Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.Original topic: 如何优化这个慢查询
[TiDB Usage Environment] Production Environment
[TiDB Version]
[Reproduction Path] What operations were performed to reproduce the issue
SELECT I_ID from table_name FORCE index (IDX_SYNC_STATUS)
WHERE I_SYNC_STATUS = 0 LIMIT 1000;
[Encountered Issue: Problem Phenomenon and Impact]
There are not many records with I_SYNC_STATUS = 0 in the table, a total of more than 1000.
The table has 2.4 billion records, but even with the forced index, why is the query still slow?
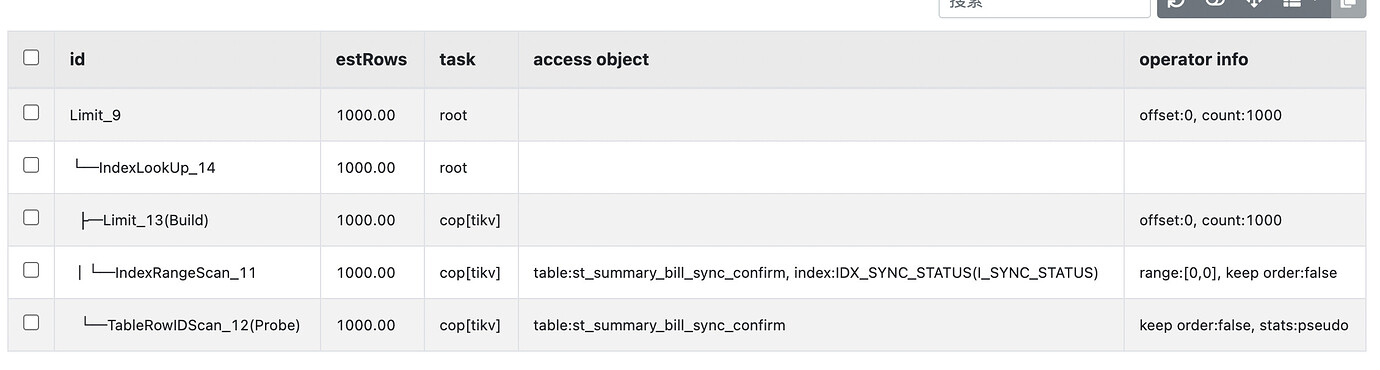
explain analyze sql

CREATE TABLE
st_summary_bill_sync_confirm (I_ID bigint(20) NOT NULL AUTO_INCREMENT COMMENT ‘Auto-increment ID’,I_SUMMARY_ID bigint(20) NOT NULL DEFAULT ‘0’ COMMENT ‘’,I_SUMMARY_TYPE int(11) NOT NULL DEFAULT ‘0’ COMMENT ‘’,I_SYNC_STATUS tinyint(4) NOT NULL DEFAULT ‘0’ COMMENT ‘Sync status: 0 for ready to sync, 1 for syncing, 2 for sync successful, 3 for sync failed, 4 for unprocessed type’,I_SYNC_STATUS_DETAIL int(11) NOT NULL DEFAULT ‘0’ COMMENT ‘Detailed status information’,I_RETRY_COUNT int(11) NOT NULL DEFAULT ‘0’ COMMENT ‘Retry count’,CH_COMMENT varchar(200) NOT NULL DEFAULT ‘’ COMMENT ‘Sync-related comments’,D_CREATED_AT datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘Creation time’,D_UPDATED_AT datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘’,PRIMARY KEY (
I_ID) /*T![clustered_index] CLUSTERED */,UNIQUE KEY
UNIQ_SUMMARY_ID (I_SUMMARY_ID),KEY
IDX_SYNC_STATUS (I_SYNC_STATUS)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin AUTO_INCREMENT=2588993678 COMMENT=‘’
[Resource Configuration]
[Attachments: Screenshots/Logs/Monitoring]