You can check out this article:
-
TiDB Index Design
-
Index Design Principles
TiDB was initially designed to provide horizontal scalability while being compatible with MySQL, addressing the issue of sharding. As it evolved, it needed to support high concurrency reads and writes, consistency with multiple replicas, high availability, and distributed transactions. Based on these requirements, an appropriate index data structure was chosen.
-
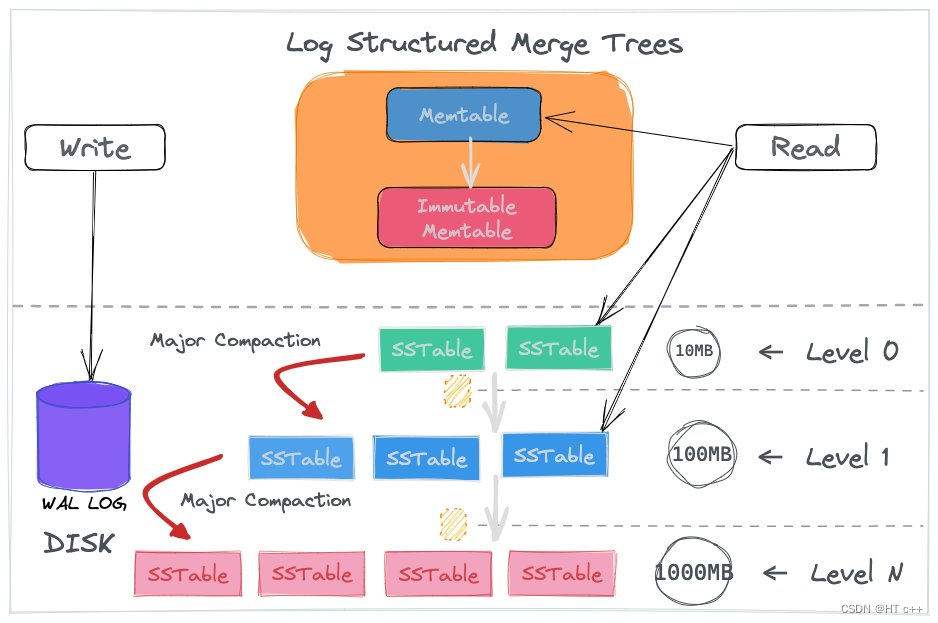
LSM-Tree (Log Structured Merge Tree)
Data is divided into two parts: one in memory and one on disk. The memory part consists of Memtable and Immutable Memtable. The disk part consists of multiple levels of SSTables, with older data at higher levels.
WAL (Write-Ahead Log) logs are appended-only log structure files used for replaying operations during system crashes to ensure data in MemTable and Immutable MemTable is not lost.
SSTable:
Key-value storage, ordered, containing a series of configurable-sized blocks (typically 64KB). The index of these blocks is stored at the end of the SSTable for quick lookup. When an SSTable is opened, the index is loaded into memory, allowing binary search within the memory index to find the disk offset of the key, and then reading the corresponding block from the disk. If memory is large enough, the SSTable can be mapped directly into memory using MMap for faster lookup.
MemTable is often an ordered data structure organized as a skip list.
Writing: Compared to B+ trees, when the data volume is very large, B+ trees suffer from performance issues due to page splits and merges during updates and deletions. LSM-Tree, on the other hand, splits data into a series of ordered SSTables written to disk like logs, without modification. When modifying existing data, LSM-Tree writes new data to a new SSTable instead of modifying old data. This ensures stable write speed regardless of data volume, as it involves appending logs and writing to a small-sized memtable.
Deleting data in LSM-Tree involves writing a delete marker to a new SSTable. This ensures sequential block writes to disk without random writes. When MemTable reaches a certain size (typically 64KB), it is frozen into an Immutable MemTable.
Write process:
- Write to WAL log for fault recovery.
- Simultaneously write to Memtable in memory.
- Dump the Immutable Memtable to SSTable on disk (Minor Compaction).
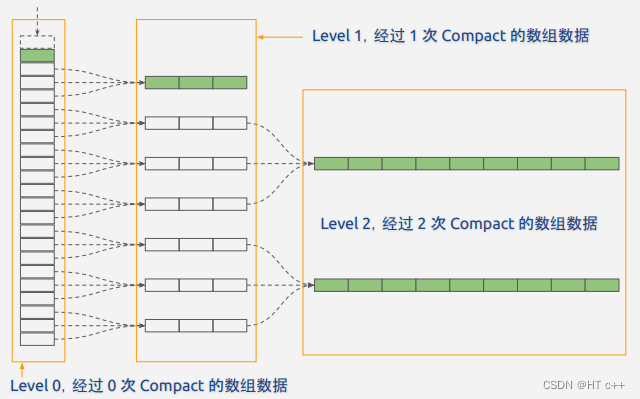
- Periodically merge SSTables when their size or number exceeds a threshold (Major Compaction), removing deleted data and merging multiple versions to save space.
Reading: Search in MemTable, then Immutable MemTable, then level 0 SSTable, and finally level N SSTable. Merge multiple SSTables into one, removing modified or deleted data to reduce the number of SSTables. If the target data is in the lowest level N SSTable, all SSTables need to be read and searched, causing read amplification.
Optimization methods:
- Compress data blocks.
- Use Bloom filters to quickly determine if data is not in an SSTable.
- Cache immutable SSTables in memory.
- Merge multiple SSTables into one.
SSTable:
Merging involves reading SSTables into memory and writing the merged SSTable to disk, increasing disk IO and CPU consumption, known as write amplification.
Set data size thresholds for each level.
SSTable file structure:
File format:
<beginning_of_file>
[data block 1]
[data block 2]
…
[data block N]
[meta block 1: filter block]
[meta block 2: index block]
[meta block 3: compression dictionary block]
[meta block 4: range deletion block]
[meta block 5: stats block]
…
[meta block K: future extended block]
[metaindex block]
[Footer]
<end_of_file>
- Differences between TiDB and MySQL Indexes
LSM-Tree splits data into multiple small arrays for sequential writes, approximately O(1). B+Tree splits data into fixed-size blocks or pages (typically 4KB), corresponding to a disk sector size, with write complexity O(logN). With inserts, B+Tree nodes split and merge, increasing random disk read/write operations and reducing performance. B+Tree supports in-place updates and deletions, making it more transaction-friendly as a key appears in only one page. LSM-Tree only supports append writes, with key ranges overlapping in L0, making it less transaction-friendly, with updates and deletions occurring during Segment Compaction.
RocksDB splits disk-stored files into blocks (default 64KB). When reading a block, it first checks if the block is in the BlockCache in memory, avoiding disk access if present.
Supports: Primary key index, unique index, and regular index.
Does not support FULLTEXT, HASH, and SPATIAL indexes.
Does not support descending indexes.
Does not support adding multiple indexes in one statement.
-
Differences from MySQL
-
AUTO_INCREMENT
Auto-increment values are allocated in batches to each TiDB server (default 30,000 values). Each TiDB node requests a segment of IDs as a cache, requesting the next segment when exhausted, rather than requesting an ID from the storage node each time. The order of values is not globally monotonic.
-
DDL
Cannot perform multiple operations in a single ALTER TABLE statement. For example, cannot add multiple columns or indexes in a single statement, otherwise, an “Unsupported multi schema change” error may occur. Does not support modifying column types on partitioned tables.
-
Partitioned Tables
Supports Hash, Range, and Add/Drop/Truncate/Coalesce partitioning. Other partition operations are ignored and may result in a “Warning: Unsupported partition type, treat as normal table” error. Does not support the following partition syntax:
PARTITION BY LIST
PARTITION BY KEY
SUBPARTITION
{CHECK|EXCHANGE|TRUNCATE|OPTIMIZE|REPAIR|IMPORT|DISCARD|REBUILD|REORGANIZE} PARTITION
-
Locks
TiDB currently does not support gap locking.
Copyright Notice: This article is an original work by CSDN blogger “HT c++”, following the CC 4.0 BY-SA copyright agreement. Please attach the original source link and this statement when reprinting.
Original link: TiDB索引_tidb 索引-CSDN博客