Reference documentation:
Uniform Splitting
Since row_id is an integer, the keys to be split can be deduced based on the specified lower_value, upper_value, and region_num. TiDB first calculates the step (step = (upper_value - lower_value)/region_num), then splits the key at each step interval between lower_value and upper_value, ultimately creating region_num Regions.
For example, for table t, if you want to evenly split 16 Regions between minInt64 and maxInt64, you can use the following statement:
SPLIT TABLE t BETWEEN (-9223372036854775808) AND (9223372036854775807) REGIONS 16;
This statement will evenly split table t into 16 Regions between minInt64 and maxInt64. If the range of the primary key is known to be smaller, for example, only between 0 and 1000000000, you can use 0 and 1000000000 instead of the above minInt64 and maxInt64 to split the Regions.
SPLIT TABLE t BETWEEN (0) AND (1000000000) REGIONS 16;
Non-uniform Splitting
If the data is known to be unevenly distributed, for example, if you want to split one Region from -inf to 10000, another from 10000 to 90000, and another from 90000 to +inf, you can manually specify the points to split the Regions, as shown below:
SPLIT TABLE t BY (10000), (90000);
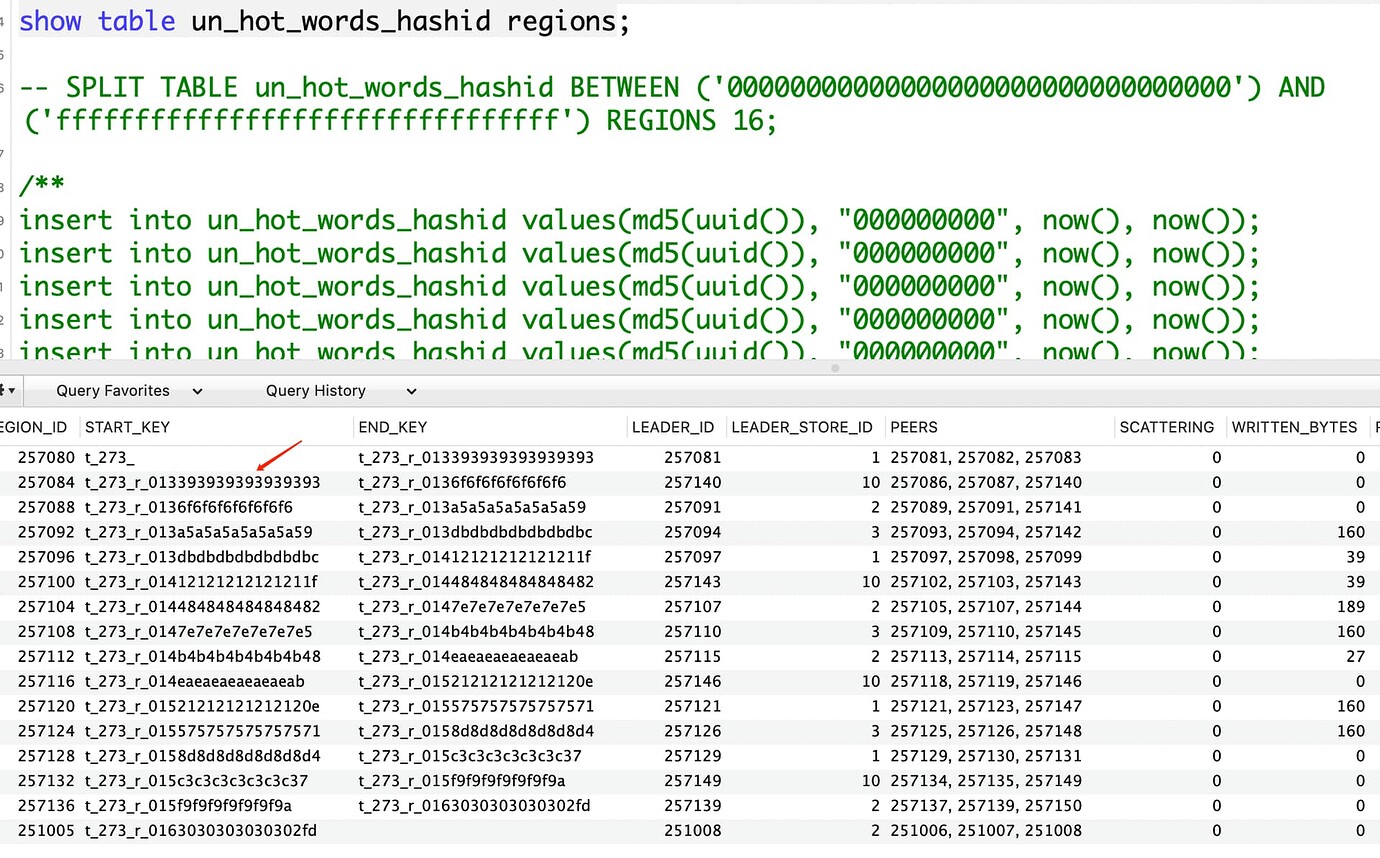
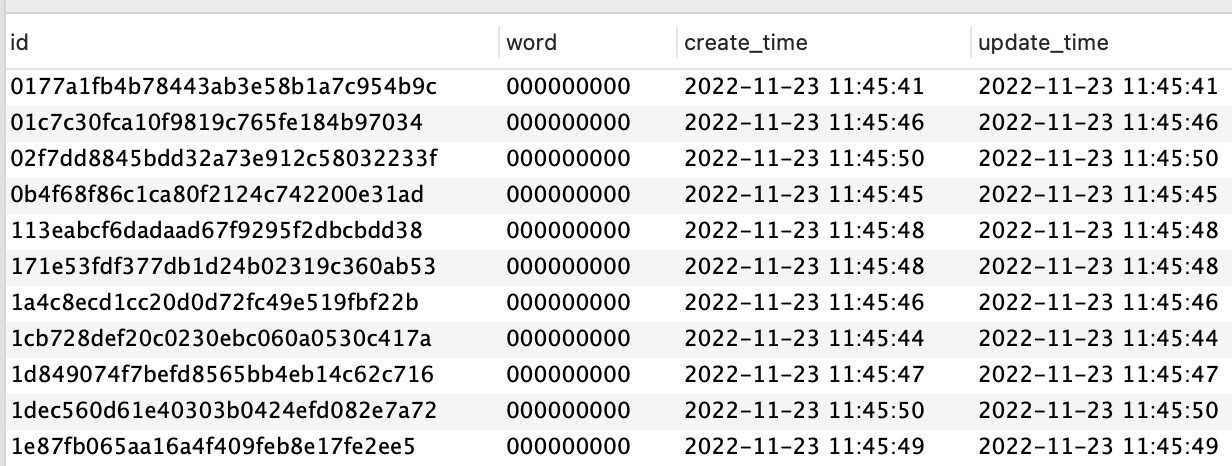
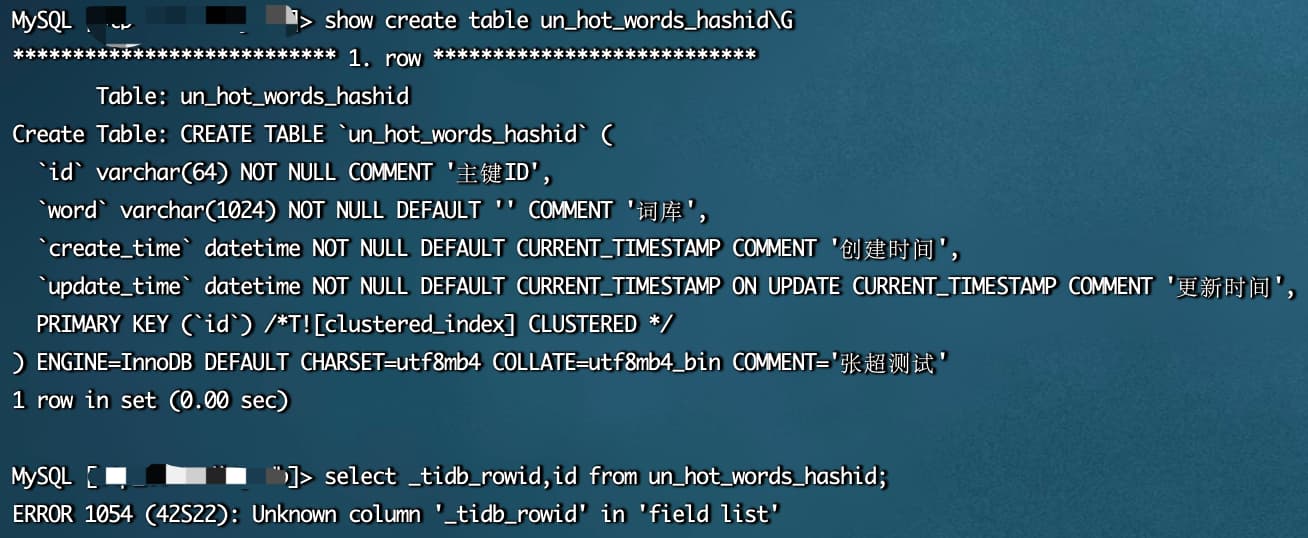
Everyone kept emphasizing varchar, so I thought varchar couldn’t be split. I specifically tested it, and it can be done.
root@127.0.0.1:4000[hqh]>show create table t1;
+-------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`id` varchar(64) NOT NULL,
`intkey` int(11) NOT NULL,
`pad1` varbinary(1024) DEFAULT NULL,
KEY `intkey` (`intkey`),
PRIMARY KEY (`id`) /*T![clustered_index] NONCLUSTERED */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin |
+-------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
root@127.0.0.1:4000[hqh]>
root@127.0.0.1:4000[hqh]>show table t1 regions;
+-----------+-----------+---------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+-----------+---------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| 1003 | t_110_ | | 1004 | 1 | 1004 | 0 | 2700 | 1355 | 1 | 0 |
+-----------+-----------+---------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
1 row in set (0.03 sec)
root@127.0.0.1:4000[hqh]>
root@127.0.0.1:4000[hqh]>SPLIT TABLE t1 BY (10000), (90000);
+--------------------+----------------------+
| TOTAL_SPLIT_REGION | SCATTER_FINISH_RATIO |
+--------------------+----------------------+
| 2 | 1 |
+--------------------+----------------------+
1 row in set (0.01 sec)
root@127.0.0.1:4000[hqh]>
root@127.0.0.1:4000[hqh]>show table t1 regions;
+-----------+---------------+---------------+-----------+-----------------+--------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+---------------+---------------+-----------+-----------------+--------+------------+---------------+------------+----------------------+------------------+
| 108003 | t_110_ | t_110_r_10000 | 108004 | 1 | 108004 | 0 | 0 | 0 | 1 | 0 |
| 108005 | t_110_r_10000 | t_110_r_90000 | 108006 | 1 | 108006 | 0 | 0 | 0 | 1 | 0 |
| 1003 | t_110_r_90000 | | 1004 | 1 | 1004 | 0 | 0 | 0 | 1 | 0 |
+-----------+---------------+---------------+-----------+-----------------+--------+------------+---------------+------------+----------------------+------------------+
3 rows in set (0.01 sec)