Note:
This topic has been translated from a Chinese forum by GPT and might contain errors.
Original topic: TiDB触发“critical error”应该怎么排查具体触发的原因?
[TiDB Usage Environment] Production Environment
[TiDB Version] 49
[Reproduction Path] Not reproduced
[Encountered Problem: Problem Phenomenon and Impact]
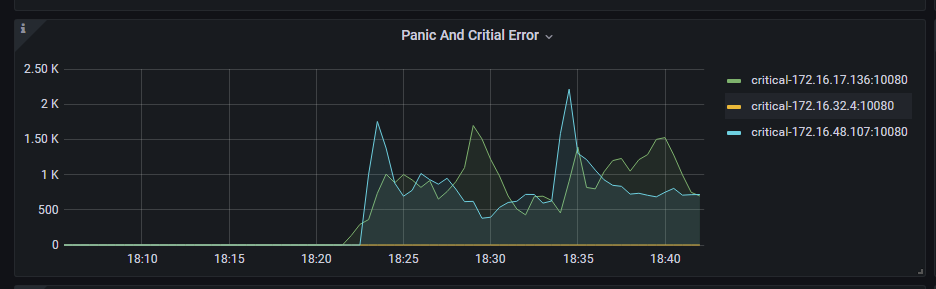
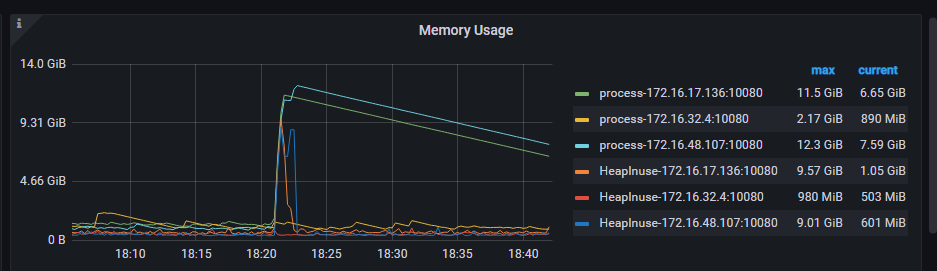
TiDB nodes are configured with ignore-error enabled. There are three TiDB nodes in the cluster, and two nodes triggered critical error alerts, subsequently stopping binlog writing. After reloading the TiDB nodes that failed to write binlog, binlog writing resumed. How can we confirm what operation caused TiDB to fail to write binlog and trigger the critical error?
Reference:
TiDB 集群报警规则 | PingCAP 归档文档站 mentions (currently only the case where Binlog cannot be written). Does this refer to TiDB disk being full, causing failure to write Binlog, or errors occurring when the Drainer node synchronizes to the downstream?
[Resource Configuration]
Online TiDB cluster
[Attachments: Screenshots/Logs/Monitoring]
Check the corresponding tidb.log file for any relevant errors.
The specific logs found are [WARN] level logs indicating binlog write failure:
[2022/11/11 18:22:06.116 +08:00] [INFO] [region_cache.go:839] ["switch region leader to specific leader due to kv return NotLeader"] [regionID=1133841] [currIdx=2] [leaderStoreID=4]
[2022/11/11 18:22:06.635 +08:00] [INFO] [client.go:570] ["[pumps client] write detect binlog to unavailable pump success"] [NodeID=172.16.17.53:8250]
[2022/11/11 18:22:06.636 +08:00] [WARN] [client.go:573] ["[pumps client] write detect binlog to pump failed"] [NodeID=172.16.32.16:8250] [error="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial tcp 172.16.32.16:8250: connect: connection refused\""]
[2022/11/11 18:22:06.636 +08:00] [INFO] [client.go:397] ["[pumps client] set pump available"] [NodeID=172.16.17.53:8250] [available=true]
[2022/11/11 18:22:07.336 +08:00] [INFO] [gc_worker.go:237] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=610a90fcf340091]
So it can be confirmed that it is caused by network issues, right?
It looks like a network issue.
Understood how to troubleshoot and confirm, thanks~
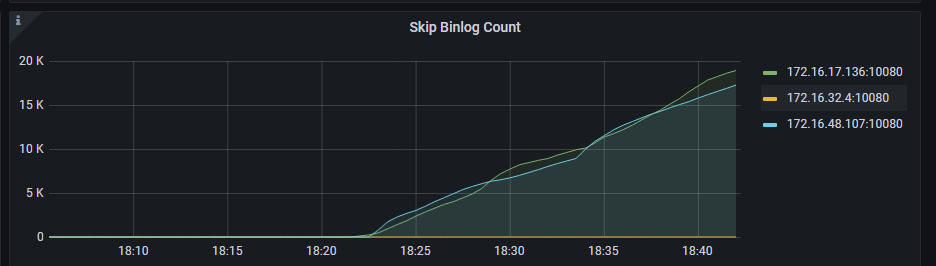
Your skip binlog count is still increasing. You need to address this.
To recover the binlog, use the following command:
curl http://{TiDBIP}:10080/binlog/recover
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.