Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 当ticdc组件宕机的时候,期间数据完整性怎么保证?
When the TiCDC component crashes, how is data integrity ensured during that period?
Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 当ticdc组件宕机的时候,期间数据完整性怎么保证?
When the TiCDC component crashes, how is data integrity ensured during that period?
If the Ticdc service is abnormal, how can we notify the operations personnel immediately, similar to Zabbix monitoring forwarding emails?
If a TiCDC instance goes down, since the TiCDC cluster itself supports high availability, after re-electing the owner node, the changefeed of the downed instance will be migrated to other instances.
You can set alert rules for monitoring metrics from both Server and Changefeed dimensions.
Some general alert rules are provided.
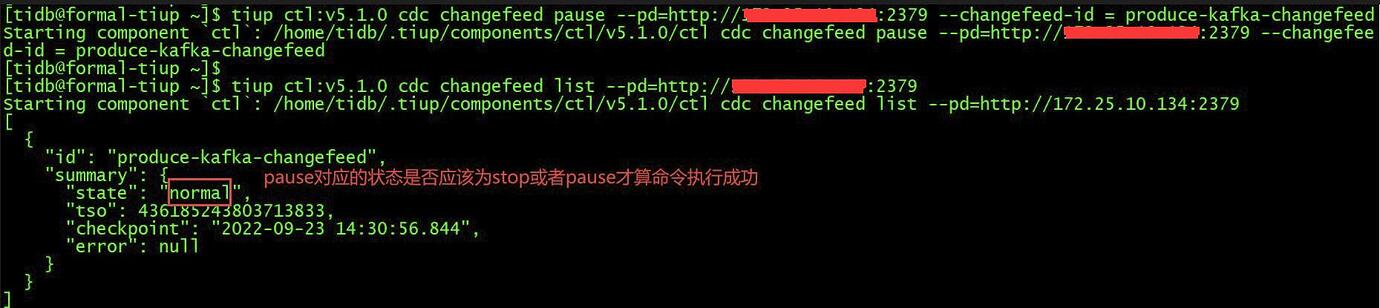
The corresponding state of pause should be either stop or pause to be considered normal.
Every time the pause command fails, the corresponding log shows the following error, and there is no issue with the command check.
There should be a checkpoint. If it’s a cluster, it should be transferable, right?
The main issue at the moment is that executing pause is unsuccessful, and the logs show “changefeed not found when handling a job.”
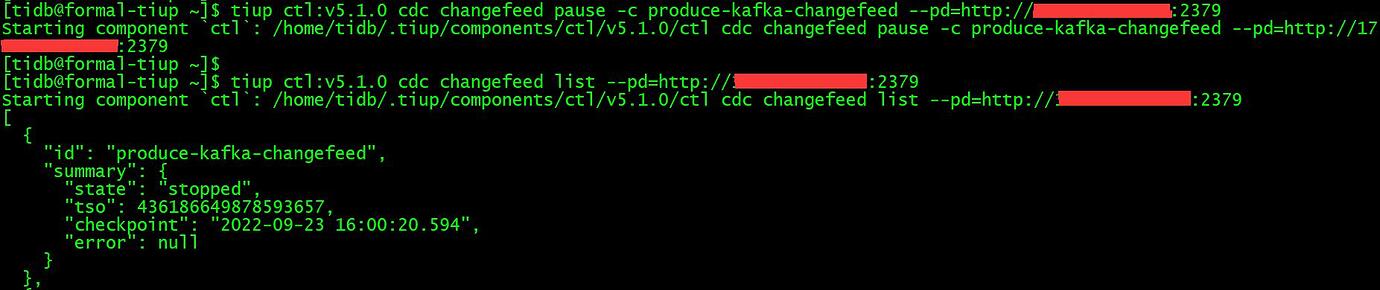
Thank you all. Modifying the command to the following format successfully pauses:
tiup ctl:v5.1.0 cdc changefeed pause -c produceparam-kafka-changefeed --pd=http://x.x.x.x:2379
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.