Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: tikv 节点io占用过高
[TIDB Usage Environment] Production Environment / Testing / Poc
[TIDB Version] 5.4.1
[Reproduction Path] What operations were performed that caused the issue
[Encountered Issue: Issue Phenomenon and Impact]
[Resource Configuration]
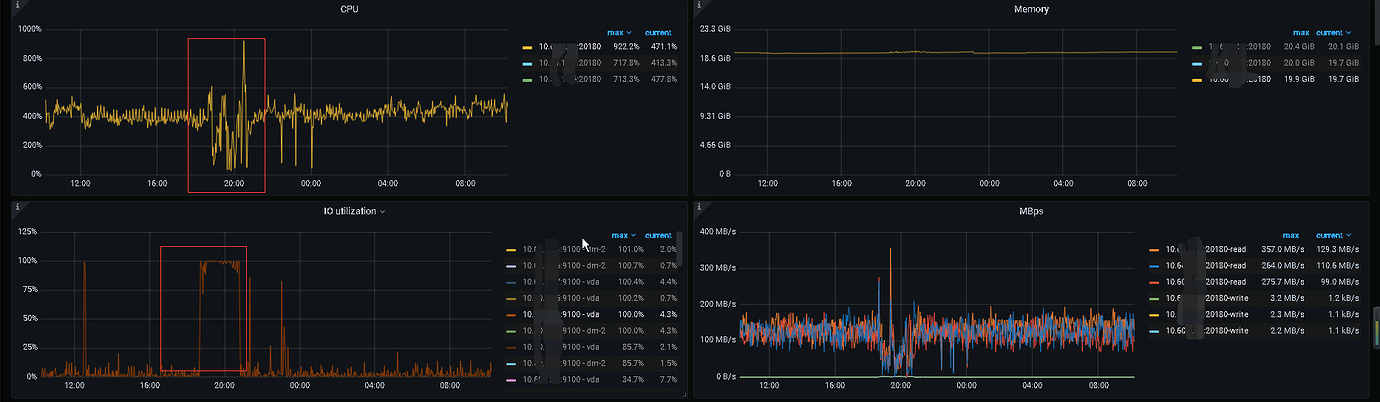
The TiKV IO usage is too high. What is causing this?
When I run a large number of pre-statistics, the IO usage becomes too high, causing program connection timeouts and errors.
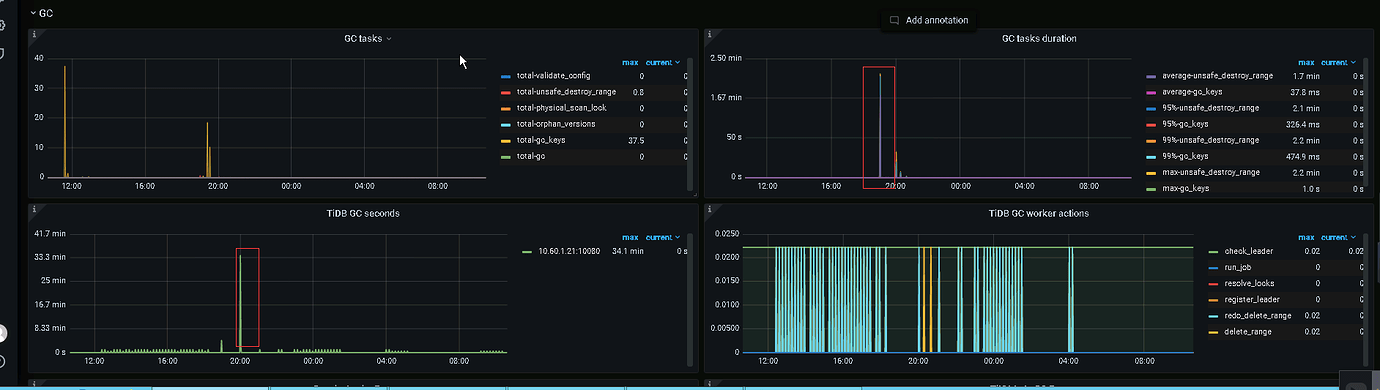
GC monitoring screenshot shows that GC time consumption is very high.
Is it just a large amount of data? Will pre-statistics write data or is it purely a select?
First delete, then query and insert.
You can consider processing in batches with SAS disks.
What kind of disk is this? IO is at 100%, but your throughput is only a bit over 300MB/s.
It is executed in multiple SQL statements, not a single SQL statement.
By the way, does the tidb_gc_life_time parameter refer to the time that deleted data needs to be retained during GC? For example, if I deleted data 20 minutes ago, and if this is set to 30 minutes, does it mean that data deleted within the current time minus this value will not be GC’d? The tidb_gc_run_interval variable refers to how often the GC operation is triggered. Is my understanding correct?
Take a look at the Disk-Performance monitoring interface, check the IOPS, and then look at the latency of this disk.
The monitoring images are in the compressed file.
It looks like high IO usage, could it be a full table scan on a large table?
The timing is not right. You need to check when the IO usage is at 100%, look at the latency, IOPS, and bandwidth. If none of these three have reached their limits, then the issue lies with the IO usage metric.
such as RAID arrays and modern SSDs, this number does not reflect their performance limits.
Whether the IO is high or not is a phenomenon; the main thing to look at is whether it affects the overall duration 999, 99, 85 of the TiDB cluster.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.