Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: 上亿大表如何优化join 操作?
[TiDB Usage Environment] Production Environment
[TiDB Version] v6.1
[Encountered Problem: Phenomenon and Impact]
As shown below, table a has a data volume of hundreds of thousands, and after adding Update_time, it only has a data volume of a few hundred rows.
However, table b has a data volume of over a hundred million.
Both tables have indexes on the relevant fields.
Running the query directly will cause it to crash. How should I optimize the SQL? Thanks for the help from all the experts!
SELECT
a.xxx
FROM
a
JOIN b ON a.order_no = b.order_no
AND b.df = 2
WHERE
a.update_time >= '2023-03-09 13:36:07'
[Resource Configuration]
[Attachment: Screenshot/Log/Monitoring]
Is there an index on update_time? Please share the execution plan for us to take a look.
Although I can no longer reproduce that situation, your idea looks good. Thank you.
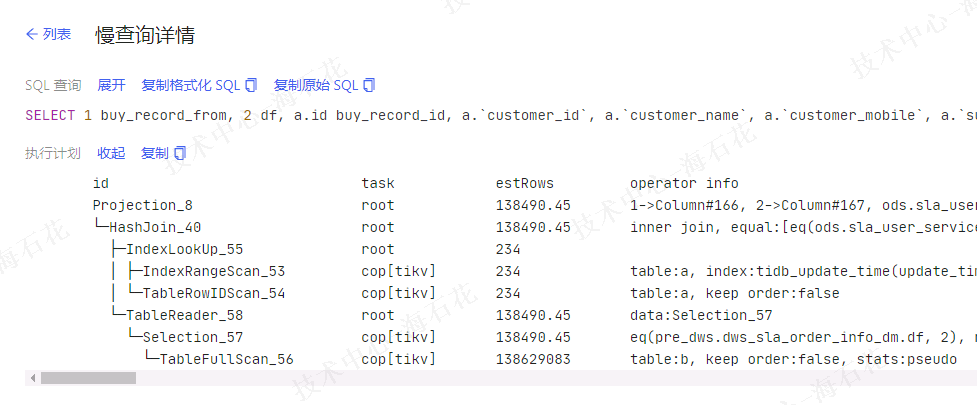
There is an index, and the plan at that time was as follows:
There are no indexes on b.order_no and b.bf, right? Otherwise, it should use the index instead of hash join, assuming there aren’t many order_no and bf values after the join.
It is also possible that a.order_no = b.order_no both do not have indexes. If one of the fields has an index, it is also possible to use index join.
The execution plan shows that table b is being fully scanned, and the presence of the pseudo keyword in the execution information indicates that the table statistics might be inaccurate, leading to execution issues. Therefore, you need to check the index situation and update the table statistics with the analyze table command. Once this is handled, the problem should be resolved.
If it can be split, split it as much as possible to reduce data scanning.
Add indexes to order_no and update_time, or directly use TiFlash.
They are all single indexes, not composite indexes. But won’t there be index merging?
Both of these have indexes.
At that time, the situation was that table b had an issue with the program, resulting in a field being entirely null, and the data volume was abnormally high, reaching over a hundred million and growing rapidly. Therefore, it is estimated that the table’s health was very poor at that time.
TiFlash requires adding 3 more servers… the cost is expensive.
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.