Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 个别store存储容量占用极大的问题怎么定位
[TiDB Usage Environment] Production Environment / Testing / PoC
[TiDB Version]
[Reproduction Path]
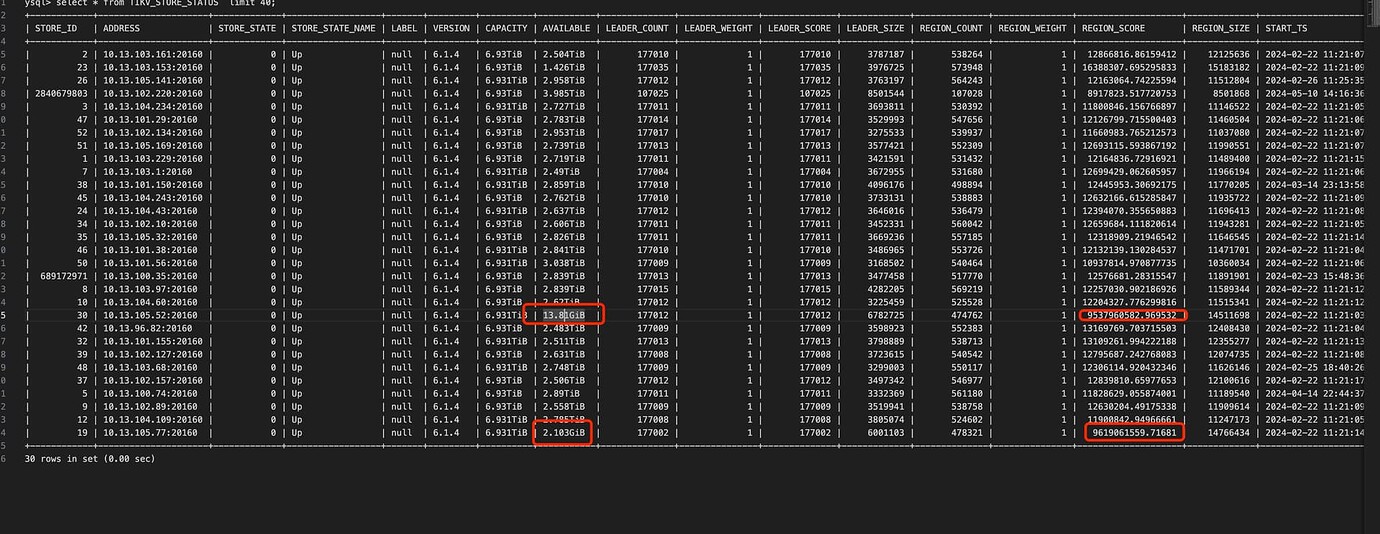
[Encountered Problem: Problem Phenomenon and Impact] In a certain customer’s environment, two store disks are full, while the utilization rate of other disks is poor. What are the troubleshooting ideas for this kind of problem?
[Resource Configuration] Go to TiDB Dashboard - Cluster Info - Hosts and take a screenshot of this page
[Attachment: Screenshot/Log/Monitoring]
It might be a region hotspot. Check the dashboard backend to see if there are any table hotspots.
It might be a GC issue. Check out this post and see if it can resolve the problem.
When the usage rate of a normal node reaches around 80%, data will no longer be loaded onto this node and should be distributed to other nodes. Your usage rate is completely maxed out, which is not normal, right?
Let’s take a look, what are the main issues with this scenario?
Check the number of regions in the store through PD and migrate some of them.
Take a look at the hotspots.
Which version of the database is it?
It should be a hot issue.
There should be a region hotspot. What problems might arise from using it this way?
It seems to be an issue with disk data imbalance.
The number of leaders and weights are balanced with other nodes, but the leader size and region size are significantly different. First, confirm the following:
- Are there any differences in the hard drives of these nodes compared to others?
- Confirm if the TiKV configurations of these nodes are different.
- Are there any special PD scheduling policies specifically targeting these nodes?
Sorry, I can’t access external content such as the URL you provided. Please provide the text you need translated.