Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 一个机器挂多个磁盘的机器,怎么部署kv呢
[TiDB Usage Environment] Production Environment
[TiDB Version] 6.5.1
I would like to ask, for a machine with multiple disks, how should I deploy KV? Should I deploy multiple KV nodes on one machine and differentiate the data directories based on different disks?
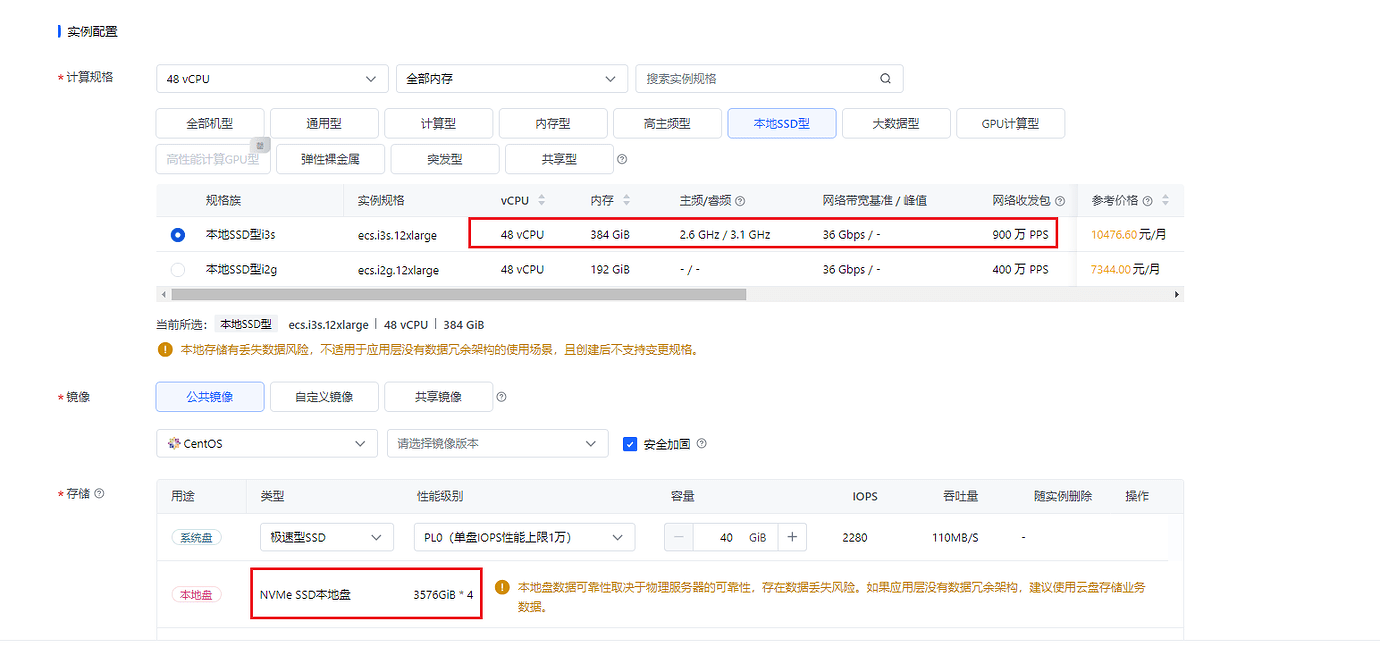
The configuration in the picture is 48 CPUs, 384G memory, and 4 pieces of 3.5T NVMe SSD dedicated local disks.
Yes, distinguish data directories based on different disks.
First, refer to the documentation TiDB Environment and System Configuration Check | PingCAP Documentation Center.
Mount the hard disks to different directories, such as /tidb-data, /tidb-data1, /tidb-data2, and then deploy TiKV data to different directories.
The TiKV configuration needs to set a memory usage limit, such as storage.block-cache.capacity: 24G. The actual usage is approximately 24G * 1.3.
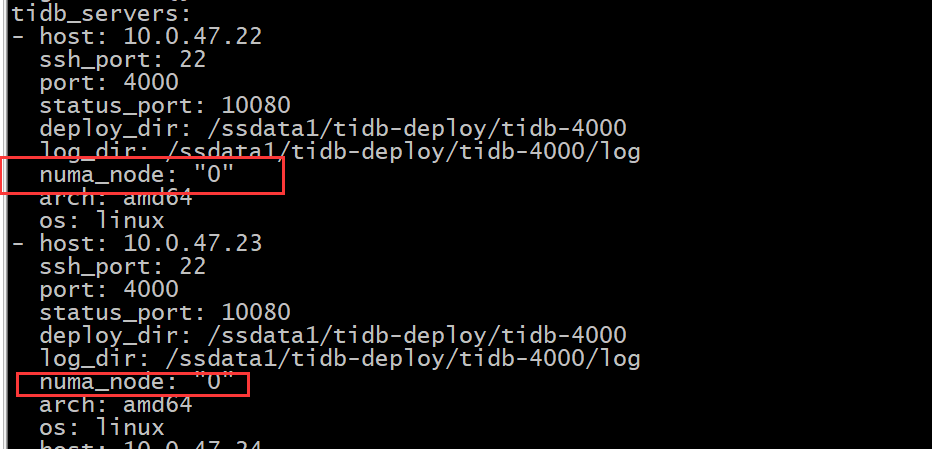
Refer to my 3-host 6-TiKV mixed deployment:
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/tidb-deploy"
data_dir: "/tidb-data"
arch: "amd64"
server_configs:
tidb:
log.level: "error"
tikv:
storage.block-cache.capacity: 24G
pd:
replication.enable-placement-rules: true
replication.location-labels: ["host"]
monitored:
node_exporter_port: 9100
blackbox_exporter_port: 9115
pd_servers:
- host: 192.168.19.205
- host: 192.168.19.206
- host: 192.168.19.207
tidb_servers:
- host: 192.168.19.205
- host: 192.168.19.206
- host: 192.168.19.207
tikv_servers:
- host: 192.168.19.205
port: 20160
status_port: 20180
data_dir: "/tidb-data/tikv-20160"
config:
server.labels: { host: "logic-host-1" }
- host: 192.168.19.206
port: 20160
status_port: 20180
data_dir: "/tidb-data/tikv-20160"
config:
server.labels: { host: "logic-host-2" }
- host: 192.168.19.207
port: 20160
status_port: 20180
data_dir: "/tidb-data/tikv-20160"
config:
server.labels: { host: "logic-host-3" }
- host: 192.168.19.205
port: 20161
data_dir: "/tidb-data1/tikv-20161"
status_port: 20181
config:
server.labels: { host: "logic-host-1" }
- host: 192.168.19.206
port: 20161
status_port: 20181
data_dir: "/tidb-data1/tikv-20161"
config:
server.labels: { host: "logic-host-2" }
- host: 192.168.19.207
port: 20161
status_port: 20181
data_dir: "/tidb-data1/tikv-20161"
config:
server.labels: { host: "logic-host-3" }
monitoring_servers:
- host: 192.168.19.205
grafana_servers:
- host: 192.168.19.205
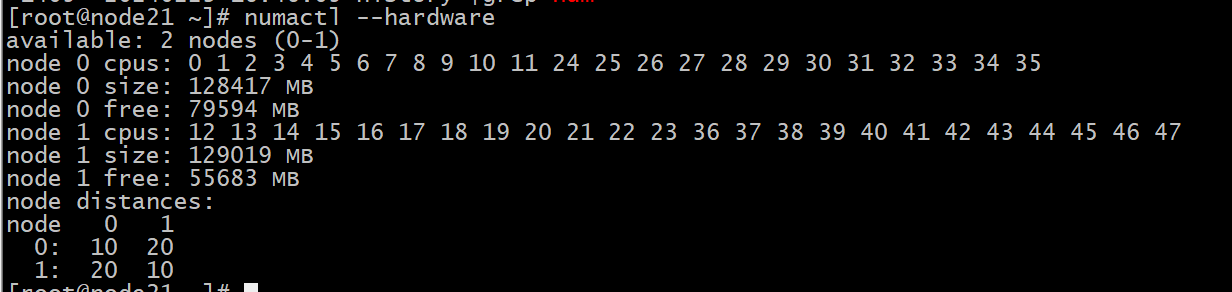
If there are multiple CPUs, you can use numactl to bind the CPUs.
Partition the 3.5T disk using the parted method.
The above are the reference steps, formatting the 3.5T partition into one. If you need to format multiple partitions, further research is required.
Divide it into 4 TiKV nodes and bind them with NUMA.
If there are only two CPUs, they can only be bound to two, right? Specifically 0 and 1, is that correct? For four TiKV nodes, two TiKV nodes use CPU 0, and two TiKV nodes use CPU 1, is that right?
Adjust the 96m block to 512m and mount four TiKV.
512m is too large, it will affect future deployment of tilfash, 256 is enough.
Well, try to isolate it as much as possible. Make sure to set the block-cache.capacity parameter for each tikv to 384G/40.45. By default, it will be set to 384G0.45, which can easily cause an OOM.
The disk specification is a bit large. Generally, around 2TB per TiKV is sufficient. If you divide your CPU into 8 parts, it will seem like there are too few CPUs.
If you divide it into 4 TiKVs, 12 cores per TiKV should be fine, with one NVMe disk per TiKV.
 I suggest directly disabling NUMA on x86 and creating just one TiKV.
I suggest directly disabling NUMA on x86 and creating just one TiKV.
My setting is 64G. I am using it in a mixed environment, and there is also TiFlash on it. I use NUMA to isolate the CPU and memory.
Resources are insufficient. With this configuration, adding two or three more machines would require an additional budget of several million.
At least 2 more machines are needed. Otherwise, putting 3 replicas on one TiKV would be very risky.
I originally wanted to buy this 12c 96G single disk, but I was worried that the CPU might not even reach 16C, which could be a bottleneck.
This is not expensive; it’s half the original price on the cloud.
If isolating by nodes, would it be better to directly use 12C 96G with a single 3.5T disk? Previously, I considered 48 CPU, 384G memory, and 4 x 3.5T disks, thinking that shared usage of CPU and memory might be slightly better than splitting into 12C 96G with a single 3.5T disk.
Can the project revenue cover this cost? If not, it will be a loss.