Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: tispark的写入速度很慢,如何提升?
Version
tispark 3.3_2.12-3.1.5
tidb7.1
spark3.3.1
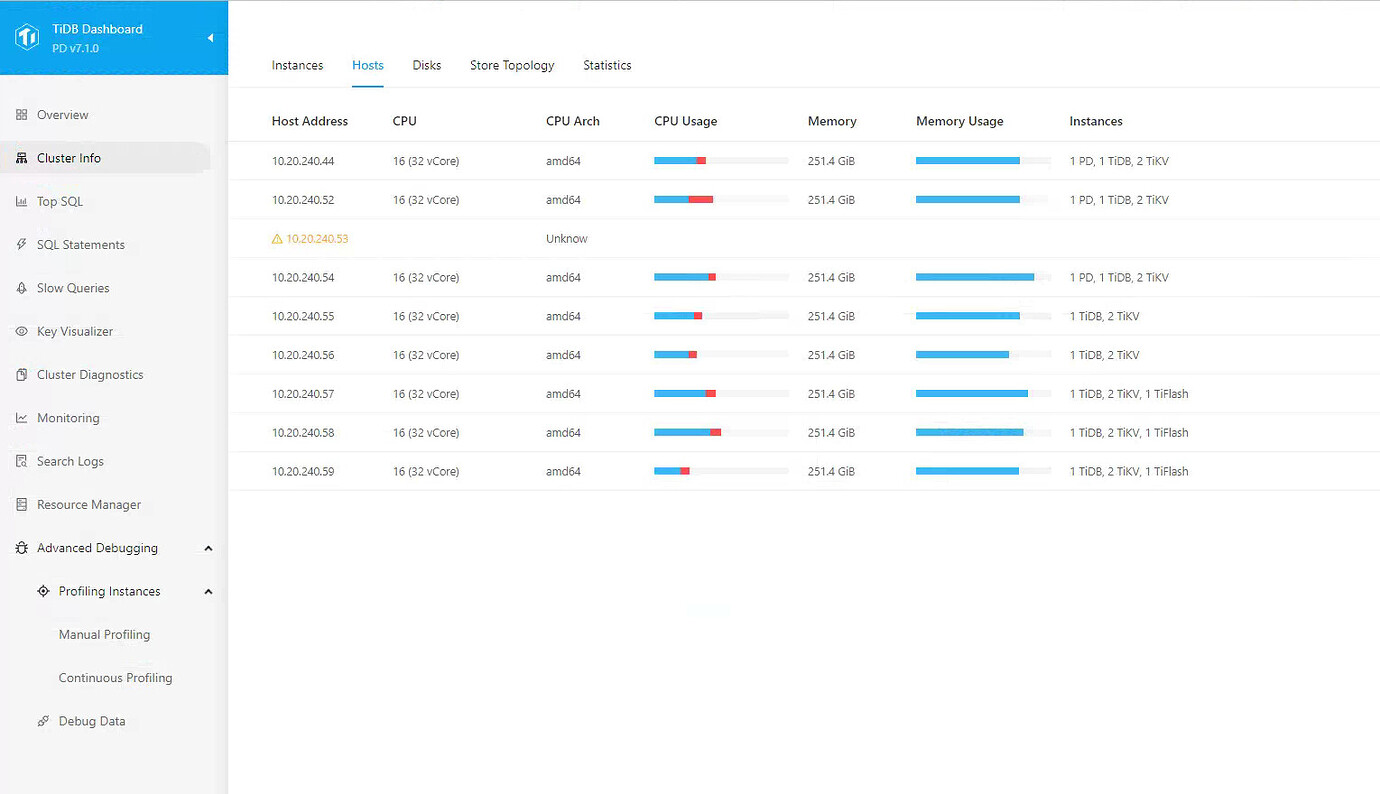
TiDB Deployment Topology
Problem Description
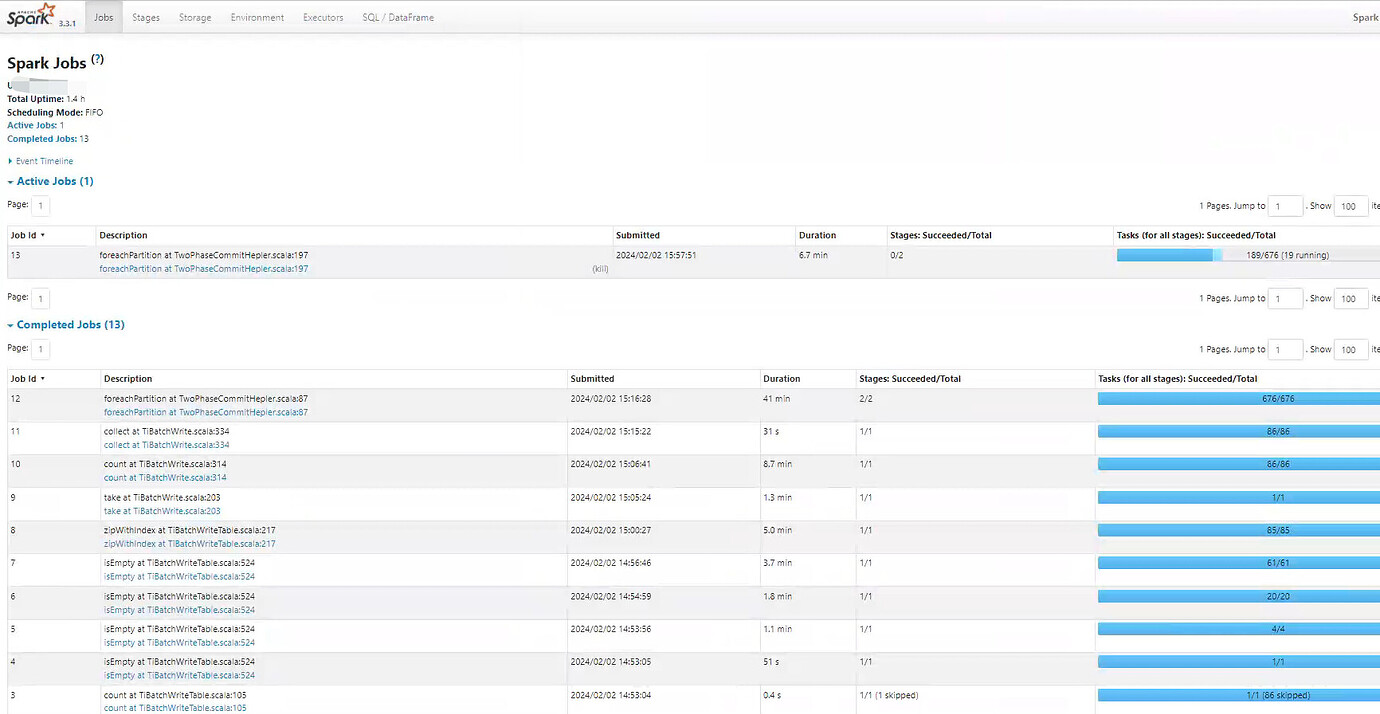
Recently, while using tispark for data writing, I found the speed to be very slow. Has the community evaluated what the normal speed should be, or is there a reference value? It has been over an hour, and the extraction is still not complete. The data source is a tpcds100 sale_stores table with a data volume of 287,997,024 rows. Is there any configuration that needs to be enabled? The speed is indeed far from expected.

Spark submission command
bin/spark-shell --master yarn --executor-cores 2 --executor-memory 6g --num-executors 10
Scala code
df.write.
format("tidb").
option("database", "test").
option("table", "store_sales").
options(tidbOptions).
mode("append").
save()
Finally, an error occurred, but the data was successfully written. The writing speed is approximately 50,000 rows/s.
24/02/02 15:16:28 WARN KVErrorHandler: Stale Epoch encountered for region [{Region[4502900364] ConfVer[34877] Version[65155] Store[402369509] KeyRange[t\200\000\000\000\000\0019E]:[t\200\000\377\377\377\377\377\374_r\200\000\000\000\000\000\351\305]}]
24/02/02 15:16:28 WARN KVErrorHandler: Failed to send notification back to driver since CacheInvalidateCallBack is null in executor node.
13.shade.io.grpc.StatusRuntimeException: UNKNOWN: region 4502900364 is hot
14.shade.io.grpc.StatusRuntimeException: UNKNOWN: region 4502900364 is hot
15.shade.io.grpc.StatusRuntimeException: UNKNOWN: region 4502900364 is hot
24/02/02 15:16:27 WARN TiSession: failed to scatter region: 4502900364
com.pingcap.tikv.exception.GrpcException: retry is exhausted.