Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 同步oracle数据,怎样提升目标端tidb集群写入效率
[TiDB Usage Environment] Poc
The business scenario is to synchronize Oracle database report business data to the TiDB database. Testing shows that a table with 1 million fields takes 50 seconds, with an insertion efficiency of over 20,000/s. However, for tables with slightly more fields, the insertion efficiency is only around 3,000/s, and it decreases as the number of fields increases. The business requirement is that the TiDB side’s write efficiency should be at least 20,000/s.
Measures already taken:
- Optimized most parameters
- Increased memory from 32G to 64G
- Removed TiFlash
However, there has been no significant improvement.
Next steps:
- Deploy a TiDB cluster of version 7.5
- Consider increasing the number of TiKV nodes
Below is the cluster information and hardware configuration:
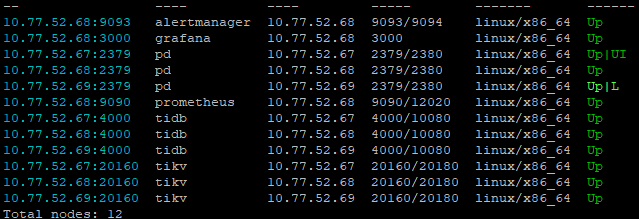
32C 64G 500G HDD and SDD mixed shared storage
Thanks to the community experts for your guidance!
Here is my professional advice:
-
Replace the SSD.
-
The more indexes in TiDB, the slower it gets.
-
If Oracle’s OGG import is slow, it is recommended to use DM or CloudCanal.
May I ask if there is a hotspot written on the PD interface?
After checking the monitoring, there is no obvious write hotspot because it is testing the efficiency of a single table.
Post the IO status of the kv nodes and take a look~
TiDB and TiKV running together can cause CPU contention, but the main issue is that TiDB inserts go through transactions, and the more indexes there are, the more it slows down.
If you synchronize from Oracle, it is monotonically increasing without changing the table structure, which is just single-machine performance. Moreover, TiDB’s performance goes through the network, so it will only be worse than Oracle’s single-machine performance. TiDB uses machine performance to achieve scalability. Its write performance is based on hardware, so it will only be worse than single-machine performance.
Thread CPU
Please also post a screenshot of this monitoring interface.
The image is not visible. Please provide the text content that needs to be translated.
When the number of TiKV instances is greater than the number of replicas, theoretically concurrent writes to TiDB will be better than a single-node Oracle.
Although you said there’s no hotspot, from this graph, I’m not sure if it’s due to the wrong timing or some other reason, but it’s clear that only 67 is actively working, and the IO is not fully utilized.
If 68 and 69 are only at 15-17 during the import period, I think it’s not much different from just observing.
Based on my stress testing experience, using a clustered table requires the table to have a primary key, and then not adding any secondary indexes results in the fastest write performance.
Check the dashboard to see if there are any hotspot tables. I feel like you definitely haven’t optimized the table structure. TiDB 高并发写入场景最佳实践 | PingCAP 文档中心
You can split sections with too many fields.