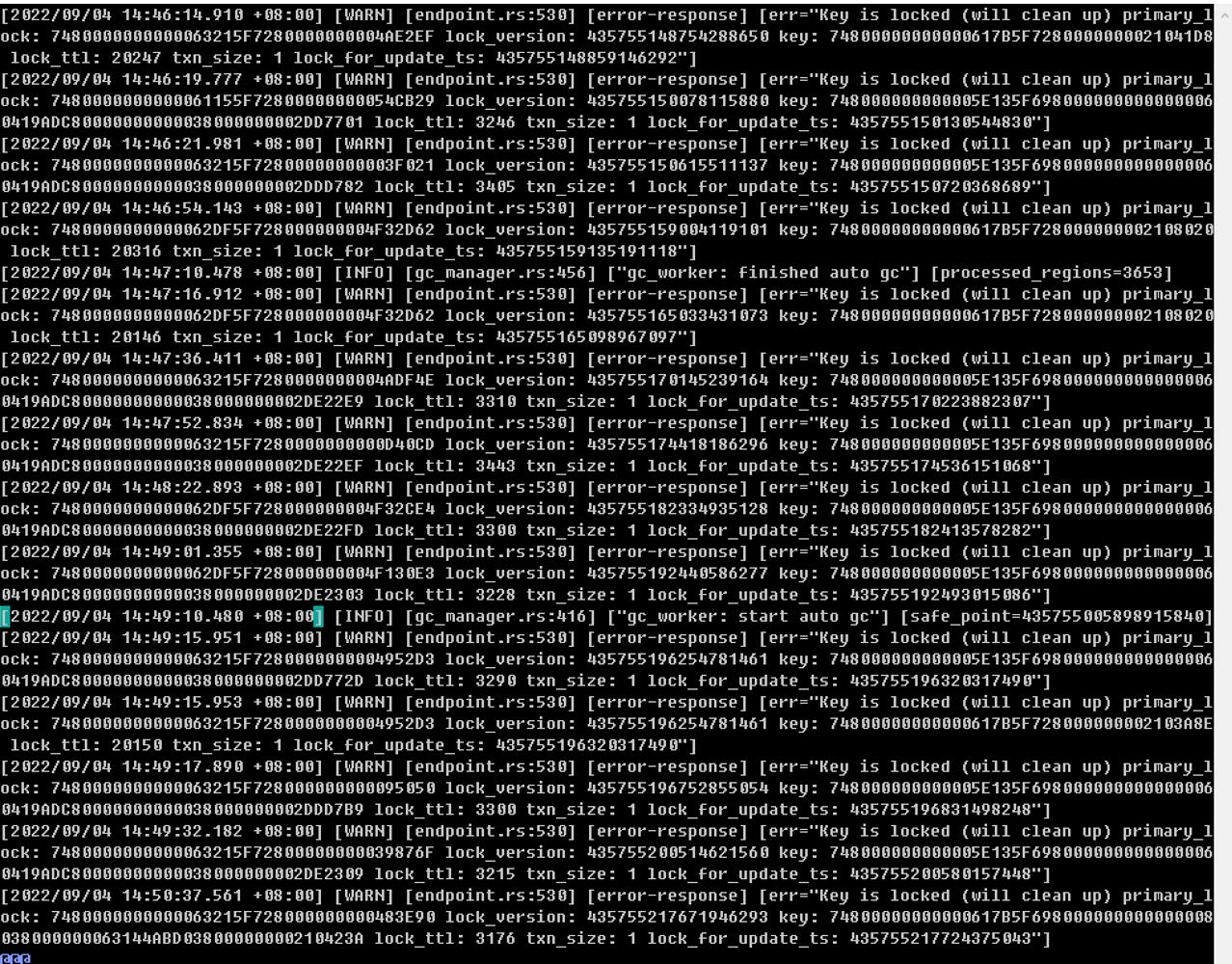
Causes system instability, and a single slow SQL can easily trigger an avalanche event. Recently, one of the TiKV’s CPU usage exceeded 90%, causing user system lag and generating a lot of dirty data. Attempting to restart a single TiKV node was ineffective. The entire cluster needed to be restarted to resume production.
【Attachments】
May I ask where to check the region metrics held by the TiKV nodes? If it’s in overview->tikv, the regions for all three machines are the same, max: 11.0K; current: 11.0K.
Yes. When the incident occurred last Sunday, I immediately checked the slow SQL, added indexes to the suspected queries, and made other optimizations. Then I doubled the CPU and memory for TiDB. MAX_EXECUTION_TIME is set at the session level in the application because analyze and adding indexes take more than 10 seconds. However, after observing for the past few days, it seems that the problem still exists and might be triggered again during the next peak period.
Causing system instability, a single slow SQL can easily trigger an avalanche event. Recently, one of the TiKV nodes had a CPU usage of over 90%, causing system lag for users and resulting in a lot of dirty data. Attempting to restart a single TiKV node was ineffective. The entire cluster had to be restarted to resume production.
Your method is incorrect and can easily lead to accidents.