Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: TiKV单节点raftlog损坏如何恢复
[TiDB Usage Environment] Simulating disaster recovery for a single-node TiKV under special circumstances
[TiDB Version] TiKV v6.1.0
[Reproduction Path] Modify the TiKV configuration recovery-mode to “tolerate-any-corruption”, restart TiKV, insert some data into TiKV, stop data insertion, truncate raftlog, restart TiKV, TiKV fails to start
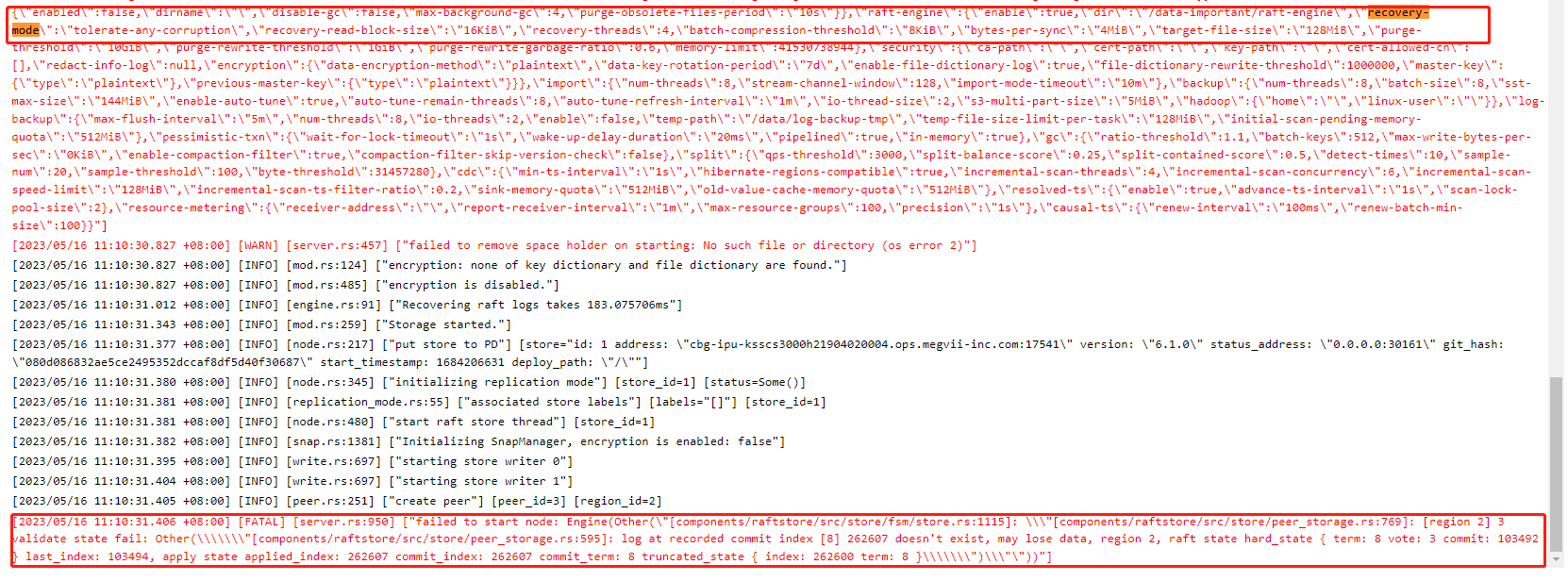
[Encountered Problem: Symptoms and Impact] TiKV fails to restart, error reported: “[FATAL] [server.rs:950] [“failed to start node: Engine(Other(“[components/raftstore/src/store/fsm/store.rs:1115]: "[components/raftstore/src/store/peer_storage.rs:769]: [region 2] 3 validate state fail: Other(\"[components/raftstore/src/store/peer_storage.rs:595]: log at recorded commit index [8] 262607 doesn’t exist, may lose data, region 2, raft state hard_state { term: 8 vote: 3 commit: 103492 } last_index: 103494, apply state applied_index: 262607 commit_index: 262607 commit_term: 8 truncated_state { index: 262600 term: 8 }\")"”))”]”
[Attachment: Screenshot/Log/Monitoring]
Playing like this will lead to self-destruction.
I think this is a common disaster recovery scenario. You must have encountered situations where files were corrupted due to power outages, right?
In this case, I think you can only use the backup files to restore. Directly starting it will definitely result in an error.
How did the original poster solve it? Please share.
I originally thought that setting the TiKV configuration item recovery-mode to “tolerate-any-corruption” would handle this situation, but after several experiments, it still failed. I still don’t know how to deal with it.
Same question: Is there a problem with the default tolerate-tail-corruption?
## Determines how to deal with file corruption during recovery.
##
## Candidates:
## absolute-consistency
## tolerate-tail-corruption
## tolerate-any-corruption
# recovery-mode = "tolerate-tail-corruption"
You can test it yourself; my result is that it doesn’t work.
Okay. Business personnel, please research the log recovery process.
Later self-testing found that the default configuration tolerate-tail-corruption allows the loss of the latest raftlog data up to 512k. tolerate-any-corruption tolerates the loss of 1.5M of data.
If partial data loss is acceptable, you can consider using unsafe recovery. In abnormal situations, it may cause the raft state of the region to be inconsistent. Unsafe recovery can repair the data and restore normal operations; however, it may result in partial data loss. Refer here: Online Unsafe Recovery 使用文档 | PingCAP 归档文档站
A single node losing the raft log is equivalent to deleting some of the WAL logs. Data loss is inevitable. If you want to perform a lossy recovery, check if the unsafe recovery mentioned above works.
This is a manual repair, similar to the Redis command. Additionally, providing a file system repair to recover the raft log is also an option.
This unsafe recover actually removes the unavailable nodes, allowing the remaining nodes to redistribute regions and provide services. It is not applicable in a single-machine scenario.